| |

Kubernetes - load balancing serviceKubernetes, the container orchestration platform, is critical in tackling the issues brought by Microservices adoption in many enterprises. Companies increasingly manage numerous small containers across multiple platforms using Microservices, which can lead to performance concerns if network management and resource allocation are not managed appropriately. However, these issues are no longer a worry when scalability and availability are successfully managed. 
Load balancing is critical for making the most of Kubernetes. Load balancing not only protects users from unresponsive services and apps, but it also functions as an invisible mediator between a collection of servers and clients, ensuring that connection requests are handled promptly. This article will look at the basics of load balancing, its benefits, and how to integrate it with Kubernetes. You will also learn how to properly manage requests within Kubernetes setups. What is Load Balancing in Kubernetes?During peak times, websites and business apps must handle many queries. Furthermore, businesses distribute the burden across multiple servers to fulfill this demand. Apart from cost benefits, it also allows for an even distribution of demand across all servers. This load balancing keeps a single server from going down. Due to business and user requirements, all current apps cannot function without it. Load balancing in Kubernetes is an important part of operating containerized apps in a Kubernetes cluster. Kubernetes is an open-source container orchestration technology that automates containerized application deployment, scaling, and management. Load balancing in Kubernetes serves a similar purpose, ensuring that traffic is distributed evenly across numerous containers or pods executing your application. Servers might be located on-site, in the cloud, or a data center. They can be virtual, physical, or a combination of the two. To that aim, load balancing must function across multiple platforms. In any scenario, you must maximize production while minimizing response time. Consider load balancing as a "traffic cop" operation. The "traffic cop," in this instance, routes incoming requests and data across all servers. In this case, the "cop" guarantees that no single server is overworked and restores order to an otherwise chaotic scenario. If a server fails, the load balancer instantly redirects traffic. When you add a new server to the pool, the load balancer allocates its resources automatically. To that aim, automatic load balancers ensure your system remains operational during upgrades and maintenance procedures. Advantages of Load balancingNow that you're familiar with load-balancing fundamentals let's look at the advantages. High Availability: Load balancing ensures that your applications and services continue functioning even if some of your servers or resources fail. It decreases the risk of downtime due to hardware breakdowns or other issues by dividing incoming traffic over different servers or resources. Support for Traffic During Peak Hours: Load balancers can efficiently handle increased traffic during peak hours. They spread incoming requests over numerous servers, preventing any single server from getting overburdened and ensuring a quick response to user demands. When putting out new features or upgrades, load balancing allows you to route some of your traffic to the new version (canary release) while maintaining most traffic on the stable version. Blue or Green Releases: Load balancing is critical when executing different versions of an application in separate contexts (for example, blue for the current version and green for the new version). It assists you in smoothly transitioning traffic between various settings, minimizing systemwide slowdowns during the transfer. Load balancing ensures a smooth transition while migrating infrastructure or switching platforms. It allows you to progressively transition traffic to the new infrastructure without disrupting service. Predictive Analytics: Monitoring and analytics capabilities are frequently included in load balancers. They can monitor user traffic patterns and performance indicators, allowing you to make informed decisions based on real-time information. You can proactively use predictive analytics to alter your load-balancing configuration to handle shifting traffic volumes. Flexibility in Maintenance Tasks: During routine maintenance or updates, load balancers can redirect user traffic away from the servers that are being serviced. This reduces service interruptions and downtime, allowing users to continue using your services while maintenance activities are completed. Load balancing is an important component of modern IT infrastructure, providing various benefits such as increased availability, scalability, and flexibility. It is critical in providing a consistent user experience and the smooth running of applications and services, particularly in dynamic and high-demand contexts. External load balancingLoad balancing is an important part of controlling traffic and guaranteeing the availability and stability of your applications in Kubernetes. Kubernetes includes numerous ways for balancing the load for services exposed to external connections. Let's go over the important phrases and concepts in Kubernetes load balancing: Service: Kubernetes services aggregate a set of pods under a common name and give consistent IP addresses. They serve as the entry point for external customers, dispersing traffic throughout the service's pods. In Kubernetes, services are a crucial building piece for load balancing. Pods: Pods are Kubernetes' smallest deployable units, representing one or more containers in the same network namespace. Pods isolate application-specific environments, making them ideal for microservice deployment. Each pod has its IP address and houses the application containers. LoadBalancer: A LoadBalancer service type in Kubernetes allows you to expose a service directly to the internet. It often interfaces with cloud provider load balancers to distribute incoming traffic to the service's pods. This service provides a stable endpoint for external communication and supports protocols such as TCP, gRPC, HTTP, UDP, etc. Ingress: An ingress is a higher-level resource that works as a smart router for HTTP and HTTPS traffic. Ingress resources specify traffic routing rules and offer services such as SSL termination, name-based virtual hosting, and path-based routing. Ingress controllers, such as Nginx, HAProxy, or Traefik, put the rules defined in Ingress resources into action. Ingress Controller: An Ingress Controller is a Kubernetes cluster component that implements the rules set in Ingress resources. It converts these rules into configuration settings for the load-balancing software of choice (e.g., Nginx) to manage traffic following the established routing rules. Ingress Rules: Ingress resources are rules that govern how external users can gain access to services. Path-based routing, host-based routing, SSL/TLS termination, and other customization options are included in these rules. Ingress provides finer-grained control over load balancing than a basic LoadBalancer service. Service Mesh: A service mesh is a network infrastructure layer that manages communication between microservices in a Kubernetes cluster. It is not directly addressed in this article. Service meshes, such as Istio or Linkerd, offer sophisticated functionality for microservices, such as load balancing, traffic management, security, and observability. In summary, depending on the specific requirements of your applications, Kubernetes supports many ways for load balancing, such as LoadBalancer services and Ingress resources. Understanding these principles and how they interact is critical for properly handling external traffic and maintaining your Kubernetes-based applications' scalability and dependability. Load Balancing using a Service Mesh Load Balancing using a Service MeshA service mesh aids in the management of all service-to-service communications. In your scenario, you can utilize it to monitor data because it is on the crucial path for every request being processed. 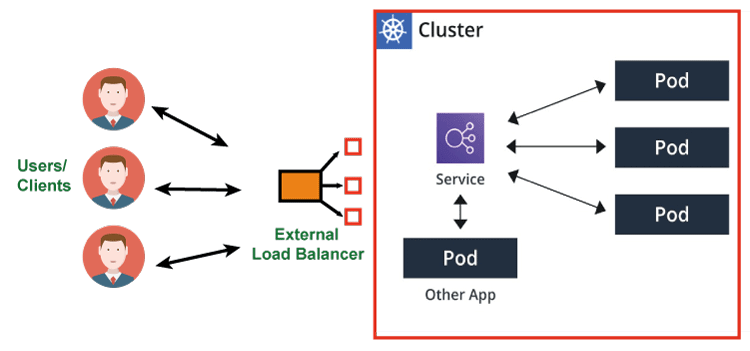
Service meshes can assist you in managing traffic within your cluster. In other words, it adds a new process that handles load balance requests to your application. In terms of service meshes, they examine protocols and automatically discover IP address services. Service meshes, like gRPC, inspect connections. Load Balancing Algorithms: Load balancing inside a service mesh is not a chance operation. Sophisticated algorithms are used. These algorithms function similarly to traffic controllers, analyzing data throughput and making smart decisions about route traffic throughout your network. The main goal is to guarantee that requests are distributed, balanced, and efficient. Resilience and Fault Tolerance: Service mesh is also your safety net regarding resilience and fault tolerance. It is intelligent enough to recognize unhealthy resources and make real-time decisions to slow or reroute traffic away from those locations. This proactive load-balancing method ensures that your services stay resilient and responsive. It's similar to having a smart traffic controller that can dynamically reroute traffic to keep your system running smoothly. Risk Reduction: Unbalanced network loading is a big risk that might result in system downtime. This is where the service mesh comes in to help limit the danger. It decreases the chances of overloading any single component by carefully controlling the traffic flow and constantly altering paths, improving the overall stability of your system. The policy used by service meshNow, let's look at some of the policy types used by the service mesh for load balancing. These policies are critical for optimizing the performance of your system: Round Robin: This policy distributes requests evenly among healthy instances, ensuring a fair load distribution. Least Connections: It routes traffic to the instance with the fewest active connections, optimizing resource efficiency. Weighted Routing: This policy allows you to set different weights to instances and control the proportion of traffic received by each one. Circuit Breaker: A critical resilience policy that prevents cascade failures by momentarily limiting traffic to unhealthy instances until they recover. Retry and Timeout Policies: These policies define how the service mesh handles unsuccessful requests, allowing for retries while imposing timeout restrictions on responsiveness. A service mesh is a reliable ally in the complex dance of service-to-service communication. It not only adds intelligence to load balancing but also increases your applications' resilience and dependability, making it an essential component of modern microservices architectures. Policies for Load BalancingLet's look at three key rules for load balancing, each with its unique manner of intelligently and efficiently controlling traffic distribution. Consider the following three types of policies: Round Robin: Round Robin can be considered a friendly game of passing the ball. It is the default policy for distributing incoming traffic evenly among your servers. Consider it a game of turns: each server gets a turn in the order they appear on the list. Round robin is the preferred method for many businesses, particularly where server performance is similar. Least Connection: Imagine this strategy as a traffic cop directing cars to the least crowded path. It's a dynamic strategy in which incoming traffic is intelligently routed to the backend server with the fewest active connections. This guarantees that connections are distributed evenly throughout all your backend servers, preventing any single server from becoming overburdened. IP Hash: This policy is similar to having a reserved parking spot. IP Hash uses an incoming request's source IP address as a unique key to determine which backend server should process the client's request. This is useful since it ensures that requests from the same client are always routed to the same backend server as long as it is available. Consistent Hashing (Ring Hash): Consistent hashing uses a hashed key to distribute connections. Because it combines load balancing with persistence without recalculating the entire hash table when adding or removing servers, it's ideal for load-balancing cache servers with dynamic content. Fastest Response (Weighted Response Time): This technique routes new connections to the server with the shortest response time, as measured by time to the first byte. It is handy for temporary connections and servers of different capabilities. Fewest Servers: The smallest number of servers required to accommodate the present client load. Excess servers can be temporarily turned down or de-provisioned. It's useful when virtual computers incur charges, such as hosted environments. These load-balancing policies offer various ways to optimize traffic distribution among your servers. Whether you choose a fair rotation (Round Robin), the least busy route (Least Connection), or a personalized experience (IP Hash), these policies allow you to tailor your load balancing to your applications' demands and ensure efficient and dependable service delivery. ConclusionCustomization is essential in the Kubernetes world. You are not restricted to the preset traffic management rules. You may design a robust solution that minimizes server downtime and simplifies maintenance by tailoring your Kubernetes infrastructure to meet your demands. Finally, load balancing is essential to keeping your Kubernetes clusters up and running. You can design a resilient infrastructure that matches the demands of current applications and services by optimizing your system's load-balancing technique. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








