| |

Data Augmentation in Machine LearningIn machine learning, data augmentation is a common method for manipulating existing data to artificially increase the size of a training dataset. In an attempt to enhance the efficiency and flexibility of machine learning models, data augmentation looks for the boost in the variety and volatility of the training data. Data augmentation can be especially beneficial when the original set of data is small as it enables the system to learn from a larger and more varied group of samples. 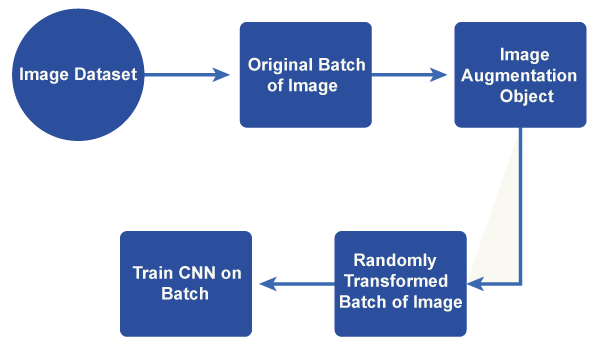
By applying arbitrary changes to the information, the expanded dataset can catch various varieties of the first examples, like various perspectives, scales, revolutions, interpretations, and mishappenings. As a result, the model can better adapt to unknown data and become more resilient to such variations. Techniques for data augmentation can be used with a variety of data kinds, including time series, text, photos, and audio. Here are a few frequently used methods of data augmentation for image data:
Types of Data AugmentationsReal Data AugmentationThe process of modifying real-world data samples to enhance the base of training for artificial intelligence models is referred to as "real data augmentation." Real data augmentation, as compared to synthetic data augmentation produces new samples based on existing data and also modifies the original data in a way that accurately depicts fluctuations and disturbances that occur in the real world. By capturing the inherent diversity in the data distribution, real data augmentation approaches strive to strengthen the model's adaptability to various scenarios, noise levels, or environmental factors. Here are some actual data augmentation approaches as examples: i) Sensor noise: By adding noise to sensor data, measurement errors or other flaws in the data collection process can be simulated. For instance, adding random Gaussian noise to camera-taken pictures can simulate the sensor noise found in actual image data. ii) Occlusion: Blocking or partially occluding specific areas of an image might imitate the presence of objects or barriers that are hiding certain areas of the scene. With the aid of this augmentation technique, models are made more resistant to occlusions and are better equipped to deal with partial or blocked visual information. iii) Weather: Simulating various weather conditions, including snow, rain, or fog, might make the model more resistant to changes in exterior settings. For instance, adding filters or overlays to photographs might make it appear as though it is raining or foggy. iv) Time series perturbations can imitate temporal changes and uncertainties in the actual world by altering time series data by adding variations like shifts, scaling, or warping. For activities involving sequential data, such as readings from sensors or financial data, this augmentation strategy can be helpful. v) Label smoothing: In some circumstances, real data enhancement may also entail introducing noise to the labels or target values connected to the data samples. Label smoothing supports more reliable predictions by preventing models from overfitting to certain values. Synthetic Data AugmentationIn machine learning, synthetic data augmentation creates additional artificial data samples based on current data to increase the training set. It is a method for broadening the variety and volume of data accessible for model training. When a dataset is scarce or more variations are required to boost a model's performance, synthetic data augmentation can be especially helpful. Here are a few typical methods for artificial data augmentation: Image synthesis: When dealing with computer vision problems generative models like Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) can be employed to create new images by combining old ones, using filters or transformations, or even using other techniques. By producing new versions of objects, scenes, or textures, this technique can create duplicates of the original data. Text generation: In natural language processing tasks, synthetic data augmentation can entail generating new phrases or text samples from existing data. Language models, sequence-to-sequence models, and rule-based approaches can all help with this. Synthetic text data can help improve the model's grasp of diverse sentence forms by increasing the diversity of language patterns. Oversampling and undersampling: When dealing with imbalanced classification situations in which certain classes are underrepresented in the training data, synthetic data augmentation may include oversampling the minority class or undersampling the majority class. To balance the class distribution, synthetic examples are constructed by duplicating or generating new instances. This reduces the model's bias towards the majority class and enhances its capacity to handle imbalanced data. Data interpolation and extrapolation: By interpolating or extrapolating existing data samples, synthetic data can be formed. Interpolation involves the generation of new samples that sit between existing data points, whereas extrapolation generates samples that are outside the original data's range. This strategy can assist models learning to predict in previously undiscovered regions of the input space. Feature perturbation: In synthetic data augmentation, the features or input variables of current data samples can be changed. This can be accomplished by using random noise, transformations, or modifying certain feature values within a legal range. Feature perturbation makes models more resistant to fluctuations in input and increases generalization. Challenges Faced by Data AugmentationSome of the difficulties associated with data augmentation in machine learning include:
Addressing these challenges necessitates careful consideration of the task's specific requirements, domain expertise, and robust validation techniques to ensure that data augmentation improves model performance without introducing biases or jeopardizing the training process's integrity. ConclusionTo summarise, data augmentation is a strong machine-learning strategy that can improve model performance and robustness by increasing the training dataset. Data augmentation helps models develop more generalized representations and increases their ability to manage changes in real-world data by creating different samples through transformations. However, data augmentation introduces issues that must be carefully addressed. To select relevant augmentation strategies, domain-specific expertise is required. Maintaining label integrity is critical to ensuring that the augmented data retains the correct annotations. Overfitting can happen if the augmentation is excessively forceful or not appropriate for the job, resulting in poor generalization. The computational burden of supplementing huge datasets should also be considered. Overall, data augmentation can be a valuable technique in machine learning when utilized efficiently and with care, allowing models to learn from a bigger and more diversified dataset, resulting in increased performance and greater generalization on unknown data. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








