| |

Onion RoutingOnion routing is a method of communicating anonymously over a computer network. Messages in an onion network are encapsulated in layers of encryption, similar to the layers of an onion. To make web browsing safer and more secure for users, there is a large set of precautionary measures and best practises. Assume you send an HTTPS request to a server and someone intercepts it, but that person cannot read the message because it is encrypted. However, you are not satisfied with this level of security and wish to take it to the next level, i.e. you do not want anyone sniffing on your network to know which server you are contacting and whether or not you are making any requests. This is where the onion routing comes into play. The Onion Routing programme is made up of studies that look into, design, build, and analyse anonymous communication networks. The emphasis is on practical solutions for low-latency Internet-based connections that can withstand traffic analysis, eavesdropping, and other attacks from both outsiders (like Internet routers) and insiders (like hackers) (Onion Routing servers themselves). The network only knows that communication is taking place because onion routing hides who is communicating with whom from the transport medium. Furthermore, the content of the conversation is hidden from eavesdroppers until the transmission leaves the OR network. What is the procedure for onion routing?When you browse the internet using a standard web browser such as Chrome or Firefox, you request webpages by sending simple GET requests to servers with no intermediary. It is only a single connection between a client and a server, and anyone sniffing on your network can determine which server your computer is contacting.
An explanation of the onion routing conceptNow imagine you are using Tor (the onion router), a unique browser that enables you to use the onion routers, to browse the internet. Since YouTube is blocked in China, you want to access YouTube but you also don't want your government to find out that you are doing so, so you choose to use Tor. To get the YouTube homepage, your computer must make contact with a specific server, but it does not do so directly. In order to prevent anyone from tracking the conversation you had with that server, it does this through three nodes/servers/routers (maintained by volunteers around the world) before that server. Although a real Tor network can have hundreds of nodes in between, I am only using 3 nodes in this example to keep things simple. 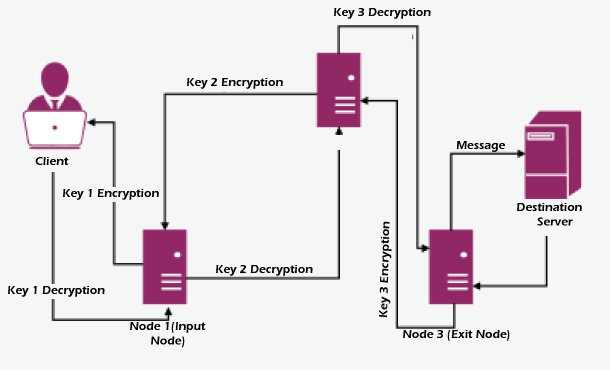
In what way does it offer anonymity?Imagine that a sniffer is present at the first connection (client - input node) and that all it can decipher is the address of the input node and an illogical message that has been triple encrypted. Therefore, the spy or attacker is aware that you are using Tor to browse. Similar to this, if sniffing begins at the exit node, all the sniffer sees is one server speaking to another, but it is unable to identify the client or the origin of the request. However, you might now imagine that if someone were to listen in at Node 2, they would be able to trace the client and the destination server if they knew the addresses of the input and exit. But it's not that easy; each of these nodes is running hundreds of connections simultaneously, making it difficult to determine which connection leads to the correct source and destination. Node 2 is a middle node in our circuit, but it can also be a part of another circuit on a different connection where it serves as an exit node dispensing websites from various servers or an input node receiving requests. Attack Surface for Onion RoutingThe only security hole in onion routing is that if someone is watching a server at the same time and compares a request made by a client on the other side of the network to a request made by a server at the destination by analysing the length and frequency of the characters found in the intercepted request or response at the destination server and using that to match with the same request made by a client in a split second (time-stamps on requests and responses can also be used as a substitute for Even though it's challenging, it's not impossible. However, fixing this flaw in Tor is essentially impossible. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








