| |

Data Abstraction in DBMSIn this article, we will explore data abstraction in Database Management Systems (DBMS). 
Let us understand the concept of data abstraction. Data abstraction is the procedure of concealing irrelevant or unwanted data from the end user. Let us understand this with an example, if you go to a shop to buy a pair of shoes, you ask the shopkeeper to show you the shoes of a certain company, and you also tell the shopkeeper about the size, color, and material you want. Then, you will only see the specified things in the shoes, or will you be asking the shopkeeper questions such as, where are these shoes made? From where does the material come? What is the cost of the material? The answer to these questions is NO. You will not ask these questions because these questions are of no use. You do not care about these questions. You are only concerned about a few things, such as the company, size, color, material, and how the shoes look. That is why these unimportant details are kept hidden from the end user. This is the process we call data abstraction. What is Data abstraction in Database Management System?The database system contains intricate data structures and relations. The developers keep away the complex data from the user and remove the complications so that the user can comfortably access data in the database and can only access the data they want, which is done with the help of data abstraction. The main purpose of data abstraction is to hide irrelevant data and provide an abstract view of the data. With the help of data abstraction, developers hide irrelevant data from the user and provide them the relevant data. By doing this, users can access the data without any hassle, and the system will also work efficiently. In DBMS, data abstraction is performed in layers which means there are levels of data abstraction in DBMS that we will further study in this article. Based on these levels, the database management system is designed. Levels of Data Abstractions in DBMSIn DBMS, there are three levels of data abstraction, which are as follows: 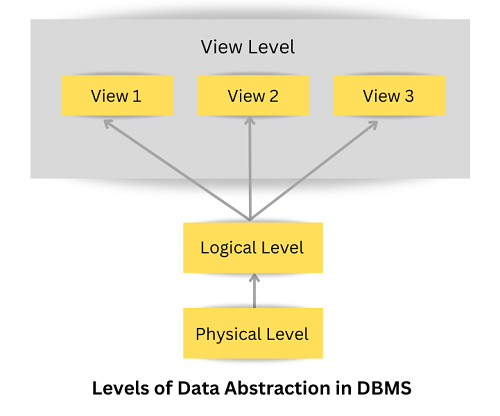
1. Physical or Internal Level:The physical or internal layer is the lowest level of data abstraction in the database management system. It is the layer that defines how data is actually stored in the database. It defines methods to access the data in the database. It defines complex data structures in detail, so it is very complex to understand, which is why it is kept hidden from the end user. Data Administrators (DBA) decide how to arrange data and where to store data. The Data Administrator (DBA) is the person whose role is to manage the data in the database at the physical or internal level. There is a data center that securely stores the raw data in detail on hard drives at this level. 2. Logical or Conceptual Level:The logical or conceptual level is the intermediate or next level of data abstraction. It explains what data is going to be stored in the database and what the relationship is between them. It describes the structure of the entire data in the form of tables. The logical level or conceptual level is less complex than the physical level. With the help of the logical level, Data Administrators (DBA) abstract data from raw data present at the physical level. 3. View or External Level:View or External Level is the highest level of data abstraction. There are different views at this level that define the parts of the overall data of the database. This level is for the end-user interaction; at this level, end users can access the data based on their queries. Advantages of data abstraction in DBMS
Conclusion:
Next TopicDatabase Applications
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








