| |

Unordered_multimap bucket_size() function in C++In the vast realm of C++ programming, the Standard Template Library (STL) stands out as a versatile toolbox filled with powerful features. One such gem within this toolkit is the unordered_multimap container, providing a dynamic way to manage collections of key-value pairs. What is the unordered_multimap?Before we delve into the inner workings of the bucket_size() function, it's crucial to comprehend the unordered_multimap container. This unique container allows for the storage of multiple elements with equivalent keys, offering a quick average complexity for most operations. Its design facilitates efficient data retrieval, making it a go-to choice in scenarios where speedy access to information is paramount. Key Components of unordered_multimap:Within the unordered_multimap universe, elements find their home in buckets based on their keys and the applied hash function. This strategic arrangement enables seamless lookup, insertion, and removal of elements. A deep understanding of the structure of these buckets is essential to harness the true power of this container, leading us to the bucket_size() function. What is the bucket_size()?The bucket_size() function serves as a beacon within the unordered_multimap container, shedding light on the internal organization of elements. The unordered_multimap::bucket_size() is a built-in function in C++ STL, which is used to return the number of elements in the bucket n. Essentially, it reveals the number of elements residing in a specific bucket, offering a valuable matrix to gauge how effectively the hash function is distributing elements across these compartments. Syntax:It has the following syntax: Example:Let us take an example to illustrate the bucket_size() function in C++: Output: 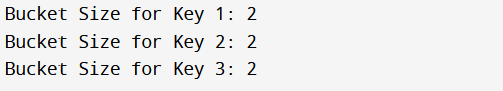
Explanation: In this example, we create an unordered_multimap named myMultimap, inserting key-value pairs and using the bucket_size() function to retrieve the sizes of the buckets corresponding to keys 1, 2, and 3. This straightforward function allows us to peek into the internal organization of elements. Practical Applications and Use Cases:The bucket_size() function proves its worth in various scenarios, showcasing its versatility. Some main practical applications of the bucket_size() in C++ are as follows: 1. Performance Optimization: Insight into the distribution of elements across buckets enables developers to fine-tune hash functions, optimizing performance. Identification of uneven bucket sizes prompts adjustments for a more balanced distribution, averting potential performance bottlenecks. 2. Debugging and Profiling: During development, the bucket_size() function serves as a diagnostic tool to evaluate the efficiency of the hash function. Developers can quickly identify keys leading to unexpected collisions, potentially affecting overall container performance. 3. Algorithm Design: Knowledge of bucket sizes influences algorithm design, especially when dealing with large datasets. Crafting algorithms that leverage the distribution of elements across buckets enhances efficiency and accelerates data retrieval. Considerations and Potential Challenges:While the bucket_size() function is a valuable ally, it's essential to navigate potential pitfalls: 1. Hash Function Quality: The effectiveness of bucket_size() is closely tied to the quality of the hash function used. A well-designed hash function may result in unevenly distributed elements, diminishing the meaningfulness of the information provided. 2. Dynamic Nature of Containers: The unordered_multimap container dynamically adjusts its structure based on the number of elements and the hash function. Information from the bucket_size() function is a snapshot and may change as elements are added or removed. The Real-world Impact of Understanding Bucket Sizes:Taking the theoretical and practical aspects into account, let's explore how a nuanced understanding of bucket sizes can have tangible impacts in real-world programming scenarios. 1. Optimizing Hash Functions for Efficiency: Armed with insights from bucket_size(), developers can iteratively refine their hash functions to achieve a more even distribution of elements. This optimization translates directly into enhanced performance, especially in scenarios with large datasets or frequent data manipulations. 2. Identifying and Resolving Performance Bottlenecks: Bucket sizes can be indicative of potential performance bottlenecks. Developers can ensure that the unordered_multimap operates smoothly even as the volume of data grows by proactively identifying and addressing these disparities. 3. Enhancing Data Retrieval Strategies: Knowledge of bucket sizes allows developers to design algorithms that take advantage of the distribution of elements. Crafting retrieval strategies that align with the organization of buckets can significantly improve the efficiency of data access. 4. Adapting to Dynamic Workloads: In applications with varying workloads, the dynamic nature of the unordered_multimap can be a double-edged sword. Understanding how bucket sizes change dynamically empowers developers to create adaptive algorithms that perform optimally under different usage scenarios. Best Practices and Recommendations:Consider the following best practices to make the most of the bucket_size() function: 1. Regularly Monitor and Analyse Bucket Sizes: Incorporate routine checks of bucket sizes during the development and testing phases. This proactive approach helps catch potential issues early on and ensures the ongoing optimization of the unordered_multimap. 2. Benchmark Different Hash Functions: Experiment with various hash functions to determine which ones result in more balanced bucket sizes. Benchmarking different options allows developers to make informed decisions based on the specific requirements of their application. 3. Document and Share Findings: Documenting the insights gained from the bucket_size() observations is crucial for knowledge-sharing within development teams. Shared knowledge fosters a collaborative environment where the entire team benefits from each member's discoveries and optimizations. Continued Relevance of unordered_multimap and bucket_size():As C++ evolves and technological landscapes shift, the unordered_multimap container, along with the invaluable bucket_size() function, remains a steadfast companion for developers. Its adaptability and efficiency make it well-suited for a variety of applications, from data-intensive projects to real-time systems. Debugging and Iteration:In the creative process of software development, debugging and iteration are integral chapters. The unordered_multimap's bucket_size() function plays a role not just in identifying potential issues but also in the iterative refinement of your code. 1. Debugging as a Creative Challenge: Debugging is similar to solving a puzzle; it requires creativity and an analytical mindset. When faced with unexpected behavior, the insights provided by functions like bucket_size() become tools in your creative arsenal, aiding you in unraveling the intricacies of your code. 2. Iterative Refinement: Writing code is a journey of continuous improvement. The bucket_size() function becomes a guide in the iterative refinement process by offering a glimpse into the internal organization of your unordered_multimap. Each iteration brings you closer to a solution that is not just functional but embodies the elegance and efficiency you strive for. The Human Aspect of Code:Behind every line of code lies the human aspect, the passion, the curiosity, and the collaborative spirit that define the programming community. The unordered_multimap's bucket_size() function is a feature forged by human ingenuity to solve real-world challenges, and it is within the human element that its true impact is felt. 1. Collaboration and Knowledge Sharing: The development community thrives on collaboration and the exchange of knowledge. As you explore the intricacies of C++ containers and functions, sharing your discoveries, challenges, and insights with fellow developers contributes to the collective growth of the community. 2. Mentorship and Learning: Every developer is both a mentor and a learner. Engaging in mentorship and being open to learning from others nurtures an environment where the unordered_multimap's bucket_size() function becomes not just a tool in your toolkit but a shared resource that benefits the entire community. Conclusion:In the intricate landscape of C++ programming, the unordered_multimap container, complemented by the bucket_size() function, emerges as a dynamic duo for managing key-value pairs. This function offers a glimpse into the internal organization of elements and empowers developers with a tool for optimizing performance, debugging, and creating efficient algorithms. C++ development, the unordered_multimap's bucket_size() function emerges not only as a technical tool but as a brushstroke in the hands of creators shaping the digital landscape. A deep understanding of the structure of these buckets is essential to harness the true power of this container, leading us to the bucket_size() function. As you continue to explore the depths of C++ and its STL, the unordered_multimap container and its associated functions stand as beacons of the language's versatility. So, the next time you find yourself navigating the intricacies of unordered associative containers, remember to leverage the Magic encapsulated within the bucket_size() function. It holds the key to unlocking optimal performance and efficiency in your C++ endeavors. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








