| |

|
|
|
Top 35 Most Asked Sqoop Interview Questions and Answers1) What is Sqoop? / Give a short introduction of Apache Sqoop.Sqoop is an acronym that stands for SQL-TO-HADOOP. Apache Sqoop is a tool used to import data from various types of relational databases. It is an open-source framework and a command-line interface application provided by Apache for transferring data between relational databases (MySQL / PostgreSQL / Oracle / SQL Server / DB2 etc.) and Hadoop (HIVE, HDFS, HBase, etc.). Using Apache Sqoop, we can import data from various types of databases such as MySQL, HDFS, and Hadoop. It also facilitates us to export data from the Hadoop file. Apache Sqoop provides mainly two facilities, Sqoop export, and Sqoop import that can be used to extract data from various types of databases. Sqoop is robust as it has wide community support and contributions. 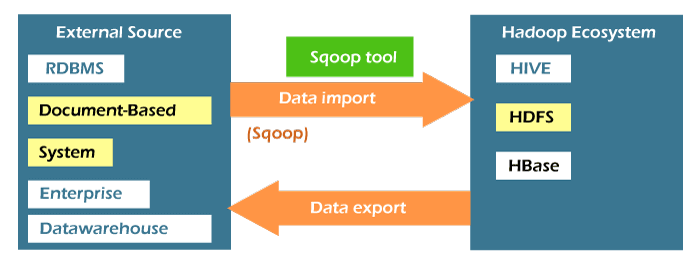
2) What is the main usage of Sqoop?Sqoop is mainly used for transferring the immense data between the relational database and the Hadoop ecosystem. The entire database or individual table is imported to the ecosystem (HDFS), and after modification, it is exported to the database. The Sqoop helps to support the multiple loads in one database table. 3) What is the difference between Sqoop and Flume?Sqoop and Flume are the Apache tools used for moving data. Let's see the key differences between them.
4) What do you understand by Apache Sqoop eval?The Apache Sqoop eval tool is used for the sample demo for the import data. It is a permit that the users need to run the sample RDBMS queries and examine the results on the console. Because of the eval tool, it is possible to recognize output and know what kind of data is imported. 5) How can you import large objects like BLOB and CLOB in Apache Sqoop?The Apache Sqoop does not support the direct import function in the case of CLOB and BLOB objects. So, in the case you want to import large objects like BLOB and CLOB in Apache Sqoop, you can use JDBC-based imports. You can do this without introducing the direct argument of the import utility. 6) Does Apache Sqoop use MapReduce?Apache Sqoop uses Mapreduce for parallel import and exports the data between the database and the Hadoop file system. It is mainly used for fault resistance. 7) What do you understand by Sqoop Import? Why is it used?Sqoop Import is a tool used to import tables from RDBMS to HDFS. When the data is imported from the table to HDFS, each row in a table is considered a record in HDFS. Also, all text files and records are there as text data. Avro and sequence files and their all records are there as binary data here. So, we can say that Sqoop Import imports individual tables from RDBMS to HDFS. 8) What are the key advantages of using Apache Sqoop?Following is a list of the key advantages of using Apache Sqoop: Support parallel data transfer and fault tolerance Sqoop uses the Hadoop YARN (Yet Another Resource Negotiator) framework for import and export processes that facilitate parallel data transfer. YARN also provides a fault tolerance facility. Import only the required data Apache Sqoop imports only the required data. It imports a subset of rows from a database table returned from an SQL query. Support all major RDBMS Sqoop supports all major RDBMS, including MySQL, Postgres, Oracle RDB, SQLite, etc., to connect to the HDFS. When we want to connect to an RDBMS, the database requires JDBC (Java Database Connectivity) and a connector that supports JDBC. Due to its support for fully loading tables, data can be directly loaded into Hive/HBase/HDFS. The other parts of the table can be loaded whenever they are updated using the feature of incremental load. Loads data directly into Hive/HBase/HDFS Apache Sqoop imports data from an RDBMS database directly into Hive, HBase, or HDFS for further analysis. Here, HBase is a NoSQL database, but Sqoop can also import data into HBase. A single command for loading data Sqoop provides a single command to load all the tables from a particular RDBMS database to Hadoop. Support Compressing Sqoop provides deflate (gzip) algorithm and -compress argument to compress data. We can also perform compression using the -compression-codec argument and load the compressed tables onto Hive. Support Kerberos Security Integration Sqoop provides support for Kerberos Security authentication too. Kerberos is a computer network authentication protocol that uses 'tickets' to allow nodes interacting over a non-secure point to prove their identity to each other in a secure manner. 9) Does Apache Sqoop have a default database?Yes, MySQL is the default database for Apache Sqoop. 10) What is the default file format to import data using Apache Sqoop?Sqoop allows us to import data using the following two file formats: Delimited Text File Format The delimited text file format is the default file format to import data using Apache Sqoop. This file format explicitly uses the -as-textfile argument to the import command in Sqoop. When we pass this as an argument to the command, it produces the string-based representation of all the records to the output files with the delimiter characters between rows and columns. Sequence File Format The Sequence File Format is a binary file format. In this file format, the records are stored in custom record-specific data types shown as Java classes. Sqoop automatically creates these data types and manifests them as java classes. 11) When we use -target-dir and -warehouse-dir while importing data in Sqoop?The -target-dir is used to specify a particular directory in HDFS, while the -warehouse-dir specifies the parent directory of all the Sqoop jobs. In this case, Sqoop creates a directory with the same name as the table under the parent directory. 12) How can you execute a free-form SQL query in Sqoop to import the rows sequentially?We can execute a free-form SQL query in Sqoop to import the rows sequentially using the -m 1 option in the Sqoop import command. It creates only one MapReduce task, which will then import rows serially. 13) How can you import data from a particular row or column in Sqoop? What are the destination types allowed in the Sqoop import command?Sqoop facilitates users to Export and Import the data from the data table based on the WHERE clause. Syntax: Sqoop supports to import data into the following services:
14) What do you understand by Sqoop Metastore?The Sqoop Metastore is a Sqoop tool used to configure the Sqoop application to enable the hosting of a shared repository in the form of metadata. It can also be used to execute the jobs and manage several users according to their roles and activities. The Sqoop Metastore is implemented as an in-memory representation by default and facilitates multiple users to perform multiple tasks or operations concurrently to achieve the tasks efficiently. When a job is created within Sqoop, the job definition is stored inside the Metastore and will be listed using Sqoop jobs if required. 15) If the source data gets updated now and then, how will you synchronize the data in HDFS that Sqoop imports?If the source data gets updated now and then, we can use the incremental parameter with data import to synchronize the data. There are two ways to use the incremental parameter: Append: Generally, we should use incremental import with append option if the source data gets updated now and then or if the table is updated continuously with new rows and increasing row id values. It is also used where values of some of the columns are checked, and if it discovers any modified value for those columns, then it inserts only a new row. Lastmodified: In this kind of incremental import, the source has a date column that is checked continuously. Any records that have been updated after the last import based on the lastmodifed column in the source, the values would be updated. 16) What is the use of Sqoop-merge?Sqoop merge is a tool available in Sqoop that facilitates us to combine two different datasets. In this tool, the entries of one dataset override the entries of the older dataset. It provides a flattening process while merging the two different datasets that preserve the data without any loss, efficiency, and safety. We have to use a merge key command like "-merge-key." It is very useful for efficiently transferring the huge volume of data between Hadoop and structured data stores like relational databases. 17) How can you execute a free-form SQL query to import rows?To execute a free-form SQL query to import rows, we must use the -m1 option. This option would create only one MapReduce task, and then you can import the rows directly. 18) What are the most used commands and functions in Sqoop?Following is the list of basic and most used commands and functions in Sqoop:
19) What is the importance of using -compress-codec parameter?The importance of using -compress-codec parameter is that it can be used to get the export file of the Sqoop import in the mentioned formats. 20) Is the JDBC driver fully capable of connecting Sqoop to the databases?No, the JDBC driver is not fully capable of connecting Sqoop to the databases. To connect Sqoop to any database, you need the connector and JDBC driver. 21) How can you update the data or rows already exported to the destination?If you want to update the rows that are already exported to the destination, you can use the parameter "-update-key". While using this parameter, a comma-separated column list is used, which uniquely identifies a row. Then the SET part of the query maintains all the other table columns. All of these columns are used in the WHERE clause, which is generated after the UPDATE query. 22) What is the use of reducers in Sqoop?In Sqoop, the reducers are used for accumulation or aggregation. They fetch the data transfer by the database to Hadoop after Mapping. There is no significant use of reducer in Sqoop because import and export work parallel in Sqoop. 23) What do you understand by Free-form query import in Sqoop?Sqoop facilitates us to import the relational database query and the result set of an arbitrary SQL query. You can specify a SQL statement with the-- query argument instead of using the --table, --columns, and --where arguments. It means this can be done by using column and table name parameters. In Sqoop, while importing a free-form query, we must specify a destination directory with --target-dir. 24) What is the --directive mode in Sqoop?Sqoop used for Hadoop and database connection has some stages. In Sqoop, the --directive mode is used for directly importing multiple tables or individual tables into HIVE, HDFS, or HBase. The --directive mode is mainly used when you have a specific database connection directly apart from the default database connection. 25) What is the advantage of using -password-file rather than -P option in Sqoop?In Sqoop, the -password-file option is usually used inside the Sqoop script file. On the other hand, the -P option can read the standard input and column name parameters. 26) What is the use of Sqoop Export?The Sqoop Export tool transfers the data from HDFS to RDBMS. Before transforming the data, the Sqoop tool fetches the table from the database. After that, the table would be available in the database. Syntax: 27) What is the role of JDBC drivers in Sqoop?If you want to connect Sqoop to databases, you need a connector and a JDBC driver to connect to it. As a JDBC driver, every DB vendor makes this connector available specific to that database. So, if you want to interact with Sqoop, it requires a JDBC driver for each database. You should remember that only a JDBC driver is not enough to connect Sqoop to the databases. To connect to a database, Sqoop needs both JDBC driver and connector. 28) What is the boundary query, and what is the use of boundary query in Sqoop?During the Sqoop import process, it uses a query to calculate the boundary for creating splits like select min(), max() from table_name. This query is known as a boundary query. The boundary query is mainly used to split the value according to id_no of the database table. We can take a minimum and maximum value to split the value to write a boundary query. We must be aware of all the values in the table for making split using boundary queries. We can also use boundary queries to import data from the database to HDFS. Example: 29) What is the difference between --split-by and --boundary-query in Sqoop?In Sqoop, the key difference between --split-by and --boundary-query is that the --split-by id splits your data uniformly based on the number of mappers (default 4). On the other hand, the boundary query by default is something like this: You can specify any arbitrary query returning val1 and val2. But if the id starts from val1 and ends with val2, then there is no point in calculating min() and max() operations. This makes Sqoop command execution faster. 30) What is InputSplit in Hadoop?InputSplit is the logical representation of data in Hadoop MapReduce. It is used to represent the data processed by an individual mapper. Thus the number of map tasks is equal to the number of InputSplits. The framework divides split into records, which mapper processes. In other words, when a Hadoop job runs, InputSplit splits input files into chunks and assigns each split to a mapper to process. MapReduce InputSplit length has been measured in bytes. 31) What is the difference between InputSplit and HDFS block?InputSplit is a logical reference to data means it doesn't contain any data inside. It is only used during data processing by MapReduce. On the other hand, the HDFS block is a physical location that stores all the actual data. 32) How can you use Sqoop in a Java program?To use Sqoop in a Java program, we must include Sqoop jar in the classpath of the java code. We must also create all the necessary parameters programmatically to use Sqoop in a Java program. After this step, we must invoke the Sqoop.runTool() method. 33) What is the benefit of using -compress-codec parameter?The benefit of using -compress-codec parameter is that it provides the file of a Sqoop import in formats other than .gz like .bz2. 34) Is it possible to use free-form SQL queries with the Sqoop import command? If yes, then how can you use them?Yes, it is possible to use free-form SQL queries with the Sqoop import command. Generally, we should use the import command with the -e and -query options to execute free-form SQL queries. We must also specify the -target dir value while using the -e and -query options with the import command. 35) How can you schedule a job using Oozie?Oozie is an in-built Sqoop action inside which we can mention the Sqoop commands that we want to execute. |
You may also like:
- Java Interview Questions
- SQL Interview Questions
- Python Interview Questions
- JavaScript Interview Questions
- Angular Interview Questions
- Selenium Interview Questions
- Spring Boot Interview Questions
- HR Interview Questions
- C Programming Interview Questions
- C++ Interview Questions
- Data Structure Interview Questions
- DBMS Interview Questions
- HTML Interview Questions
- IAS Interview Questions
- Manual Testing Interview Questions
- OOPs Interview Questions
- .Net Interview Questions
- C# Interview Questions
- ReactJS Interview Questions
- Networking Interview Questions
- PHP Interview Questions
- CSS Interview Questions
- Node.js Interview Questions
- Spring Interview Questions
- Hibernate Interview Questions
- AWS Interview Questions
- Accounting Interview Questions





