| |

Genes StructureIntroductionIn order to understand the details of a gene structure, one needs to be thorough with the concept of genes, DNA, and chromosomes and how the three are interrelated. Let us learn about each of them in detail, starting with genes. In simple words, A gene is a small segment or stretch of DNA which is the basic unit of heredity and contains physical characteristics that make each person unique. Every gene consists of some specific set of instructions required for a specific function or protein coding. Genes are basically responsible for passing down information in the form of protein-coding, from the parental generation to the offspring. They vary in size based on the code or the protein they form. In 1905, William Bateson introduced the term "genetics" and four years later, botanist Wilhelm Johannes introduced the term "gene" to represent hereditary traits. There are approximately 30,000 genes in a single cell of the human body. They are located inside the nucleus of the cell, constrained within the chromosomes in the form of a chromatic network (which is a network of DNA wrapped around histone molecules to form a "beads on a string" structure). DNA and ChromosomesDNA, which is short for deoxyribonucleic acid, is a long polymer made up of deoxyribonucleotides and its length depend upon the number of nucleotides (a pair of nucleotide refers to a base pair, A with T, and G with C) present in the DNA. DNA also refers to the characteristics present in an organism. Some organisms contain RNA instead of DNA as their hereditary material, such as viruses. In the nucleus of each cell inside a human body, chromosomes are present which are made up of DNA molecules that are coiled up in a thread-like structure forming a chromatin network. The DNA is coiled around protein structures called histones that support the DNA. A set of eight histone structures are joined together known as histone octamers and a long chain of these octamers makes up the chromatic network which further coils to form the chromosomes. It is important to understand the relationship between genes, DNA, and chromosomes. Chromosomes are structures in the nucleus that contain DNA in a coiled form wrapped around protein structures called histones. A gene structure is nothing but a segment of the DNA helix in its uncoiled form. The structure is very minute and is only visible on a high-powered electron microscope. Structure of DNAThe structure of DNA looks similar to a twisted ladder as it consists of two strands that are linked with and wind around each other- a structure known as a double helix. DNA is mainly made up of nucleotide monomers and exists as a double helix with double strands running in opposite directions bonded by hydrogen bonds. Each strand is supported with the help of a backbone that basically contains alternating sugar (deoxyribose or ribose) along with phosphate groups. Each sugar is attached to one of the four bases (also known as nucleotides) present in a DNA structure, namely: adenine (A), cytosine (C), guanine (G), or thymine (T). The two strands of DNA are linked with each other with the help of chemical bonds that are formed between these four bases- adenine bonds with thymine (A-T) whereas cytosine bonds with guanine (C-G). Adenine forms 2 hydrogen bonds with thymine, on the other hand, cytosine forms 3 hydrogen bonds with guanine. Biological information, such as the instructions necessary for making an RNA molecule or a protein, is encoded depending on the sequence of the base pairs along the backbone of the DNA. Organisation of Genes within a ChromosomeAs we have discussed above, a chromosome comprises a long-coiled chromatin structure made up of DNA and protein and contains a large number of genes (even hundreds to thousands). The genes are perfectly arranged on each chromosome in a particular sequence, with each gene having its particular position on the chromosome, known as its locus. In addition to DNA, there are other chemical components present inside a chromosome such as protein structures and other components that influence the functioning of the genes. Genes and TranscriptionTranscription basically refers to rewriting a given information. Whenever we rewrite certain information, it changes in structure more or less. Something similar happens to our cells as well. The process of transcription involves the copying of a DNA sequence of a gene in order to form an RNA molecule. It is the first and foremost step in gene expression and involves copying a gene's DNA sequence so that a copy of it can be made in the form of an RNA molecule. In the case of a protein-coding gene, the copy of RNA known as a transcript within it is the information required to build a polypeptide (protein subunit or protein). However, in the case of eucaryotic transcripts, there are several steps that need to be followed before the process of translation into proteins takes place. RNA PolymeraseThe process of transcription is not an easy one as it involves a number of complicated steps. An enzyme called RNA polymerase is used to perform transcription, which works by linking the nucleotides to make an RNA strand while using the existing DNA strand as a template. A single DNA strand is read in the 3' to 5' direction and used as a template to synthesize a complementary RNA strand in the 5' to 3' direction while adding a new nucleotide to the 3' end of the new strand. The two strands, both the template strand and the new RNA strand are antiparallel to each other. Stages of TranscriptionThe process of transcription is generally completed in three important steps namely: initiation, elongation, and termination. Here is a detailed explanation of these processes- 1. Initiation: The process of initiation is the first step in the process of transcription. In this step, the enzyme RNA polymerase binds itself to a sequence of DNA known as the It is situated near the beginning of a gene and each gene contains its own promoter. Once the enzyme binds itself to the DNA, it separates the DNA strand to obtain a single DNA thread required to continue the process of transcription. The promoter region is situated right before (and slightly overlaps) the region of transcription which it specifies. The promoter region helps RNA polymerase to bind to it by providing recognition sites as well as helper proteins for RNA polymerase to bind. The closed DNA helix opens up so that RNA polymerase can begin transcription. 2. Elongation: Out of the two strands that are separated by RNA polymerase, one strand of DNA, the template strand, works just as the name suggests. It acts as a template for the enzyme RNA polymerase and it "reads" one base at a time. The enzyme builds a complementary RNA molecule made up of nucleotides which are basically the same as the coding strand and are complementary to the template strand, forming a chain that goes from 5' to 3'. The RNA transcript contains the same information as that of the non-coding strand of the DNA, with only having uracil (U) as a nucleotide in place of thymine (T) as the latter doesn't exist in RNAs. The enzyme continues opening up the helix as it goes further in the 3' to 5' direction. The RNA, transcribed in the process of elongation, only stays bound with the template strand for a short period of time and soon detaches itself from the DNA as a dangling string, allowing the template strand and non-coding strand to close up again and form a double helix. 3. Termination: There are sequences in the DNA helix that are known as terminators that are responsible for putting an end to the process of transcription. They are segments that indicate that the RNA transcript has finished. They trigger the release of the transcript from the RNA polymerase enzyme after it has been transcribed. A section of RNA which generates a hairpin structure that is followed by a sequence of U nucleotides is encoded by the terminator DNA. The RNA polymerase stalls because of the transcript's hairpin-like shape. The U nucleotides that precede the hairpin create weak bonds with the DNA template's A nucleotides, making the transcript break free from the DNA strand and putting an end to transcription. Eukaryotic RNA ModificationsIn primitive organisms like bacteria, the transcribed RNA strands act as messenger RNAs (mRNAs) immediately after transcription. This is not the case with complex organisms such as eukaryotes as in their case, the transcribed RNA is known as pre-mRNA and requires some extra processing before it can move to the process of translation. In eukaryotic organisms, the pre-mRNA must undergo modifications on both ends. A 5' cap must be added at the beginning of the transcribed RNA along with a 3' poly-A tail at the end. A number of eukaryotic organisms undergo a process called splicing. Splicing occurs with lots of eukaryotic pre-mRNAs where the pre-mRNA's introns (which are the non-coding sequences) are removed during this process, and the exons (which are the coding sequences) that remain are then joined back together The process of splicing provides the mRNA with its proper sequence, whereas end modifications enhance the mRNA's stability. (In case the introns are left in their place and aren't removed, they will translate together with the exons and result in an "absurd" polypeptide.) Introns and ExonsMost of a gene's sequence is made up of repeated and untranslated regions that help regulate gene expression. These types of repeating sections are known as introns and only a small portion of the gene sequence is protein-coding, known as called exons. The introns are the noncoding portions of a transcribed RNA strand or the DNA that encodes it. These sections are cut out with the process of splicing before the RNA transcript is taken further for the process of translation. On the other hand, the coding sections of DNA (or RNA) are exons, they remain intact for the translation process so that they can code for proteins. Genes Types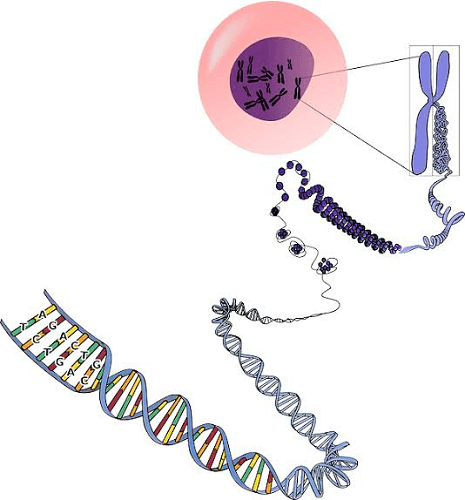
i) Eukaryotic GenesEukaryotic genes have exceptional features not found in prokaryotes, mainly related to post-transcriptional modification of pre-mRNAs. They also have more regulatory elements regulating gene expression, specifically in multicellular eukaryotes like human beings, where gene expression ranges widely among different tissues. Eukaryotic genes have transcripts that are divided into exon and intron regions. Exons remain in the final mRNA molecule while introns are spliced out during post-transcriptional processing, even though they can be longer than exons. The splice boundaries between exons are not detectable once spliced together to form a continuous protein-coding region. Also, it is interesting to note that Eukaryotic post-transcriptional processing adds a 5' cap to the beginning of mRNA and a poly-adenosine tail to its 3' end. It helps in stabilizing it and directing transport from the nucleus to the cytoplasm without being encoded in gene structure. ii) Prokaryotic GenesProkaryotic genes are arranged differently from those of eukaryotes, with ORFs (open reading frames) commonly grouped into a polycistronic operon under the control of shared regulatory sequences. These ORFs are transcribed onto the identical mRNA and therefore co-regulated, frequently serving related functions. Each ORF has its individual ribosome binding site (RBS), permitting simultaneous translation on a similar mRNA. Few operons display translational coupling where multitudinous ORFs' translation rates inside an operon are connected. It is only probable in prokaryotes owing to their transcription and translation happening simultaneously and in identical subcellular locations. ConclusionGenes are known as the basic developmental and functional units of heredity and are made up of specialized sequence elements that identify the function of the gene. These sequences are organized in a gene's structure, which involves most of the information essential for cells to survive and reproduce. Genes are composed of DNA, which carries the necessary information for cells to reproduce and the function of a gene is identified by its particular DNA sequence. The understanding of gene structure is very important, not just in genetics but in various other sub-divisions of biology such as molecular biology and medicine as well.
Next TopicSupergenes
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








