| |

|
|
|
DataStage Interview QuestionsA list of top frequently asked DataStage Interview Questions and answers are given below. 1) What is IBM DataStage?DataStage is one of the most powerful ETL tools. It comes with the feature of graphical visualizations for data integration. It extracts, transforms, and loads data from source to the target. DataStage is an integrated set of tools for designing, developing, running, compiling, and managing applications. It can extract data from one or more data sources, achieve multi-part conversions of the data, and load one or more target files or databases with the resultant data. 2) Describe the Architecture of DataStage?DataStage follows the client-server model. It has different types of client-server architecture for different versions of DataStage. DataStage architecture contains the following components.
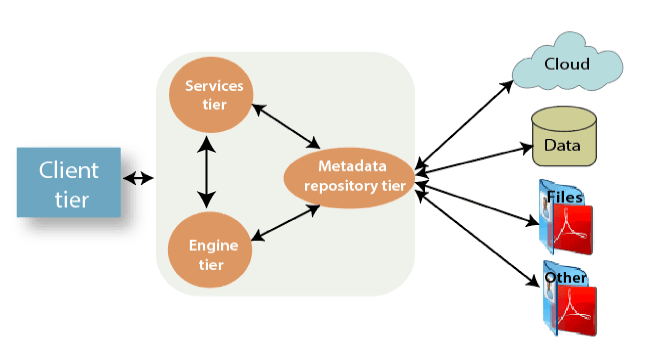
3) Explain the DataStage Parallel Extender (PX) or Enterprise Edition (EE)?DataStage PX is an IBM data integration tool. It is one of the most widely used extractions, transformation, and loading (ETL) tools in the data warehousing industry. This tool collects the information from various sources to perform transformations as per the business needs and load data into respective data warehouses. DataStage PX is also called as DataStage Enterprise Edition. 4) Describe the main features of DataStage?The main features of DataStage are as follows.
5) What are some prerequisites for DataStage?For DataStage, following set ups are necessary.
6) How to read multiple files using a single DataStage job if files have the same metadata?
It will look like: 7) Explain IBM InfoSphere information server and highlight its main features?IBM InfoSphere Information Server is a leading data integration platform which contains a group of products that enable you to understand, filter, monitor, transform, and deliver data. The scalable solution facilitates with massively parallel processing capabilities to help you to manage small and massive data volumes. It assists you in forwarding reliable information to your key business goals such as big data and analytics, data warehouse modernization, and master data management. Features of IBM InfoSphere information server
8) What is IBM DataStage Flow Designer?IBM DataStage Flow Designer allows you to create, edit, load, and run jobs in DataStage. DFD is a thin client, web-based version of DataStage. Its a web-based UI for DataStage than DataStage Designer, which is a Window-based thick client. 9) How do you run DataStage job from the command line?To run a DataStage job, use command"dsjob" command as follows. 10) What are some different alternative commands associated with "dsjob"?Many alternative optional commands can be used with dsjob command to perform any specific task. These commands are used in the below format. A list of commonly used alternative options of dsjob command is given below. Stop: it is used to stop the running job Lprojects: it is used to list the projects ljobs: it is used to list the jobs in project lparams: it is used to list the parameters in a job paraminfo: it returns the parameters info Linkinfo: It returns the link information Logdetail: it is used to display details like event_id, time, and message Lognewest: it is used to display the newest log id. log: it is used to add a text message to log. Logsum: it is used to display the log. lstages: it is used to list the stages present in the job. Llinks: it is used to list the links. Projectinfo: it returns the project information (hostname and project name) Jobinfo: it returns the job information (Job-status, job runtime,end time, etc.) Stageinfo: it returns the stage name, stage type, input rows, etc.) Report: it is used to display a report which contains Generated time, start time, elapsed time, status, etc. Jobid: it is used to provide Job id information. 11) What is a Quality Stage in DataStage tool?A Quality Stage helps in integrating different types of data from multiple sources. It is also termed as the Integrity Stage. 12) What is the process of killing a job in DataStage?To kill a job, you must destroy the particular processing ID. 13) What is a DS Designer?DataStage Designer is used to design the job. It also develops the work area and adds various links to it. 14) What are the Stages in DataStage?Stages are the basic structural blocks in InfoSphere DataStage. It provides a rich, unique set of functionality to perform advanced or straightforward data integration task. Stages hold and represent the processing steps that will be performed on the data. 15) What are Operators in DataStage?The parallel job stages are made on operators. A single-stage might belong to a single operator or a number of operators. The number of operators depends on the properties you have set. During compilation, InfoSphere DataStage estimates your job design and sometimes will optimize operators. 16) Explain connectivity between DataStage with DataSources?IBM InfoSphere Information Server supports connectors and enables jobs for data transfer between InfoSphere Information Server and data sources. IBM InfoSphere DataStage and QualityStage jobs can access data from enterprise applications and data sources such as:
17) Describe Stream connector?The Stream connector allows integration between the Streams and the DataStage. InfoSphere Stream connector is used to send data from a DataStage job to a Stream job and vice versa. InfoSphere Streams can perform close to real-time analytic processing in parallel to the data loading into a data warehouse. Alternatively, the InfoSphere Streams job performs RTAP processing. After RTAP processing, it forwards the data to InfoSphere DataStage to transform, enrich, and store the details for archival purposes. 18) What is the use of HoursFromTime() Function in Transformer Stage in DataStage?HoursFromTime Function is used to return hour portion of the time. Its input is time, and Output is hours (int8). Examples: If myexample1.time contains the time 22:30:00, then the following two functions are equivalent and return the integer value 22. 19) What is the Difference between Informatica and DataStage?The DataStage and Informatica both are powerful ETL tools. Both tools do almost the same work in nearly the same manner. In both tools, the performance, maintainability, and learning curve are similar and comparable. Below are the few differences between both tools.
20) How We Can Covert Server Job To A Parallel Job?We can convert a server job into a parallel job by using Link Collector and IPC Collector. 21) What are the different layers in the information server architecture?The different layers of information server architecture are as follows.
22) If you want to use the same piece of code in different jobs, how will you achieve it?DataStage facilitates with a feature called shared containers which allows sharing the same piece of code for a different job. The containers are shared for reusability. A shared container consists of a reusable job element of stages and links. We can call a shared container in, unlike DataStage jobs. 23) How many types of Sorting methods are available in DataStage?There are two types of sorting methods available in DataStage for parallel jobs.
24) Describe Link Sort?The Link sort supports fewer options than other sorts. It is easy to maintain in a DataStage job as there are only few stages in the DataStage job canvas. Link sort is used unless a specific option is needed over Sort Stage. Most often, the Sort stage is used to specify the Sort Key mode for partial sorts. Sorting on a link option is available on the input/partitioning stage options. We cannot specify a keyed partition if we use auto partition method. 25) Which commands are used to import and export the DataStage jobs?We use the following commands for the given operations. For Import: we use the dsimport.exe command For Export, we use the dsexport.exe command 26) Describe routines in DataStage? Enlist various types of routines.Routine is a set of tasks which are defined by the DS manager. It is run via the transformer stage. There are three kinds of routines
27) What is the different type of jobs in DataStage?There are two types of jobs in DataStage
28) State the difference between an Operational DataStage and a Data Warehouse?An Operational DataStage can be considered as a presentation area for user processing and real-time analysis. Thus, operational DataStage is a temporary repository. Whereas the Data Warehouse is used for durable data storage needs and holds the complete data of the entire business. 29) What is the importance of the exception activity in DataStage?The reason behind the importance of exception activity is that during the job execution, exception activity handles all the unfamiliar error activity. 30) What is "Fatal Error/RDBMS Code 3996" error?This error occurs while testing jobs in DataStage 8.5 during Teradata 13 to 14 upgrade. It is because the user tries to assign a longer string to a shorter string destination, and sometimes if the length of one or more range boundaries in a RANGE_N function is a string literal with a length higher than that of the test value. |
You may also like:
- Java Interview Questions
- SQL Interview Questions
- Python Interview Questions
- JavaScript Interview Questions
- Angular Interview Questions
- Selenium Interview Questions
- Spring Boot Interview Questions
- HR Interview Questions
- C Programming Interview Questions
- C++ Interview Questions
- Data Structure Interview Questions
- DBMS Interview Questions
- HTML Interview Questions
- IAS Interview Questions
- Manual Testing Interview Questions
- OOPs Interview Questions
- .Net Interview Questions
- C# Interview Questions
- ReactJS Interview Questions
- Networking Interview Questions
- PHP Interview Questions
- CSS Interview Questions
- Node.js Interview Questions
- Spring Interview Questions
- Hibernate Interview Questions
- AWS Interview Questions
- Accounting Interview Questions





