| |

Recovery and Atomicity in DBMSIntroductionData may be monitored, stored, and changed rapidly and effectively using a DBMS (Database Management System).A database possesses atomicity, consistency, isolation, and durability qualities. The ability of a system to preserve data and changes made to data defines its durability. A database could fail for any of the following reasons:
The recovery procedures in DBMS ensure the database's atomicity and durability. If a system crashes in the middle of a transaction and all of its data is lost, it is not regarded as durable. If just a portion of the data is updated during the transaction, it is not considered atomic. Data recovery procedures in DBMS make sure that the data is always recoverable to protect the durability property and that its state is retained to protect the atomic property. The procedures listed below are used to recover data from a DBMS,
The atomicity attribute of DBMS safeguards the data state. If a data modification is performed, the operation must be completed entirely, or the data's state must be maintained as if the manipulation never occurred. This characteristic may be impacted by DBMS failure brought on by transactions, but DBMS recovery methods will protect it. What exactly is a Log-Based Recovery?Every DBMS has its own system logs, which record every system activity and include timestamps for the event's timing. Databases manage several log files for operations such as errors, queries, and other database updates. The log is saved in the following file formats:
We may utilize these logs to see how the state of the data changes during a transaction and recover it to the prior or new state. An undo operation can be used to inspect the [write item, T, X, old value, new value] operation and restore the data state to old data. The only way to restore the previous state of data to the new state that was lost due to a system failure is to do the [commit, T] action. Consider the following series of transactions: t1, t2, t3, and t4. The system crashes after the fourth transaction; however, the data can still be retrieved to the state it was in before the checkpoint was established during transaction t1. After all of the records of a transaction are written to logs, a checkpoint is created to transfer all of the logs from local storage to permanent storage for future usage. What is the Conceded Update Method?Until the transaction enters its final stage or during the commit operation, the data is not changed using the conceded update mechanism. Following this procedure, the data is updated and permanently placed in the main memory. In the event of a failure, the logs, which are preserved throughout the process, are utilized to identify the fault's precise moment. We benefit from this because even if the system crashes before the commit step, the database's data is not altered, and the status is managed. If the system fails after the commit stage, we may quickly redo the changes to the new stage, as opposed to the undo procedure. Many databases configure logging automatically, but we can also configure them manually. To configure logging into a MySQL database, perform the following steps in the MySQL terminal.
What does the Quick Update Method Entail?In the quick update strategy, the data is updated concurrently before the transaction reaches the commit stage. The logs are also recorded as soon as the data is changed. Data recovery activities can be carried out if the transaction fails and the data is in a partial state. We can also use SQL instructions to mark the transaction's status and recover our data to that state. To accomplish this, run the following commands:
What is the Distinction between a Deferred and an Immediate Update?Database recovery methods used in DBMS to preserve the transaction log files include deferred updates and rapid updates. With a deferred update, the database's state of the data is not altered right away once a transaction is completed; instead, the changes are recorded in the log file, and the database's state is updated as soon as the commit is complete. The database is directly updated at every transaction in the immediate update, and a log file detailing the old and new values is also preserved.
Backup TechniquesA backup is a copy of the database's current state that is kept in another location. This backup is beneficial in the event that the system is destroyed due to natural disasters or physical harm. The database can be restored to the state it was in at the time of the backup using these backups. Many backup techniques are used, including the following ones:
What are Transaction Logs?Transaction logs are used to maintain track of all transactions that have updated the data in the database. The methods below are taken to recover data from transaction logs. The recovery manager scans through all log files for transactions with a start transaction stage but no commit stage. The above-mentioned transactions are rolled back to the previous state using the rollback command and the logs. Transactions with a commit command have made modifications to the database, which are logged in the logs. These modifications will also be undone using the undo function. What is Shadow Paging?
In the logical memory of the Caching/Buffering method is a collection of buffers known as DBMS buffers. Throughout the process, all logs are kept in buffers, and the main log file is updated once the transaction reaches the commit stage. Atomicity: A set of ideas used to ensure the integrity of database transactions is known as the ACID model, which stands for Atomicity, Consistency, Isolation, and Durability in database management systems. Atomicity is achieved mostly by complex processes such as journaling or logging or through operating-system calls. In a database management system, an atomic transaction is defined as an indivisible and irreducible series of database actions in which either everything or nothing happens. A guarantee of atomicity prevents incomplete database alterations, which might cause more problems than simply rejecting the entire series. No other database client is able to view the transaction as a result. At one moment in time, it hasn't happened yet, yet it has entirely happened at another (or no changes happen if the transaction was cancelled in progress). Atomicity Examples: We've already examined what atomicity means in relational databases. Let's look at some examples to better comprehend the idea of atomicity. Example1: Atomicity in Online Ticket Booking Systems: Using an online ticket booking system as an example, a booking may consist of two separate acts that combine to form a transaction: the first is the payment for the ticket, and the second is to reserve the seat for the person who just paid. According to business logic, these two distinct and separate actions must occur concurrently. If one develops without the other, problems may arise. The system might reserve the same seat for two separate consumers, for instance. Example 2: Transactions that occur in a bank (Credit or Debit of Money). If Marino has a $50 account named A and wants to pay $20 to Amanda, who has a $50 account named B. A balance of $200 already exists in account B. When you deposit $20 into account B, the total is $220. Two procedures have now been arranged. The first is that the $20 Marino desires to send will be debited from his account A and credited to account B, i.e., Amanda's account. The initial debit transaction succeeds, but the subsequent crediting process fails. As a result, the value of Marino's account A drops to $30 while Amanda's account's worth stays the same at $200. 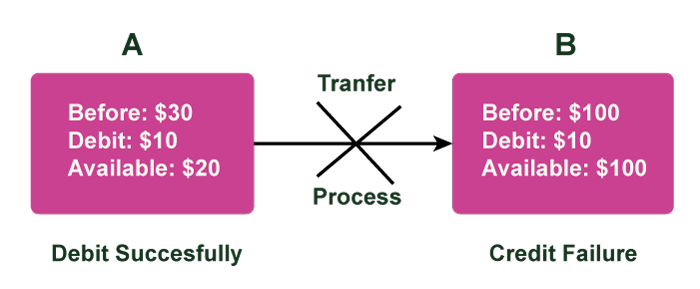
This is not an atomic transaction as a result. As a result, the value of Marino's account A drops to $30 while Amanda's account's worth stays the same at $200. Conclusion:
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








