| |

|
|
|
Top 25 Data Science Interview Questions
A list of frequently asked Data Science Interview Questions and Answers are given below. 1) What do you understand by the term Data Science?
2) What are the differences between Data Science, Machine Learning, and Artificial intelligence?Data science, Machine learning, and Artificial Intelligence are the three related and most confusing concepts of computer science. Below diagram is showing the relation between AI, ML, and Data Science. 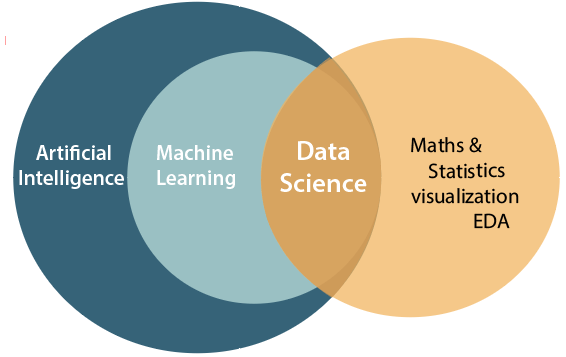
Following are some main points to differentiate between these three terms:
3) Discuss Linear Regression?
If we talk about simple linear regression algorithm, then it shows a linear relationship between the variables, which can be understood using the below equation, and graph plot. 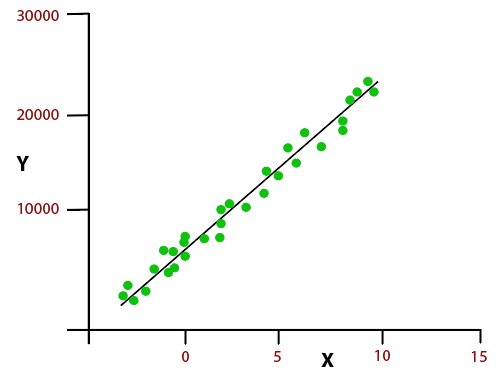
4) Differentiate between Supervised and Unsupervised Learning?Supervised and Unsupervised learning are types of Machine learning. Supervised Learning: Supervised learning is based on the supervision concept. In supervised learning, we train our machine learning model using sample data, and on the basis of that training data, the model predicts the output. Unsupervised learning: Unsupervised learning does not have any supervision concept. Hence, in unsupervised learning machine learns without any supervision. In unsupervised learning, we provide data which is not labeled, classified, or categorized. Below are some main differences between supervised and unsupervised learning:
5) What do you understand by bias, variance trade-off?When we work with a supervised machine learning algorithm, the model learns from the training data. The model always tries to best estimate the mapping function between the output variable(Y) and the input variable(X). The estimation for target function may generate the prediction error, which can be divided mainly into Bias error, and Variance error. These errors can be explained as:
Bias Variance tradeoff: In the machine learning model, we always try to have low bias and low variance, and
Hence, trying to get an optimal bias and variance is called bias-variance trade-off. We can define it using the Bull eye diagram given below. There are four cases of bias and variances: 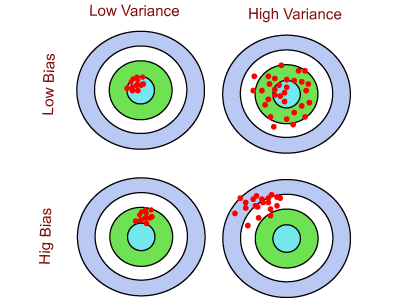
6) Define Naive Bayes?Naive Bayes is a popular classification algorithm used for predictive modeling. It is a supervised machine learning algorithm which is based on Bayes theorem. It is easy to build a model using Naive Bayes algorithm when working with a large dataset. It is comprised of two words, Naive and Bayes, where Naive means features are unrelated to each other. In simple words, we can say that "Naive Bayes classifier assumes that the features present in a class are statistically independent to the other features." 7) What is the SVM algorithm?SVM stands for Support Vector Machine. It is a supervised machine learning algorithm which is used for classification and regression analysis. It works with labeled data as it is a part of supervised learning. The goal of support vector machine algorithm is to construct a hyperplane in an N-dimensional space. The hyperplane is a dividing line which distinct the objects of two different classes, it is also known as a decision boundary. If there are only two distinct classes, then it is called as Binary SVM classifier. A schematic example of binary SVM classifier is given below. 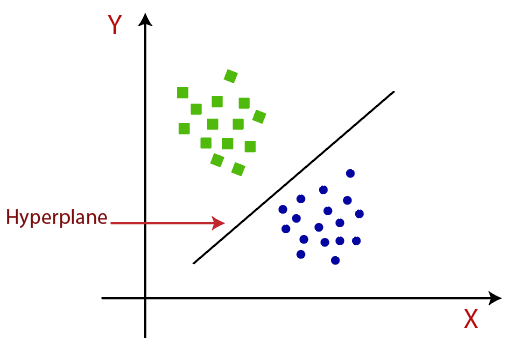
The data point of a class which is nearest to the other class is called a support vector. There are two types of SVM classifier:
On the basis of error function, we can divide a SVM model into four categories:
8) What do you understand by Normal distribution?
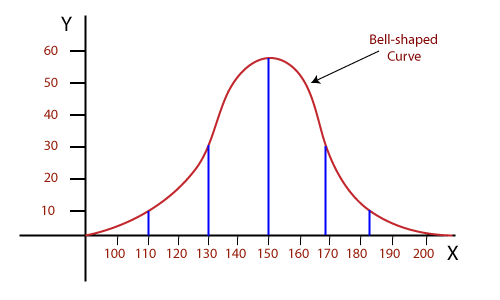
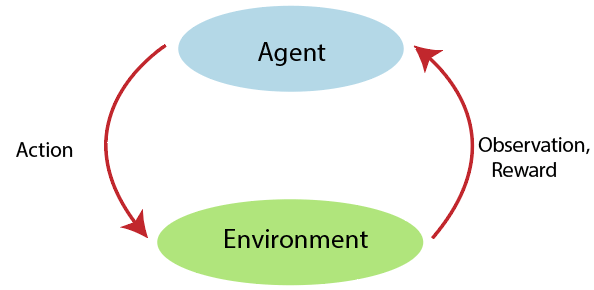
9) Explain Reinforcement learning.
10) What do you mean by p-value?
11) Differentiate between Regression and Classification algorithms?Classification and Regression both are the supervised learning algorithms in machine learning, and uses the same concept of training datasets for making predictions. The main difference between both the algorithms is that the output variable in regression algorithms is Numerical or continuous, whereas in Classification algorithm output variables are Categorical or discrete. Regression Algorithm: A regression algorithm is about mapping the input variable x to some real numbers such as percentage, age, etc. Or we can say regression algorithms are used if the required output is continuous. Linear regression is a famous example of the regression algorithm. Regression Algorithms are used in weather forecasting, population growth prediction, market forecasting, etc. Classification Algorithm: A classification algorithm is about mapping the input variable x with a discrete number of labels such as true or false, yes or no, male-female, etc. Or we can say Classification algorithm is used if the required output is a discrete label. Logistic regression and decision trees are popular examples of a classification algorithm. The classification algorithm is used for image classification, spam detection, identity fraud detection, etc. 12) Which is the best suitable language among Python and R for text analytics?Both R and Python are the suitable language for text analytics, but the preferred language is Python, because:
13) What do you understand by L1 and L2 regularization methods?Regularization is a technique to reduce the complexity of the model. It helps to solve the over-fitting problem in a model when we have a large number of features in a dataset. Regularization controls the model complexity by adding a penalty term to the objective function. There are two main regularization methods: L1 Regularization:
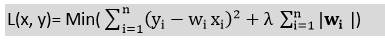
L2 Regularization:
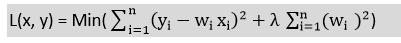
14) What is the 80/20 rule? Explain its importance in model validation?In machine learning, we usually split the dataset into two parts:
The best ratio to split the dataset is 80-20%, to create the validation set for machine learning model. Here, 80% is assigned for the training dataset, and 20% is for the test dataset. This ratio maybe 90-20%, 70-30%, 60-40%, but these ratios would not be preferable. Importance of 80/20 rule in model validation:The process of evaluating a trained model on the test dataset is called as model validation in machine learning. In model validation, the ratio of splitting dataset is important to avoid Overfitting problem. The best preferable ration is 80-20%, which is also known as 80/20 rule, but it also depends upon the amount of data in a dataset. 15) What do you understand by confusion matrix?
The classification accuracy can be obtained by the below formula: 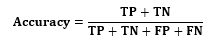
16) What is the ROC curve?ROC curve stands for Receiver Operating Characteristics curve, which graphically represents the performance of a binary classifier model at all classification threshold. The curve is a plot of true positive rate (TPR) against false positive rate (FPR) for different threshold points. 17) Explain the Decision Tree algorithm, and how is it different from the random forest algorithm?
Difference between Decision Tree and Random Forest algorithm:
18) Explain the term "Data warehouse".The data warehouse is a system which is used for analysis and reporting of data collected from operational systems and different data sources. Data warehouse plays an important role in Business Intelligence. In a data warehouse, data is extracted from various sources, transformed (cleaned and integrated) according to decision support system needs, and stored into a data warehouse. The data present in the data warehouse after analysis does not change, and it is directly used by end-users or for data visualization. Advantages of Data Warehouse:
19) What do you understand by clustering?Clustering is a way of dividing the data points into a number of groups such that data points within a group are more similar to each other than data points of other groups. These groups are called clusters, and hence, the similarities within the clusters is high, and similarities between the clusters is less. The clustering techniques are used in various fields such as machine learning, data mining, image analysis, pattern recognition, etc. 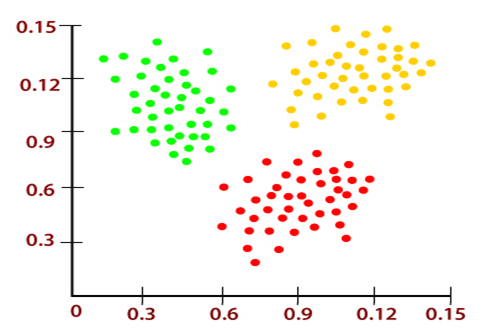
Clustering is a type of supervised learning problems in machine learning. It can be divided into two types:
20) How to determine the number of clusters in k-means clustering algorithm?In k-means clustering algorithm, the number of clusters depends on the value of k. 21) Differentiate between K-means clustering and hierarchical clustering?The K-means clustering and Hierarchical Clustering both are the machine learning algorithms. Below are some main differences between both the clustering:
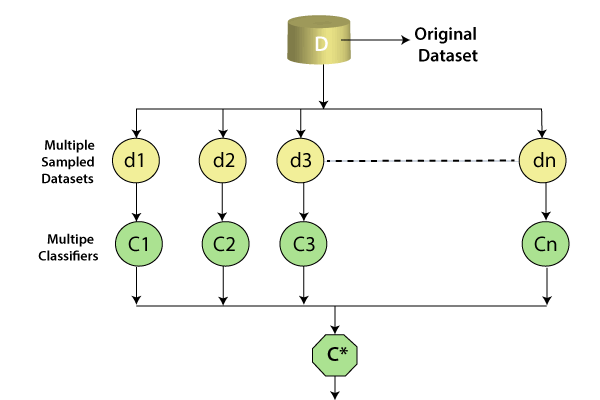
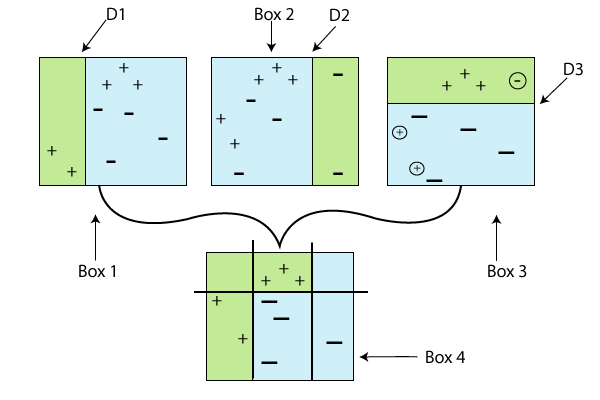
22) What do you understand by Ensemble Learning?In machine learning, Ensemble learning is a process of combining several diverse base models in order to produce one better predictive model. By combining all the predictions, ensemble learning improves the stability of the model. The concept of ensemble learning is that various weak learners come together to make a strong learner. Ensemble methods help in reducing the variance, and bias error which causes a difference in actual value and predicted value. Ensemble learning can also be used for selecting optimal features, data fusion, error correction, incremental learning, etc. Below are the two popular ensemble learning techniques:
23) Explain Box Cox transformation?A Box-Cox transformation is a statistical technique to transform the non-normal dependent variable into a normal shape. We usually need normally distributed data to use in various statistical analysis tools such as control charts, Cp/Cpk analysis, and analysis of variance. If the data is not normally distributed, we need to determine the cause for non-normality and need to take the required actions to make the data normal. So for making data normal and transforming non-normal dependent variable into a normal shape, box cox transformation technique is used. 24) What is the aim of A/B testing?A/B testing is a way of comparing two versions of a webpage to determine which webpage version is performing better than other. It is a statistical hypothesis testing which determines any changes to a webpage in order to increase the outcome of strategy. 25) How is Data Science different from Data Analytics?When we deal with data science, there are various other terms also which can be used as data science. Data Analytics is one of those terms. The data science and data analytics both deal with the data, but the difference is how they deal with it. So to clear the confusion between data science and data analytics, there are some differences given: Data Science: Data Science is a broad term which deals with structured, unstructured, and raw data. It includes everything related to data such as data analysis, data preparation, data cleansing, etc. Data science is not focused on answering particular queries. Instead, it focuses on exploring a massive amount of data, sometimes in an unstructured way. Data Analytics: Data analytics is a process of analysis of raw data to draw conclusions and meaningful insights from the data. To draw insights from data, data analytics involves the application of algorithms and mechanical process. Data analytics basically focus on inference which is a process of deriving conclusions from the observations. Data Analytics mainly focuses on answering particular queries and also perform better when it is focused. |
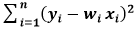 is the sum of the squared difference between the actual value and the predicted value.
is the sum of the squared difference between the actual value and the predicted value.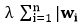 is regularization term, and λ is penalty parameter which determines how much to penalize the weights.
is regularization term, and λ is penalty parameter which determines how much to penalize the weights.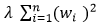 is the regularization term, and λ is the penalty parameter which determines how much to penalize the weights.
is the regularization term, and λ is the penalty parameter which determines how much to penalize the weights. You may also like:
- Java Interview Questions
- SQL Interview Questions
- Python Interview Questions
- JavaScript Interview Questions
- Angular Interview Questions
- Selenium Interview Questions
- Spring Boot Interview Questions
- HR Interview Questions
- C Programming Interview Questions
- C++ Interview Questions
- Data Structure Interview Questions
- DBMS Interview Questions
- HTML Interview Questions
- IAS Interview Questions
- Manual Testing Interview Questions
- OOPs Interview Questions
- .Net Interview Questions
- C# Interview Questions
- ReactJS Interview Questions
- Networking Interview Questions
- PHP Interview Questions
- CSS Interview Questions
- Node.js Interview Questions
- Spring Interview Questions
- Hibernate Interview Questions
- AWS Interview Questions
- Accounting Interview Questions





