| |

Types of Sources of Data in Data Mining in DBMSData from several sources is combined into a single source called a "data warehouse." Let's talk about the kinds of data that can be mined: Flat File
In conclusion, flat files are a straightforward and effective method for transferring and storing small to medium-sized data sets, but they are unsuitable for handling enormous amount of data or intricate data connections. Data MiningData mining is the process of taking information out of massive data sets to find patterns, trends, and relevant data that would enable the organisation to make data-driven decisions. To put it another way, data mining is the process of examining information's hidden patterns from various angles for categorization into useful data. This data is gathered and assembled in specific areas like data warehouses, efficient analysis, and data mining algorithms, which aid in decision-making and other data requirements and, ultimately, reduce costs and generate income. The process of automatically searching through massive informational repositories to discover patterns and trends that go beyond straightforward research techniques is known as data mining. Data mining assesses the likelihood of events using sophisticated mathematical algorithms for data segments. Another name for data mining is knowledge discovery from data (KDD). Organizations employ the data mining method to extract certain data from sizable databases in order to address business issues. It mostly transforms unprocessed data into insightful knowledge. Data mining is comparable to data science in that it is performed by a person, in a particular setting, with a specific data set, and with a specified goal. Many services, including text mining, web mining, audio and video mining, picture data mining, and social media mining, are all part of this process. Simple or specialized software is used to carry it out. Data mining may be outsourced to get the job done quickly and cheaply. New technology can also be used by specialized businesses to gather data that is hard to find manually. There is a ton of information on many different platforms, but not much of it is accessible. The largest hurdle is analyzing the data to draw out crucial information that can be applied to problem-solving or business development. To mine data and gain more insight from it, a variety of potent tools and approaches are available. 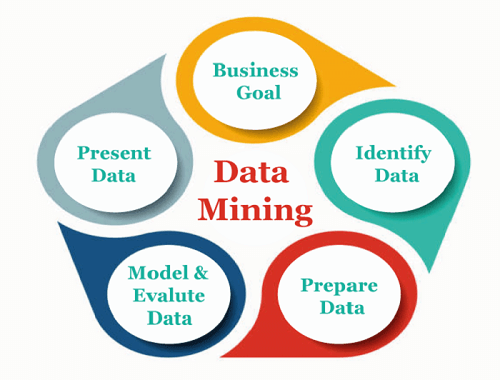
Relational Database
Data WarehouseThe technology that gathers data from many organizational sources to offer useful business insights is known as a data warehouse. The enormous volume of data is gathered from several sources, including marketing and finance. The retrieved data is used for analytical reasons and aids in business organization decision-making. The data warehouse's primary purpose is data analysis, not transaction processing. Data RepositoryA location for data storage is often referred to as the Data Repository. Yet, a lot of IT experts use the phrase more specifically to refer to a certain arrangement within an IT organization. A collection of database for instance where a company has stored numerous types of information. Object-Relational DatabaseAn object-relational model combines a relational database model with an object-oriented database model. It supports objects, inheritance, classes, etc. Closing the gap between relational databases and the methods often used in various programming languages, such as C++, Java, C#, and others, is one of the main goals of the object-relational data model. Transactional DatabaseA database management system (DBMS) that has the ability to reverse a database transaction if it is not executed properly is referred to as a transactional database. The majority of relational database systems currently enable transactional database operations, despite the fact that this was once a unique function. Benefits of data mining
Data mining's drawbacks
Data Mining ProgramsRetail, communication, financial, and marketing companies are the main users of data mining to ascertain prices, consumer preferences, product placement, and effects on sales, client satisfaction, and business profitability. Using point-of-sale records of client purchases, data mining helps a retailer to create items and promotions that aid in luring customers to the business. 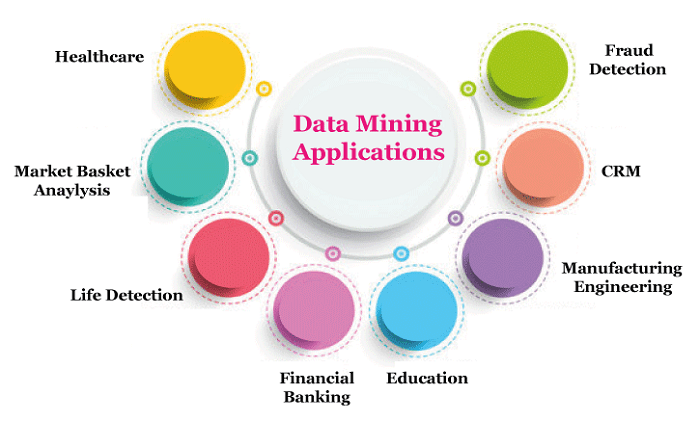
Data mining is extensively utilized in the following fields: Healthcare Data MiningThe potential for data mining in healthcare to enhance the healthcare system is quite high. It makes use of data and analytics to gain greater understanding, discover best practices, and improve health care services while lowering costs. Data mining techniques including machine learning, multi-dimensional databases, data visualization, soft computing, and statistics are used by analysts. Using data mining to analyze market basketsA modeling technique based on a hypothesis is market basket analysis. You are more likely to purchase another group of goods if you purchase one set of goods. The shop may be able to comprehend a customer's purchasing habits using this strategy. The merchant may use this information to better understand customer needs and adjust the layout of the store as necessary. It is possible to compare client data from numerous businesses and from various demographic groups using different analytical techniques. Education and Data MiningIn a recently developed discipline called "education data mining," strategies are being developed to discover information from data produced by educational environments. The accepted EDM aims include fostering learning science, researching the effects of educational assistance, and confirming students' future learning behaviors. A company may utilize data mining to make accurate judgments and forecast student performance. The institution may focus on what to educate and how to teach once it has the results. Manufacturing engineering and data miningThe finest resource a manufacturing organization has is knowledge. Finding trends in a complicated manufacturing process can be helped by data mining techniques. To determine the connections between product architecture, product portfolio, and customer data demands, data mining may be employed in system-level design. Among other things, it may be used to predict the time, cost, and expectations for product development. CRM (Customer Relationship Management) Data MiningCustomer relationship management (CRM) focuses on attracting and retaining customers while also fostering customer loyalty and putting forward consumer-focused tactics. Data collection and analysis are necessary for a corporate organization to have a good relationship with the consumer. The gathered data may be utilized for analytics with data mining methods. Using data mining to identify fraudFrauds cause billions of dollars in losses. Conventional fraud detection techniques are quite complex and time-consuming. Data mining offers insightful patterns and transforms data into knowledge. The data of all users should be protected by a fraud detection system. The records used in supervised algorithms are samples that have been categorized as fake or non-fraudulent. This information is used to build a model, and a method is developed to determine whether or not the document is false. Relational databases provide a number of benefits:
How Data mining works?Data mining is the process of examining and analyzing huge chunks of data to discover significant patterns and trends. Many applications exist for it, including database marketing, credit risk management, fraud detection, spam email screening, and even user sentiment analysis. There are five steps in the data mining process. Data is first gathered by organizations and loaded into data warehouses. The data is then kept and managed, either on internal servers or on the cloud. The data is accessed by business analysts, management groups, and information technology specialists, who then decide how to arrange it. The data is next sorted by application software in accordance with the user's findings, and ultimately, the end user delivers the data in an accessible format. Relational databases have certain drawbacks such as:
Data Warehouse
Databases for transactions
Multimedia Database
Database for Space
Database of Time Series
WWW
Structured Data: Data that has been structured often takes the form of a database table or spreadsheet. Data on transactions, clients, and inventories are a few examples. Semi-Structured Data: Compared to structured data, this sort of data has less structure yet still contains some. Email communications and XML and JSON files are two examples. Unstructured data: can be in the form of text, photos, audio, and video and does not have a set format. Customer reviews, news stories, and social media posts are a few examples. External Data: This kind of information is gathered from outside sources like governmental organizations, business publications, weather reports, satellite photos, GPS data, etc. Time-series Data: That is collected over time in a series, such as stock prices, weather information, and website visitor logs. Streaming Data: That is continually produced, such as sensor data, social media feeds, and log files, is referred to as streaming data. Relational Data: SQL queries may be used to retrieve this sort of data, which is kept in a relational database. NoSQL Data: This kind of information is kept in a NoSQL database and may be accessed in a number of ways, including key-value pairs, documents, columns, and graphs. Cloud Data: That is processed and stored in cloud computing environments, such as Amazon, Azure, and GCP, is referred to as cloud data. Big Data: This form of data may be stored and analyzed using big data technologies like Hadoop and Spark. It is distinguished by its enormous volume, high velocity, and great diversity. Implementation Issues with Data MiningDespite its immense capacity, data mining confronts several difficulties when used. Performance, data, methods, techniques, etc. could all present problems. When the difficulties or issues are accurately identified and suitably addressed, the data mining process becomes effective. Noisy and incomplete dataData mining is the process of extracting usable information from huge amounts of data. Real-world data is varied, insufficient, and noisy. Large amounts of data are typically erroneous or untrustworthy. These issues might be brought on by inaccurate data measuring equipment or by human mistake. Consider a shop chain where the accounting staff enters the phone numbers of consumers who spend more than $500 into the system. By inputting the phone number, the individual could misspell a digit, resulting in inaccurate information. Even some clients might not be eager to provide their phone numbers, resulting in inaccurate data. Both human and system mistake have the potential to modify the data. Data mining is difficult because of all these implications (noisy and inadequate data). Distribution of DataData from the real world is often kept on a variety of platforms in a distributed computing system. It could be on the internet, in a database, or even on different platforms. Realistically speaking, it is a difficult process to consolidate all the data into a single repository, largely because of organizational and technical issues. For instance, several regional offices could each have their own servers for storing data. The storage of all the data from every office on a single server is not practical. The creation of tools and algorithms that enable the mining of dispersed data is thus necessary for data mining. Intricate DataReal-world data is diverse and might include time series, complicated data, geographical data, audio and video, photographs, and multimedia data. To get precise information, new technology, tools, and processes would often need to be improved. PerformanceThe effectiveness of the employed algorithms and methodologies heavily influences the performance of the data mining system. The effectiveness of the data mining process will suffer if the designed algorithm and approaches do not meet expectations. Data security and privacyIn most cases, data mining causes significant problems with data governance, privacy, and security. For instance, if a merchant examines the specifics of the things consumers have purchased, without the customers' consent, it discloses information about their purchasing preferences and patterns. Visualizing dataData visualization is a crucial step in the data mining process since it is the main tool used to deliver the output to the user. The extracted data must communicate exactly what it is trying to say. Yet, it is sometimes challenging to convey the information to the end-user in a clear and simple manner. It requires the implementation of complex, highly effective, and successful data visualization procedures given the input and output information.
Next TopicWhy is recovery needed in DBMS
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








