| |

Difference between C-LOOK and C-SCAN Disk Scheduling AlgorithmOperating systems do disk scheduling to schedule I/O requests arriving for the disk. Disk scheduling is also known as I/O scheduling. Disk scheduling is important because multiple I/O requests may arrive by different processes, and only one I/O request can be served at a time by the disk controller. Thus other I/O requests need to wait in the waiting queue and need to be scheduled. Two or more requests may be far from each other, resulting in greater disk arm movement. Hard drives are one of the slowest parts of the computer system and thus need to be accessed efficiently. Below are some of the important terms used in disk scheduling, such as:
Many disk scheduling algorithms include FCFS, SSTF, SCAN, C-SCAN, LOOK, C-LOOK, RSS, LIFO, F-SCAN, and N-STEP SCAN. What is C-SCAN Disk Scheduling Algorithm?C-SCAN algorithm, also known as the Circular Elevator algorithm, is the modified version of the SCAN algorithm. In this algorithm, the head pointer starts from one end of the disk and moves towards the other end, serving all requests in between. After reaching the other end, the head reverses its direction and goes to the starting point, and it then satisfies the remaining requests in the same direction as before. Unlike C-LOOK, the head pointer will move till the end of the disk, whether there is a request or not. For example: Consider a disk with 200 tracks (0-199) and the disk queue having I/O requests in the following order as follows: The current head position of the Read/Write head is 53 and will move in the right direction. Calculate the total number of track movements of the Read/Write head using the C-SCAN algorithm. 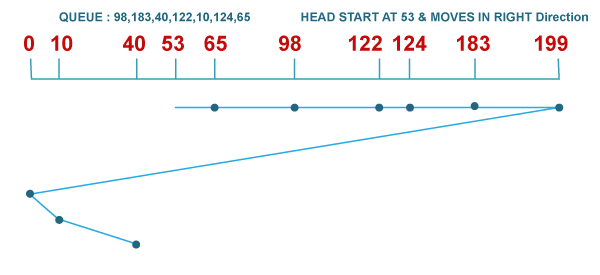
AdvantagesHere are the following advantages of the C-SCAN Scheduling Algorithm, such as:
DisadvantagesC-SCAN Scheduling Algorithm also has some disadvantages, such as:
What is C-LOOK Disk Scheduling Algorithm?C-LOOK is the modified version of both LOOK and C-SCAN algorithms. In this algorithm, the head starts from the first request in one direction and moves towards the last request at another end, serving all requests in between. After reaching the last request in one end, the head jumps in another direction, moves towards the remaining requests, and then satisfies them in the same direction as before. Unlike C-SCAN, the head pointer will move till the end request of the disk. For example: Consider a disk with 200 tracks (0-199) and the disk queue having I/O requests in the following order as follows: The current head position of the Read/Write head is 53 and will move in the right direction. Calculate the total number of track movements of the Read/Write head using the C-LOOK algorithm. 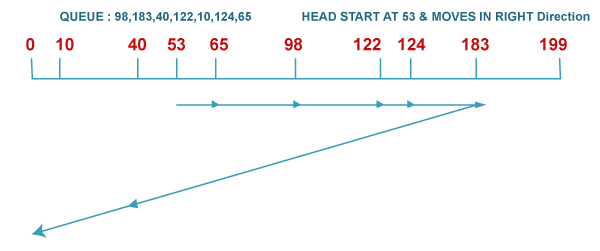
Advantages of C-LOOK Disk Scheduling AlgorithmHere are the following advantages of the C-LOOK Disk Scheduling Algorithm, such as:
Disadvantages of CLOOK Disk Scheduling AlgorithmCLOOK Disk Scheduling Algorithm has some disadvantages, such as:
Difference between C-LOOK and C-SCAN Disk Scheduling AlgorithmThese algorithms are so similar but here are the following differences between C-LOOK and C-SCAN disk scheduling algorithm, such as:
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








