| |

Hierarchical clustering in data miningHierarchical clustering refers to an unsupervised learning procedure that determines successive clusters based on previously defined clusters. It works via grouping data into a tree of clusters. Hierarchical clustering stats by treating each data points as an individual cluster. The endpoint refers to a different set of clusters, where each cluster is different from the other cluster, and the objects within each cluster are the same as one another. There are two types of hierarchical clustering
Agglomerative hierarchical clusteringAgglomerative clustering is one of the most common types of hierarchical clustering used to group similar objects in clusters. Agglomerative clustering is also known as AGNES (Agglomerative Nesting). In agglomerative clustering, each data point act as an individual cluster and at each step, data objects are grouped in a bottom-up method. Initially, each data object is in its cluster. At each iteration, the clusters are combined with different clusters until one cluster is formed. Agglomerative hierarchical clustering algorithm
Let’s understand this concept with the help of graphical representation using a dendrogram. With the help of given demonstration, we can understand that how the actual algorithm work. Here no calculation has been done below all the proximity among the clusters are assumed. Let's suppose we have six different data points P, Q, R, S, T, V. 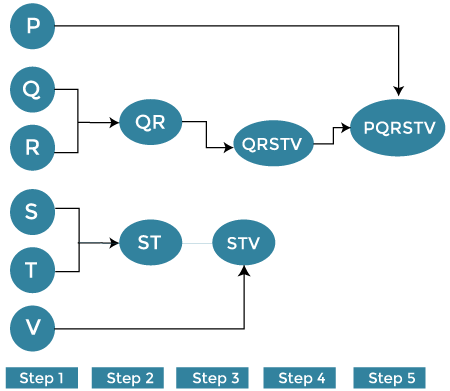
Step 1: Consider each alphabet (P, Q, R, S, T, V) as an individual cluster and find the distance between the individual cluster from all other clusters. Step 2: Now, merge the comparable clusters in a single cluster. Let’s say cluster Q and Cluster R are similar to each other so that we can merge them in the second step. Finally, we get the clusters [ (P), (QR), (ST), (V)] Step 3: Here, we recalculate the proximity as per the algorithm and combine the two closest clusters [(ST), (V)] together to form new clusters as [(P), (QR), (STV)] Step 4: Repeat the same process. The clusters STV and PQ are comparable and combined together to form a new cluster. Now we have [(P), (QQRSTV)]. Step 5: Finally, the remaining two clusters are merged together to form a single cluster [(PQRSTV)] Divisive Hierarchical ClusteringDivisive hierarchical clustering is exactly the opposite of Agglomerative Hierarchical clustering. In Divisive Hierarchical clustering, all the data points are considered an individual cluster, and in every iteration, the data points that are not similar are separated from the cluster. The separated data points are treated as an individual cluster. Finally, we are left with N clusters. 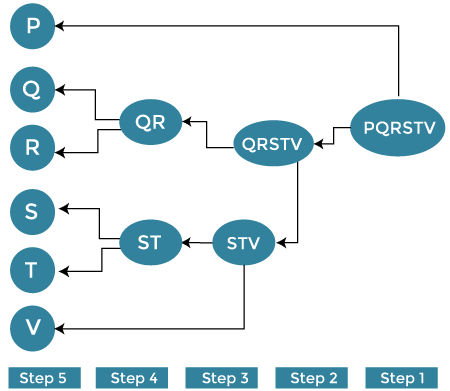
Advantages of Hierarchical clustering
Disadvantages of hierarchical clustering
Next TopicDensity-based clustering in data minin
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








