| |

|
|
|
Algorithm Interview Questions and Answers
An algorithm is an integral part of any process so that interviewers will ask you many questions related to the algorithm. Here is the list of some most asked algorithm interview questions and their answer. These questions are also beneficial for academic and competitive exams perspective. 1) What is an algorithm? What is the need for an algorithm?An algorithm is a well-defined computational procedure that takes some values or the set of values, as an input and produces a set of values or some values, as an output. Need for Algorithm The algorithm provides the basic idea of the problem and an approach to solve it. Some reasons to use an algorithm are as follows.
2) What is the Complexity of Algorithm?The complexity of the algorithm is a way to classify how efficient an algorithm is compared to alternative ones. Its focus is on how execution time increases with the data set to be processed. The computational complexity of the algorithm is important in computing. It is very suitable to classify algorithm based on the relative amount of time or relative amount of space they required and specify the growth of time/ space requirement as a function of input size. Time complexity Time complexity is a Running time of a program as a function of the size of the input. Space complexity Space complexity analyzes the algorithms, based on how much space an algorithm needs to complete its task. Space complexity analysis was critical in the early days of computing (when storage space on the computer was limited). Nowadays, the problem of space rarely occurs because space on the computer is broadly enough. We achieve the following types of analysis for complexity Worst-case: f(n) It is defined by the maximum number of steps taken on any instance of size n. Best-case: f(n) It is defined by the minimum number of steps taken on any instance of size n. Average-case: f(n) It is defined by the average number of steps taken on any instance of size n. 3) Write an algorithm to reverse a string. For example, if my string is "uhsnamiH" then my result will be "Himanshu".Algorithm to reverse a string. Step1: start Step2: Take two variable i and j Step3: do length (string)-1, to set J at last position Step4: do string [0], to set i on the first character. Step5: string [i] is interchanged with string[j] Step6: Increment i by 1 Step7: Increment j by 1 Step8: if i>j then go to step3 Step9: Stop 4) Write an algorithm to insert a node in a sorted linked list.Algorithm to insert a node in a sorted linked list. Case1: Check if the linked list is empty then set the node as head and return it. Case2: Insert the new node in middle Case3: Insert a node at the end 5) What are the Asymptotic Notations?Asymptotic analysis is used to measure the efficiency of an algorithm that doesn't depend on machine-specific constants and prevents the algorithm from comparing the time taking algorithm. Asymptotic notation is a mathematical tool that is used to represent the time complexity of algorithms for asymptotic analysis. The three most used asymptotic notation is as follows. θ Notation θ Notation defines the exact asymptotic behavior. To define a behavior, it bounds functions from above and below. A convenient way to get Theta notation of an expression is to drop low order terms and ignore leading constants. 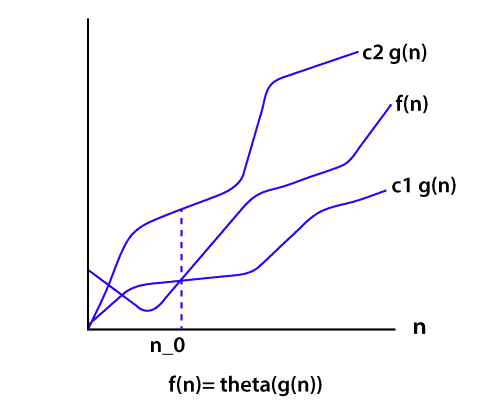
Big O Notation The Big O notation bounds a function from above, it defines an upper bound of an algorithm. Let's consider the case of insertion sort; it takes linear time in the best case and quadratic time in the worst case. The time complexity of insertion sort is O(n2). It is useful when we only have upper bound on time complexity of an algorithm. 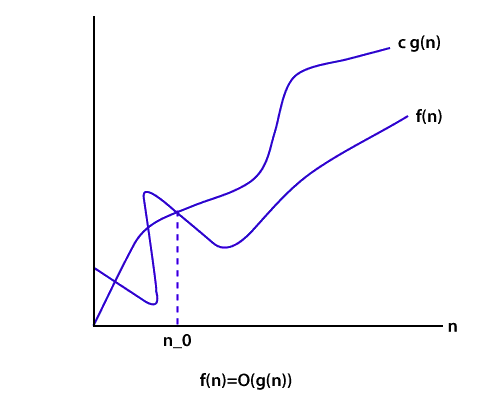
Ω Notation Just like Big O notation provides an asymptotic upper bound, the Ω Notation provides an asymptotic lower bound on a function. It is useful when we have lower bound on time complexity of an algorithm. 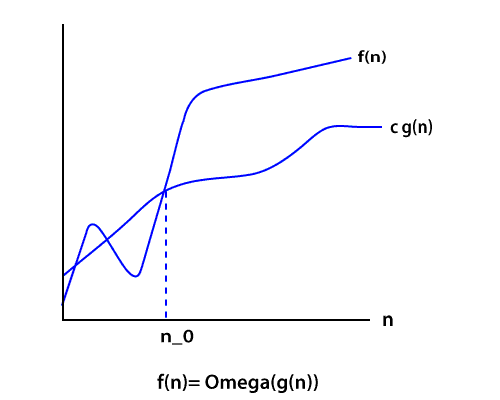
6) Explain the Bubble sort algorithm?Bubble sort is the simplest sorting algorithm among all sorting algorithm. It repeatedly works by swapping the adjacent elements if they are in the wrong order. e.g. (72538) we have this array for sorting. Pass1: (72538) -> (27538) swap 7 and 2. Pass2: (25378) -> (25378) algorithm does not swap 2 and 5 because 2<5. Here, the sorted element is (23578). 7) How to swap two integers without swapping the temporary variable in Java?It's a very commonly asked trick question. There are many ways to solve this problem. But the necessary condition is we have to solve it without swapping the temporary variable. If we think about integer overflow and consider its solution, then it creates an excellent impression in the eye of interviewers. Suppose we have two integers I and j, the value of i=7 and j=8 then how will you swap them without using a third variable. This is a journal problem. We need to do this using Java programming constructs. We can swap numbers by performing some mathematical operations like addition, subtraction, multiplication, and division. But maybe it will create the problem of integer overflow. Using addition and subtraction It is a nice trick. But in this trick, the integer will overflow if the addition is more than the maximum value of int primitive as defined by Integer.MAX_VALUE and if subtraction is less than minimum value i.e., Integer.MIN_VALUE. Using XOR trick Another solution to swap two integers without using a third variable (temp variable) is widely recognized as the best solution, as it will also work in a language which doesn't handle integer overflow like Java example C, C++. Java supports several bitwise operators. One of them is XOR (denoted by ^). 8) What is a Hash Table? How can we use this structure to find all anagrams in a dictionary?A Hash table is a data structure for storing values to keys of arbitrary type. The Hash table consists of an index into an array by using a Hash function. Indexes are used to store the elements. We assign each possible element to a bucket by using a hash function. Multiple keys can be assigned to the same bucket, so all the key and value pairs are stored in lists within their respective buckets. Right hashing function has a great impact on performance. To find all anagrams in a dictionary, we have to group all words that contain the same set of letters in them. So, if we map words to strings representing their sorted letters, then we could group words into lists by using their sorted letters as a key. The hash table contains lists mapped to strings. For each word, we add it to the list at the suitable key, or create a new list and add it to it. 9) What is Divide and Conquer algorithms?Divide and Conquer is not an algorithm; it's a pattern for the algorithm. It is designed in a way as to take dispute on a huge input, break the input into minor pieces, and decide the problem for each of the small pieces. Now merge all of the piecewise solutions into a global solution. This strategy is called divide and conquer. Divide and conquer uses the following steps to make a dispute on an algorithm. Divide: In this section, the algorithm divides the original problem into a set of subproblems. Conquer: In this section, the algorithm solves every subproblem individually. Combine: In this section, the algorithm puts together the solutions of the subproblems to get the solution to the whole problem. 10) Explain the BFS algorithm?BFS (Breadth First Search) is a graph traversal algorithm. It starts traversing the graph from the root node and explores all the neighboring nodes. It selects the nearest node and visits all the unexplored nodes. The algorithm follows the same procedure for each of the closest nodes until it reaches the goal state. Algorithm Step1: Set status=1 (ready state) Step2: Queue the starting node A and set its status=2, i.e. (waiting state) Step3: Repeat steps 4 and 5 until the queue is empty. Step4: Dequeue a node N and process it and set its status=3, i.e. (processed state) Step5: Queue all the neighbors of N that are in the ready state (status=1) and set their status =2 (waiting state) Step6: Exit 11) What is Dijkstra's shortest path algorithm?Dijkstra's algorithm is an algorithm for finding the shortest path from a starting node to the target node in a weighted graph. The algorithm makes a tree of shortest paths from the starting vertex and source vertex to all other nodes in the graph. Suppose you want to go from home to office in the shortest possible way. You know some roads are heavily congested and challenging to use this, means these edges have a large weight. In Dijkstra's algorithm, the shortest path tree found by the algorithm will try to avoid edges with larger weights. 12) Give some examples of Divide and Conquer algorithm?Some problems that use Divide and conquer algorithm to find their solution are listed below.
13) What are Greedy algorithms? Give some example of it?A greedy algorithm is an algorithmic strategy which is made for the best optimal choice at each sub stage with the goal of this, eventually leading to a globally optimum solution. This means that the algorithm chooses the best solution at the moment without regard for consequences. In other words, an algorithm that always takes the best immediate, or local, solution while finding an answer. Greedy algorithms find the overall, ideal solution for some idealistic problems, but may discover less-than-ideal solutions for some instances of other problems. Below is a list of algorithms that finds their solution with the use of the Greedy algorithm.
14) What is a linear search?Linear search is used on a group of items. It relies on the technique of traversing a list from start to end by visiting properties of all the elements that are found on the way. For example, suppose an array of with some integer elements. You should find and print the position of all the elements with their value. Here, the linear search acts in a flow like matching each element from the beginning of the list to the end of the list with the integer, and if the condition is `True then printing the position of the element.' Implementing Linear Search Below steps are required to implement the linear search. Step1: Traverse the array using for loop. Step2: In every iteration, compare the target value with the current value of the array Step3: If the values match, return the current index of the array Step4: If the values do not match, shift on to the next array element. Step5: If no match is found, return -1 15) What is a Binary Search Tree?The binary search tree is a special type of data structure which has the following properties.
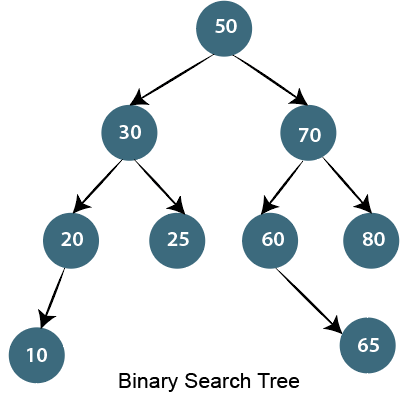
16) Write an algorithm to insert a node in the Binary search tree?Insert node operation is a smooth operation. You need to compare it with the root node and traverse left (if smaller) or right (if greater) according to the value of the node to be inserted. Algorithm:
17) How to count leaf nodes of the binary tree?Algorithm- Steps for counting the number of leaf nodes are:
No. of leaf nodes= no of leaf nodes in left subtree + number of leaf nodes in the right subtree. 18) How to find all possible words in a board of characters (Boggle game)?In the given dictionary, a process to do a lookup in the dictionary and an M x N board where every cell has a single character. Identify all possible words that can be formed by order of adjacent characters. Consider that we can move to any of the available 8 adjacent characters, but a word should not have multiple instances of the same cell. Example: Output: Following words of the dictionary are present JAVA 19) Write an algorithm to insert a node in a link list?Algorithm
20) How to delete a node in a given link list? Write an algorithm and a program?Write a function to delete a given node from a Singly Linked List. The function must follow the following constraints:
We may assume that the Linked List never becomes empty. Suppose the function name is delNode(). In a direct implementation, the function needs to adjust the head pointer when the node to be deleted the first node. C program for deleting a node in Linked List We will handle the case when the first node to be deleted then we copy the data of the next node to head and delete the next node. In other cases when a deleted node is not the head node can be handled generally by finding the previous node. Output: Available Link List: 12 15 10 11 5 6 2 3 Delete node 10: Updated Linked List: 12 15 11 5 6 2 3 Delete first node Updated Linked list: 15 11 5 6 2 3 21) Write a c program to merge a link list into another at an alternate position?We have two linked lists, insert nodes of the second list into the first list at substitute positions of the first list. Example if first list is 1->2->3 and second is 12->10->2->4->6, the first list should become 1->12->2->10->17->3->2->4->6 and second list should become empty. The nodes of the second list should only be inserted when there are positions available. Use of extra space is not allowed i.e., insertion must be done in a place. Predictable time complexity is O(n) where n is number of nodes in first list. Output: I Linked List: 1 2 3 II Linked List: 4 5 6 7 8 Updated I Linked List: 1 4 2 5 3 6 Updated II Linked List: 7 8 22) Explain how the encryption algorithm works?Encryption is the technique of converting plaintext into a secret code format it is also called as "Ciphertext." To convert the text, the algorithm uses a string of bits called as "keys" for calculations. The larger the key, the higher the number of potential patterns for Encryption. Most of the algorithm use codes fixed blocks of input that have a length of about 64 to 128 bits, while some uses stream method for encryption. 23) What Are The Criteria Of Algorithm Analysis?An algorithm is generally analyzed by two factors.
Time complexity deals with the quantification of the amount of time taken by a set of code or algorithm to process or run as a function of the amount of input. In other words, the time complexity is efficiency or how long a program function takes to process a given input. Space complexity is the amount of memory used by the algorithm to execute and produce the result. 24) What are the differences between stack and Queue?Stack and Queue both are non-primitive data structure used for storing data elements and are based on some real-world equivalent. Let's have a look at key differences based on the following parameters. Working principle The significant difference between stack and queue is that stack uses LIFO (Last in First Out) method to access and add data elements whereas Queue uses FIFO (First in first out) method to obtain data member. Structure In Stack, the same end is used to store and delete elements, but in Queue, one end is used for insertion, i.e., rear end and another end is used for deletion of elements. Number of pointers used Stack uses one pointer whereas Queue uses two pointers (in the simple case). Operations performed Stack operates as Push and pop while Queue operates as Enqueue and dequeuer. Variants Stack does not have variants while Queue has variants like a circular queue, Priority queue, doubly ended Queue. Implementation The stack is simpler while Queue is comparatively complex. 25) What is the difference between the Singly Linked List and Doubly Linked List data structure?This is a traditional interview question on the data structure. The major difference between the singly linked list and the doubly linked list is the ability to traverse. You cannot traverse back in a singly linked list because in it a node only points towards the next node and there is no pointer to the previous node. On the other hand, the doubly linked list allows you to navigate in both directions in any linked list because it maintains two pointers towards the next and previous node. |
You may also like:
- Java Interview Questions
- SQL Interview Questions
- Python Interview Questions
- JavaScript Interview Questions
- Angular Interview Questions
- Selenium Interview Questions
- Spring Boot Interview Questions
- HR Interview Questions
- C Programming Interview Questions
- C++ Interview Questions
- Data Structure Interview Questions
- DBMS Interview Questions
- HTML Interview Questions
- IAS Interview Questions
- Manual Testing Interview Questions
- OOPs Interview Questions
- .Net Interview Questions
- C# Interview Questions
- ReactJS Interview Questions
- Networking Interview Questions
- PHP Interview Questions
- CSS Interview Questions
- Node.js Interview Questions
- Spring Interview Questions
- Hibernate Interview Questions
- AWS Interview Questions
- Accounting Interview Questions





