| |

Data Leakage in Machine LearningData is one of the most critical factors for any technology. Similarly, data plays a vital role in developing intelligent machines and systems in machine learning and artificial intelligence. In Machine Learning, when we train a model, the model aims to perform well and give high prediction accuracy. However, imagine the situation where the model is performing exceptionally well. In contrast, testing, but when it is deployed for the actual project, or it is given accurate data, it performs poorly. So, this problem mainly occurs due to Data Leakage. Data leakage is one of the main machine Learning errors and can affect the overall production performance and validation accuracy of the model to a great extent. 
In this topic, we will discuss data leakage problems in predicting modeling, causes of data leakage, solutions to minimize data leakage problems in prediction modeling, etc. Before starting this topic, it is required to have a good understanding of Prediction Modelling. So, let's start with the basics of predictive modeling in machine learning first. What is Predictive Modelling?Predictive modeling is one of the most famous data analytics and statistical techniques that use machine learning and data mining to predict results using experience or historical data. In simple words, predicting modeling is a statistical technique used to predict future behavior by generating an intelligent model. There are plenty of data sources used to create predictive models in machine learning as follows:
Types of Predictive Models in Machine LearningThere are a few commonly used predictive models, which are as follows:
The goal of Predictive ModellingThe main goal of predictive modeling is to create a robust and well-performing model which can provide accurate results on new data sets during the training process. This procedure is complicated because you cannot directly evaluate the model predictions on unseen datasets. Therefore, we should estimate the model's performance on unseen data by training it on only some of the data we have and evaluating it on the rest of the data. Now, after understanding the concept of predicting modeling in machine learning. It's time to move on to the main topic; hence let's start with an introduction to Data leakage in machine learning. What is Data Leakage in Machine Learning?Data leakage is one of the major problems in machine learning which occurs when the data that we are using to train an ML algorithm has the information the model is trying to predict. It is a situation that causes unpredictable and bad prediction outcomes after model deployment. In simple words, data leakage can be defined as: "A scenario when ML model already has information of test data in training data, but this information would not be available at the time of prediction, called data leakage. It causes high performance while training set, but perform poorly in deployment or production." Data leakage generally occurs when the training data is overlapped with testing data during the development process of ML models by sharing information between both data sets. Ideally, there should not be any interaction between these data sets (training and test sets). Still, sharing data between tests and training data sets is an accidental scenario that leads to the bad performance of the models. Hence, creating an ML predictive model always ensures that there is no overlapping between the training data and the testing data. Why does data Leakage happen?As discussed earlier, a data leakage problem generally occurs when training data already has information about what the model is trying to predict. Although this scenario looks like cheating but in technical words, we call it leakage, as it is an accidental scenario. Data leakage is one of the significant issues in ML, which must be resolved to obtain a robust and generalized predictive model. Now, let's understand the reason for data leakage in a better manner.
How do we detect the Data Leakage problem in Machine Learning?Data leakage is an error that occurs during the creation of predictive models in machine learning. Although we can identify the problem of data leakage by checking the test and training data sets, it can be a bit complex for you. So, here we will discuss a few important cases to detect data leakage problems and avoid them. These are as follows: Case -1: Firstly, if we find that our model is performing very well, i.e., predicted outcome and actual outcomes are the same, then we must get suspicious of the occurrence of data leakage problem. In such cases, the model memorizes the relations between training data and test data instead of generalizing on the unseen data. Hence, we should always compare the predicted and training results before proceeding further. Case-2: While performing Exploratory Data Analysis EDA, we may find some highly correlated features with the target variable. Although some features can be more correlated than others, if there is an exceptionally high correlation between them, it should be checked to avoid data leakage. We must check those highly correlated features with extra attention. Case-3: After building the model, check if there is some unusual feature behavior in the fitted model. For example, exceptionally high feature weights or extensive information associated with a variable. Further, we should check for the model's overall performance, i.e., if it is unexpected. It means we need to look carefully at the events and features that have a high impact on the model if the results of the model's evaluation are significantly greater than those of similar or comparable situations and datasets. How to Fix Data Leakage Problem in Machine Learning?Data leakage problems can be severe for any model prediction, but we can fix or avoid data leakage using tips and tricks.
Let's discuss these tips in a detailed manner to minimize or fix data leakage problems in machine learning. 1. Extract the appropriate set of features: We can try this method for an ML model to fix the data leakage issue. To extract the appropriate set of features, we must ensure that the given features are not overlapped with the given target variable, or there should not be any interaction between both. 
2. Add an individual validation set: We can also minimize the data leakage problem by adding a validation set to both training and test data sets. Further, the validation set also helps identify the overfitting, which acts as a caution warning when deploying predictive models. 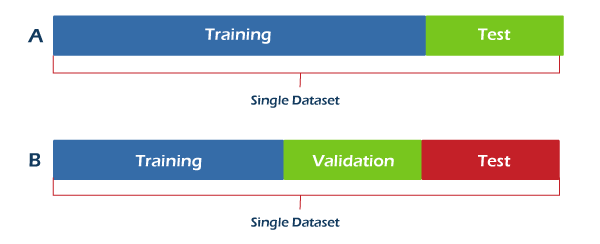
3. Apply data pre-processing separately to both data sets: When working with neural networks, generally, the input data is normalized before introducing into the model. In general, data normalization is done by dividing the data by its mean value, and then it is applied to entire data sets. This results in the overlapping of training data sets with test data sets, which causes data leakage issues in the model. 
Hence, to minimize or avoid leakage problems, we should apply normalization methods to both data sets separately instead of simultaneously. 4. Time-series data: When working with time-series data, we should have more attention to data leakage issues in the models. Data leakage in time-series data is due to randomly splitting into test and training data sets. To minimize the data leakage in time-series data, always put a cut-off value on time as it helps you avoid getting any information after the time of prediction. 5. Cross-Validation: Cross-validation is a mechanism to train machine learning algorithms with limited data during the training process. In this method, our complete data set is split into k folds and iterated for k times on the entire data set. Further, it uses k-1 folds for training purposes and rests folds for testing the model. 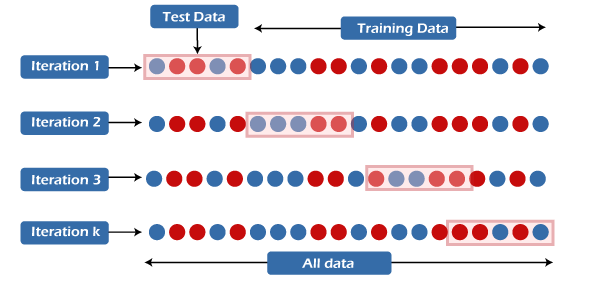
The main goal of using cross-validation is to utilize the entire dataset for training and testing the models during this process. If any data leakage occurs, use normalization methods and compute the parameters on each cross-validation fold separately. ConclusionData leakage can be considered a severe issue when developing any model in machine learning. Also, it became a widespread problem in the domain of predictive analytics. Machine learning is one of the most popular technologies in the entire world, aiming to create intelligent machines for better future outcomes using historical data or experience. So, to get better results, we need a well-generalized model. Still, the data leakage issue restricts a model from getting generalized-this result inaccurate predictions, incorrect assumptions, and reduced model performance. Although we have discussed various fixing steps for data leakage problems in the predictive model on this topic, we need to focus more on detecting and combating data leakage issues to create a robust and generalized model. Hence, we can conclude that if you have a clear understanding of data leakage problems and techniques to avoid them, you will only have a good command of real-life project scenarios. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








