| |

Heap file organization
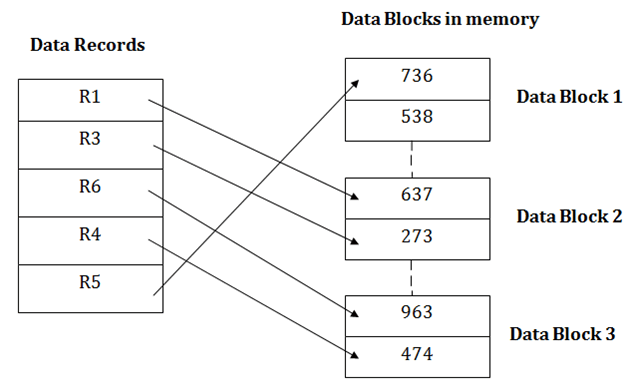
Insertion of a new recordSuppose we have five records R1, R3, R6, R4 and R5 in a heap and suppose we want to insert a new record R2 in a heap. If the data block 3 is full then it will be inserted in any of the database selected by the DBMS, let's say data block 1. 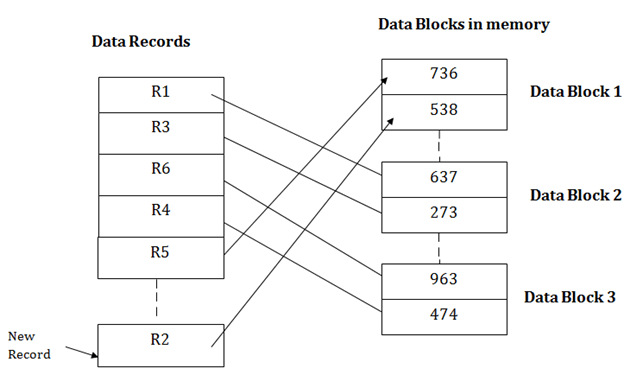
If we want to search, update or delete the data in heap file organization, then we need to traverse the data from staring of the file till we get the requested record. If the database is very large then searching, updating or deleting of record will be time-consuming because there is no sorting or ordering of records. In the heap file organization, we need to check all the data until we get the requested record. Pros of Heap file organization
Cons of Heap file organization
Next TopicHash file organization
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share



Like/Subscribe us for latest updates or newsletter 




