| |

Cluster file organization
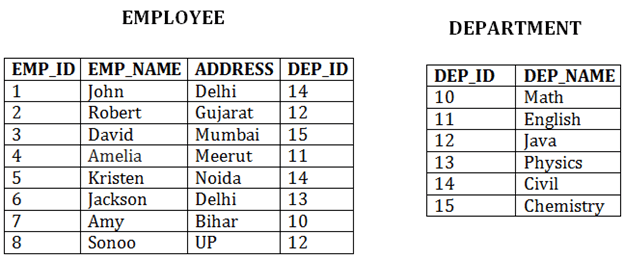
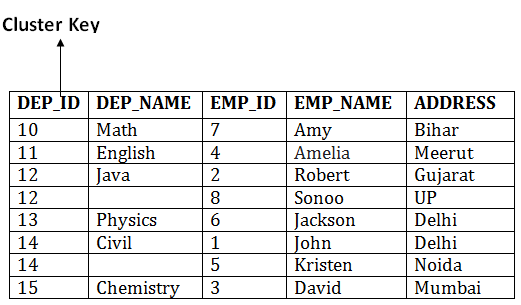
In this method, we can directly insert, update or delete any record. Data is sorted based on the key with which searching is done. Cluster key is a type of key with which joining of the table is performed. Types of Cluster file organization:Cluster file organization is of two types: 1. Indexed Clusters:In indexed cluster, records are grouped based on the cluster key and stored together. The above EMPLOYEE and DEPARTMENT relationship is an example of an indexed cluster. Here, all the records are grouped based on the cluster key- DEP_ID and all the records are grouped. 2. Hash Clusters:It is similar to the indexed cluster. In hash cluster, instead of storing the records based on the cluster key, we generate the value of the hash key for the cluster key and store the records with the same hash key value. Pros of Cluster file organization
Cons of Cluster file organization
Next TopicIndexing in DBMS
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share



Like/Subscribe us for latest updates or newsletter 




