Spooling in Operating System
In Operating System, we had to give the input to the CPU, and the CPU executes the instructions and finally gives the output. But there was a problem with this approach. In a normal situation, we have to deal with many processes, and we know that the time taken in the I/O operation is very large compared to the time taken by the CPU for the execution of the instructions. So, in the old approach, one process will give the input with the help of an input device, and during this time, the CPU is in an idle state.
Then the CPU executes the instruction, and the output is again given to some output device, and at this time, the CPU is also in an idle state. After showing the output, the next process starts its execution. So, most of the time, the CPU is idle, which is the worst condition that we can have in Operating Systems. Here, the concept of Spooling comes into play.
What is Spooling
Spooling is a process in which data is temporarily held to be used and executed by a device, program, or system. Data is sent to and stored in memory or other volatile storage until the program or computer requests it for execution.
SPOOL is an acronym for simultaneous peripheral operations online. Generally, the spool is maintained on the computer's physical memory, buffers, or the I/O device-specific interrupts. The spool is processed in ascending order, working based on a FIFO (first-in, first-out) algorithm.
Spooling refers to putting data of various I/O jobs in a buffer. This buffer is a special area in memory or hard disk which is accessible to I/O devices. An operating system does the following activities related to the distributed environment:
- Handles I/O device data spooling as devices have different data access rates.
- Maintains the spooling buffer, which provides a waiting station where data can rest while the slower device catches up.
- Maintains parallel computation because of the spooling process as a computer can perform I/O in parallel order. It becomes possible to have the computer read data from a tape, write data to disk, and write out to a tape printer while it is doing its computing task.
How Spooling Works in Operating System
In an operating system, spooling works in the following steps, such as:
- Spooling involves creating a buffer called SPOOL, which is used to hold off jobs and data till the device in which the SPOOL is created is ready to make use and execute that job or operate on the data.
- When a faster device sends data to a slower device to perform some operation, it uses any secondary memory attached as a SPOOL buffer. This data is kept in the SPOOL until the slower device is ready to operate on this data. When the slower device is ready, then the data in the SPOOL is loaded onto the main memory for the required operations.
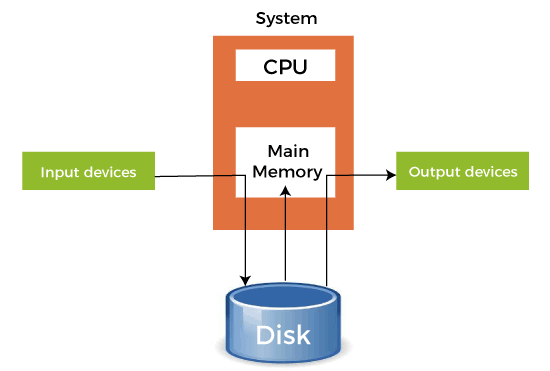
- Spooling considers the entire secondary memory as a huge buffer that can store many jobs and data for many operations. The advantage of Spooling is that it can create a queue of jobs that execute in FIFO order to execute the jobs one by one.
- A device can connect to many input devices, which may require some operation on their data. So, all of these input devices may put their data onto the secondary memory (SPOOL), which can then be executed one by one by the device. This will make sure that the CPU is not idle at any time. So, we can say that Spooling is a combination of buffering and queuing.
- After the CPU generates some output, this output is first saved in the main memory. This output is transferred to the secondary memory from the main memory, and from there, the output is sent to the respective output devices.
Example of Spooling
The biggest example of Spooling is printing. The documents which are to be printed are stored in the SPOOL and then added to the queue for printing. During this time, many processes can perform their operations and use the CPU without waiting while the printer executes the printing process on the documents one-by-one.
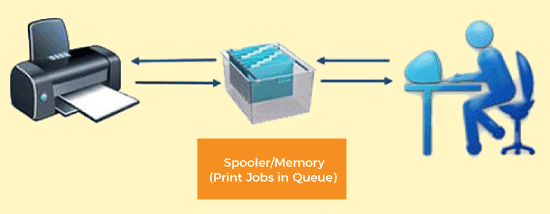
Many features can also be added to the Spooling printing process, like setting priorities or notification when the printing process has been completed or selecting the different types of paper to print on according to the user's choice.
Advantages of Spooling
Here are the following advantages of spooling in an operating system, such as:
- The number of I/O devices or operations does not matter. Many I/O devices can work together simultaneously without any interference or disruption to each other.
- In spooling, there is no interaction between the I/O devices and the CPU. That means there is no need for the CPU to wait for the I/O operations to take place. Such operations take a long time to finish executing, so the CPU will not wait for them to finish.
- CPU in the idle state is not considered very efficient. Most protocols are created to utilize the CPU efficiently in the minimum amount of time. In spooling, the CPU is kept busy most of the time and only goes to the idle state when the queue is exhausted. So, all the tasks are added to the queue, and the CPU will finish all those tasks and then go into the idle state.
- It allows applications to run at the speed of the CPU while operating the I/O devices at their respective full speeds.
Disadvantages of Spooling
In an operating system, spooling has the following disadvantages, such as:
- Spooling requires a large amount of storage depending on the number of requests made by the input and the number of input devices connected.
- Because the SPOOL is created in the secondary storage, having many input devices working simultaneously may take up a lot of space on the secondary storage and thus increase disk traffic. This results in the disk getting slower and slower as the traffic increases more and more.
- Spooling is used for copying and executing data from a slower device to a faster device. The slower device creates a SPOOL to store the data to be operated upon in a queue, and the CPU works on it. This process in itself makes Spooling futile to use in real-time environments where we need real-time results from the CPU. This is because the input device is slower and thus produces its data at a slower pace while the CPU can operate faster, so it moves on to the next process in the queue. This is why the final result or output is produced at a later time instead of in real-time.
Difference between Spooling and Buffering
Spooling and buffering are the two ways by which I/O subsystems improve the performance and efficiency of the computer by using a storage space in the main memory or on the disk.
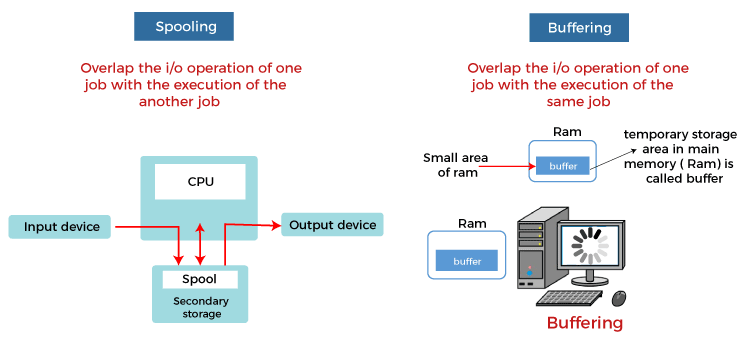
The basic difference between Spooling and Buffering is that Spooling overlaps the I/O of one job with the execution of another job. In comparison, the buffering overlaps the I/O of one job with the execution of the same job. Below are some more differences between Spooling and Buffering, such as:
| Terms |
Spooling |
Buffering |
| Definition |
Spooling, an acronym of Simultaneous Peripheral Operation Online (SPOOL), puts data into a temporary working area to be accessed and processed by another program or resource. |
Buffering is an act of storing data temporarily in the buffer. It helps in matching the speed of the data stream between the sender and receiver. |
| Resource requirement |
Spooling requires less resource management as different resources manage the process for specific jobs. |
Buffering requires more resource management as the same resource manages the process of the same divided job. |
| Internal implementation |
Spooling overlaps the input and output of one job with the computation of another job. |
Buffering overlaps the input and output of one job with the computation of the same job. |
| Efficient |
Spooling is more efficient than buffering. |
Buffering is less efficient than spooling. |
| Processor |
Spooling can also process data at remote sites. The spooler only has to notify when a process gets completed at the remote site to spool the next process to the remote side device. |
Buffering does not support remote processing. |
| Size on memory |
It considers the disk as a huge spool or buffer. |
Buffer is a limited area in the main memory. |
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








