| |

mbsrtowcs() Function in C/C++In this article, you will learn about the mbsrtowcs() function in C++ with its example. In C/C++, the mbsrtowcs() function is an effective tool for managing character conversions within strings. It is an essential component of the Standard C Library that helps developers work with various character encodings, internationalize and localize software applications, and convert multibyte strings to wide character strings. Function and Purpose:The main goal of the mbsrtowcs() function is to transform a string of multibyte characters into a string of wide characters. Its ability to convert strings encoded in multibyte encodings (like UTF-8) into wide character strings (often encoded in UTF-16 or UTF-32) makes it indispensable for applications that must handle a variety of character sets. It is particularly crucial in situations where several systems or platforms may employ various character encodings. Syntax:It has the following syntax: Parameters: The following four parameters are required for the function to function: dest: It indicates the pointer to the array containing the wide character that has been translated and stored. Ps: The pointer to the conversion state object is specified by this parameter. Src: The pointer to the first multibyte character to be converted is specified by this parameter. Len: The maximum number of wide characters to store is indicated by this parameter. Return Value: The function yields the following two values:
Program:Let's take an example to illustrate the use of the mbsrtowcs() function in C++. Output: 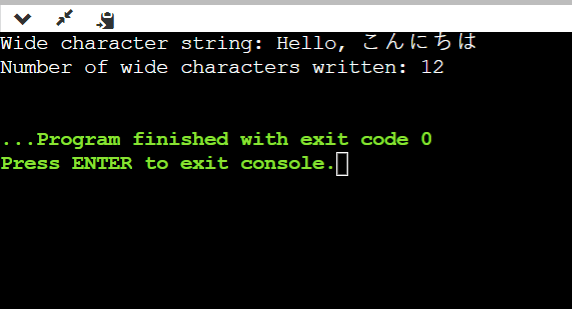
Explanation:
Program 2:Let's take another example to illustrate the use of the mbsrtowcs() function in C++. Output: 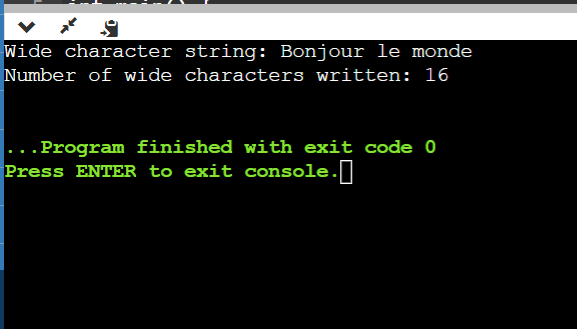
Explanation:
Crucial Things to Remember:Locale Setting: The program's current locale setting may affect how mbsrtowcs() behaves. Using setlocale() function to set the locale suitably is necessary to handle various character encodings properly. Buffer Size: Make sure there is sufficient room in the destination buffer to hold the converted wide characters. State Handling: When working with incomplete multibyte sequences, the mbstate_t object can be used to keep track of the conversion process's current state across different function calls. Conclusion:In conclusion, the mbsrtowcs() function is a useful tool for C/C++ programming handling character encoding conversions. It is essential for supporting internationalization activities, enabling the development of software that must accept several character sets, and guaranteeing the correct handling of diverse encodings. Applications that deal with a variety of character representations might greatly benefit from knowing how to use it and implementing it properly into code.
Next Topicstd::array::crbegin in C++
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








