| |

Cristian's AlgorithmClient processes synchronise time with a time server using Cristian's Algorithm, a clock synchronisation algorithm. While redundancy-prone distributed systems and applications do not work well with this algorithm, low-latency networks where round trip time is short relative to accuracy do. The time interval between the beginning of a Request and the conclusion of the corresponding Response is referred to as Round Trip Time in this context. An example mimicking the operation of Cristian's algorithm is provided below: 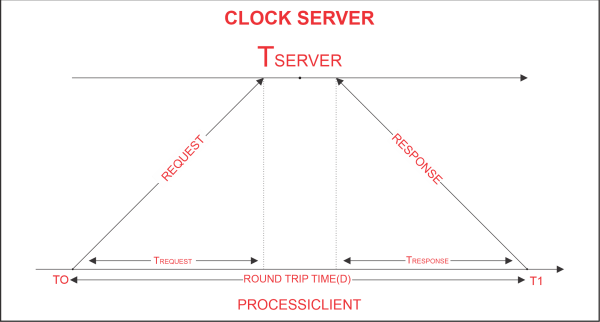
Algorithm:
TCLIENT = TSERVER plus (T1 - T0)/2. where TCLIENT denotes the synchronised clock time, TSERVER denotes the clock time returned by the server, T0 denotes the time at which the client process sent the request, and T1 denotes the time at which the client process received the response The formula above is valid and reliable: Assuming that the network latency T0 and T1 are roughly equal, T1 - T0 denotes the total amount of time required by the network and server to transfer the request to the server, process it, and return the result to the client process. The difference between client-side and real-time time is no more than (T1 - T0)/2 seconds. We can infer from the aforementioned statement that the synchronisation error can only be (T1 - T0)/2 seconds at most. Hence, Error E [-(T 1 - T 0)/2, (T 1 - T 0)/2] The Python codes below demonstrate how Cristian's algorithm functions. To start a clock server prototype on a local machine, enter the following code: PythonOutput: Socket successfully created Socket is listening... On the local machine, the following code runs a client process prototype: PythonOutput: Time returned by server: 2018-11-07 17:56:43.302379 Process Delay latency: 0.0005150819997652434 seconds Actual clock time at client side: 2018-11-07 17:56:43.302756 Synchronized process client time: 2018-11-07 17:56:43.302637 Synchronization error : 0.000119 seconds We can define a minimum transfer time that we can use to create an improved synchronisation clock time through iterative testing over the network (less synchronisation error). The server time will always be generated after T0 + T min in this case, and TSERVER will always be generated before T1 - Tmin, where T min is the minimum transfer time, which is the minimum value of TREQUEST and TRESPONSE during several iterative tests. Here, a formulation of the synchronisation error is as follows: Error E [-((T1 - T0)/2-Tmin), ((T1 - T0)/2-Tmin)] Similar to this, if TREQUEST and TRESPONSE differ by a significant amount of time, TMIN1 and TMIN2 may be used in place of TMIN1 and TMIN2, respectively, where TMIN1 denotes the minimum observed request time and TMIN2 denotes the minimum observed response time over the network. In this scenario, the synchronised clock time can be calculated as follows: (T1 - T0)/2 + (Tmin2 - Tmin1)/2 +TSERVER = TCLIENT Therefore, we can improve clock time synchronisation and subsequently reduce the overall synchronisation error by simply introducing response and request time as separate time latencies. The total clock drift that is seen will determine how many iterative tests need to be performed. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








