| |

COMMIT Protocol in DBMSDistributed commit protocol basics of transactions and transactions states are discussed in this article in detail. Let us start the discussion by understanding the transactions and transaction states: What is a Transaction?We may have a partially executed program since the level of atomicity is an instruction, meaning that either an instruction is performed completely or not, according to generic computation theory (operating system). However, from the perspective of a database management system (DBMS), a user performs a logical task (operation) that is always atomic in nature, meaning that there is no such thing as partial execution. Let us assume that we have to transfer 10000 rupees from the bank account of X to Y. The following instructions are needed to complete the following task:
The system's ultimate state will be inconsistent if a failure occurs after executing the third instruction, as 10000 rupees will be deducted from X's account but will not be credited to Y's account. For a system to be consistent, here, X + Y == X' + Y'. We raise the level of atomicity and group all the instructions for a logical operation into a unit referred to as a transaction in order to solve this partial execution problem. Therefore, a transaction is officially defined as "A Set of Logically Related Instructions to Perform a Logical Unit of Work." TRANSACTION STATESThere is a total of five states a transaction can acquire once at a time:
Now let us start with our main agenda. DISTRIBUTED DBMS - COMMIT PROTOCOLSThe transaction manager in a local database system just needs to inform the recovery manager of their choice to commit a transaction. However, in a distributed system, the transaction manager should consistently enforce the decision to commit and communicate it to all the servers in the various sites where the transaction is being conducted. Each site's processing ends when it reaches the partially committed transaction state, where it waits for all other transactions to get their partially committed states. Once it receives the signal that all the sites are prepared, it begins to commit. Either every site commits in a distributed system, or none of them does. To guarantee atomicity, the execution's ultimate result must be accepted by every site where transaction T was executed. T must either commit at every location or abort at every location. The transaction coordinator of T must carry out a commit protocol in order to guarantee this property. There is a total of three different Distributed DBMS Commit Protocols:
1. One-Phase CommitThe distributed one-phase commit is the most straightforward commit protocol. Consider the scenario where the transaction is being carried out at a controlling site and several slave sites. These are the steps followed in the one-phase distributed commit protocol:
2. Two-Phase CommitThe two-phase commit protocol (2PC), which is explained in this Section, is one of the most straightforward and popular commit methods. The vulnerability of one-phase commit methods is decreased by distributed two-phase commit. The following actions are taken in the two phases: Considering a transaction T that proceeds at site Si and is coordinated by the transaction coordinator Ci. When T has completed, or when all the sites where T has run notify Ci that T has accomplished, Ci initiates the 2PC protocol. Phase 1 - Obtaining a Decision
Phase 2 - Recording the Decision
Before sending the message ready T to the coordinator, a site where T was executed has the ability to unconditionally abort T at any point. Upon sending the message, the transaction is considered to be in the "ready state" at the destination. A site's pledge to carry out the coordinator's instructions to commit T or abort T is essentially expressed in the ready T message. The necessary data must first be kept in stable storage before such a commitment can be made. Otherwise, it might not be able to deliver on its promise if the site goes down after transmitting ready T. Furthermore, until the transaction is finished, any locks that were acquired as part of the transaction must be kept. The fate of T is decided as soon as at least one site answers with an abort T because an agreement is needed to commit a transaction. Because Si at the coordinator site is one of the sites where T was conducted, the coordinator has the authority to unilaterally decide to terminate T. The coordinator's writing of the decision (commit or abort) to the log and force of it into stable storage constitutes the final determination of the decision involving T. In some 2PC protocol implementations, a site notifies the coordinator with an "acknowledge T" message at the conclusion of the second phase. The coordinator adds the record "complete T" to the log when it receives the "acknowledge T" messages from all of the sites. HANDLING OF ERRORS:The 2PC protocol reacts differently to various failure types: A. Failure of a participating site - When a site fails, the coordinator Ci does the following things: The coordinator considers that the site responded to Ci with an abort T message if it fails before sending a ready T message. After receiving the ready T message from the site, if the site fails, the coordinator continues to carry out the rest of the commit protocol, as usual, oblivious to the site's failure. Once a participating site Sk has recovered from a failure, it must review its log to see what happened to the transactions that were still being processed at the time of the failure. Assume that T is one such transaction. We examine each of the following scenarios:
B. Failure of the Coordinator - The participating sites must decide what happens to transaction T if the coordinator fails during the execution of the commit protocol for T. We'll see that there are times when the participating sites are unable to decide whether to commit or abort T. As a result, these sites are forced to wait for the failed coordinator to recover successfully.
Blocking Problem - For example, if locking is employed, T might hold locks on data at active sites. A condition like this is undesirable because it can take hours or days for Ci to become active once more. Other transactions might need to wait for T at this period. Therefore, data items might not just be unavailable on the failed site (Ci) but also on live sites. Because T is blocked while waiting for site Ci to recover, this circumstance is known as the "blocking< problem." C. Network Partitioning - There are two outcomes when a network partitions:
Therefore, the main drawback of the 2PC protocol is that coordinator failure may lead to blocking, in which case a choice between committing to or aborting T may need to be delayed until Ci recovers. Recovery and Concurrency ControlWe can undertake recovery when a failed site resumes, for instance, by employing the recovery strategy. In-doubt transactions, which are defined as transactions for which a ready T> log record is found but neither a commit T> log record nor an abort T> log record is found, must be treated differently by the recovery procedure in order to deal with distributed commit protocols. The recovered site must contact other sites, as stated in the section Handling of Errors, to learn the commit-abort status of such transactions. However, normal transaction processing at the site cannot start if recovery is carried out, as just stated, until all in-doubt transactions have been committed or rolled back. It may take some time to determine the status of transactions that are in doubt because several sites may need to be contacted. Additionally, if 2PC is employed and the coordinator fails, and no other site has knowledge of the commit-abort state of an incomplete transaction, recovery may become blocked. As a result, the website performing restart recovery can be unavailable for a considerable amount of time. 3. Three-Phase CommitThe two-phase commit protocol can be extended to overcome the blocking issue using the three-phase commit (3PC) protocol, under particular assumptions. It is specifically anticipated that there will be no network partitions and that there won't be any more than k sites that fail, where k is a preset number. Under these presumptions, the protocol prevents blocking by adding a third phase that involves several sites in the commit decision. The coordinator initially makes certain that at least k other sites are aware that it planned to commit the transaction before immediately documenting the decision to commit in its persistent storage. In the event that the coordinator fails, the surviving sites initially choose a replacement. The protocol's status is checked by the new coordinator from the remaining locations; I If the coordinator had made the decision to commit, at minimum one of the other K sites it had notified would be online and would make sure the commit decision was upheld. If some site understood that the previous coordinator intended to complete the transaction, the new coordinator starts over with the third phase of the procedure. Otherwise, the transaction is aborted by the new coordinator. 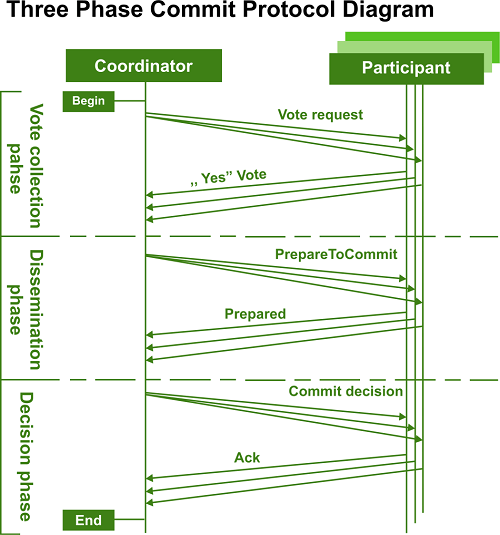
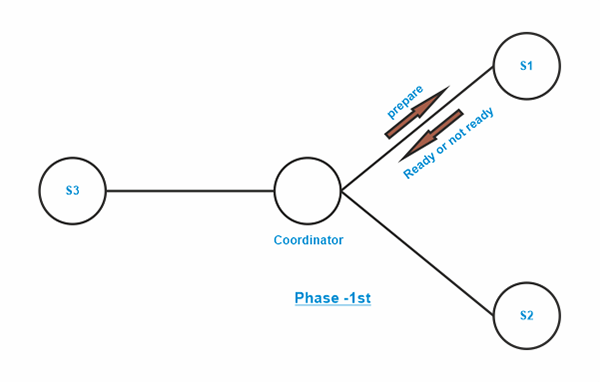
The 3PC protocol has the advantage of not blocking until k sites fail, but it also has the disadvantage that a network partitioning might be mistaken for more than k sites failing, which would result in blocking. In addition, the protocol must be properly developed to prevent inconsistent results, such as transactions being committed in one partition but aborted in another, in the event of network partitioning (or more than k sites failing). The 3PC protocol is not frequently utilized due of its overhead. The three phases of the distributed three-phase commit protocol are as follows: Phase one - Obtaining Preliminary Decision
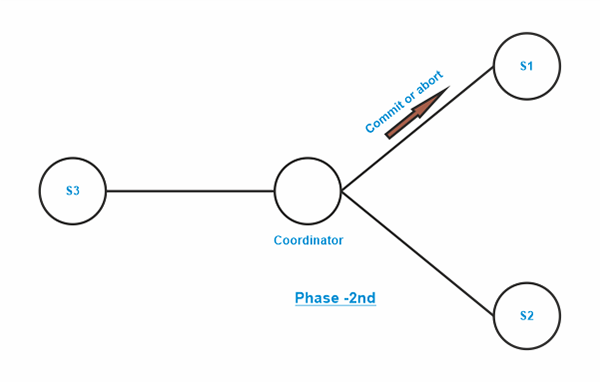
Phase 2 of 2PC is divided into Phase Two and Phase Three in 3PC. Phase Two - Phase 2 involves the coordinator making a choice similar to the 2PC (known as the pre-commit decision) and documenting it in several (at least K). Phase Three - Phase 3 involves the coordinator notifying all participating sites whether to commit or abort. Under 3PC, despite the coordinator's failure, a choice can be committed using knowledge of pre-commit decisions. prevents blocking issues as long as < K sites are inoperative.
Next TopicAnomalies in DBMS
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








