| |

Adenovirus Disease Prediction for Child Healthcare Using Machine LearningMachine Learning is a study in Artificial Intelligence that helps computers to learn from past data. It uses different algorithms to build mathematical models and predict using previous data. Machine learning is used for tasks like predicting diseases, speech recognition, email filtering, recommendation system, etc. Predicting Disease using Machine Learning models is a significant task that helps to promote healthcare with the help of its diagnosis and prevention measures. Different machine learning algorithms analyse the patient's data to identify patterns that can predict the disease and its condition. In this article, we will learn about the Prediction of Adenovirus Disease for Child Healthcare using Machine learning Algorithms. It will use previous data, which helps people to detect and prevent Adenovirus Disease. The model's distinctive characteristic is its ability to correctly identify Adenovirus infections when an individual enters their biological parameters, potentially reducing the need for hospital physical tests. This is especially important in rural areas where access to doctors may be limited. What is Adenovirus Disease?Adenovirus, or DNA virus, causes respiratory tract infection, gastrointestinal system, or conjunctiva infection. Adenovirus Virus is a group of infections caused by adenoviruses, which can infect people. Adenoviruses are divided into roughly 50 different types, each of which can cause a distinct set of symptoms. Adenovirus infections are most frequent in youngsters but can happen to anyone. The symptoms of adenovirus infection are:
Dataset for Adenovirus Disease PredictionThis dataset has 5434 samples and eight different parameters. Out of all, 4484 are infected, and 950 are healthy samples. We will train various machine learning algorithms on the given dataset. Prediction of Adenovirus DiseaseFor the prediction of the Adenovirus disease using different machine learning algorithms, we need to perform different steps as follows: Step 1. Importing required libraries and Datasets. Code: Output: 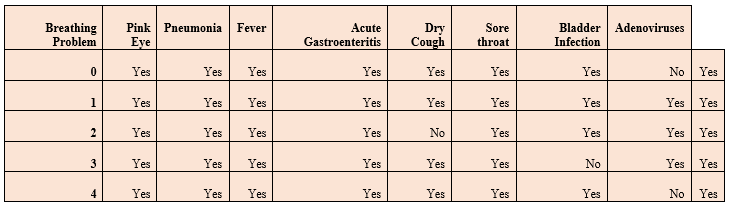
Explanation: We have installed libraries like pandas, numpy, and sklearn for data frames and machine learning models, matplotlib, and seaborn for data visualization. Then we have loaded our data set and stored it in a dataframe. Step 2: Data Pre-processing This step includes data cleaning, getting the dataset's structure, and many more. Firstly, we will check whether there are any null values in the dataset. The info() method will tell the basic structure of the dataset Code: Output: <class 'pandas.core.frame.DataFrame'> RangeIndex: 5434 entries, 0 to 5433 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Breathing Problem 5434 non-null object 1 Pink Eye 5434 non-null object 2 Pneumonia 5434 non-null object 3 Fever 5434 non-null object 4 Acute Gastroenteritis 5434 non-null object 5 Dry Cough 5434 non-null object 6 Sore throat 5434 non-null object 7 Bladder Infection 5434 non-null object 8 Adenoviruses 5434 non-null object dtypes: object(9) memory usage: 382.2+ KB Explanation: The info() function is used to get the basic structure to check the null values in the data set. Now, we will check the descriptive statistical view of the dataset using the describe function. Code: Output: 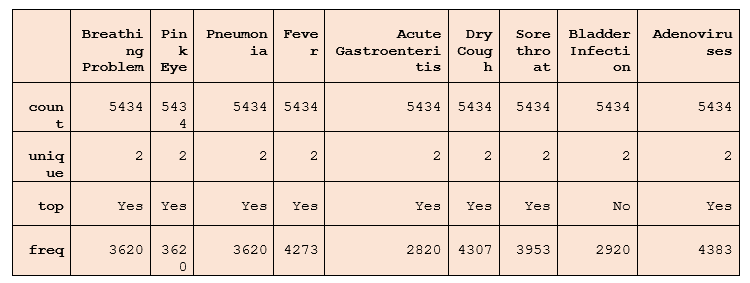
Explanation: The describe() method tells us about the descriptive statistical view of the dataset. It tells about the count, unique values, top, and frequency. Step 3: Data Manipulation Data manipulation involves changing the dataset into the suitable parameter used for analysis using machine learning algorithms. It includes scaling, encoding, normalization, and dimension reduction. It helps to enhance the data quality and performance of the model. Code: Output: 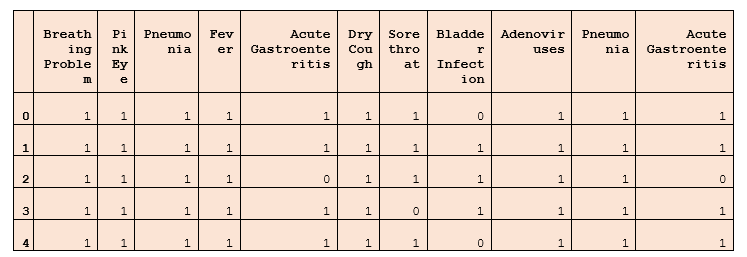
Explanation: We have imported a LabelEncoder to transform the data set. It has scaled the dataset to make it easier to analyze and understandable by the machine learning models. Step 4: Calculating Correlation In this step, we will calculate the correlations between the features using the corr() method. Code: Output: 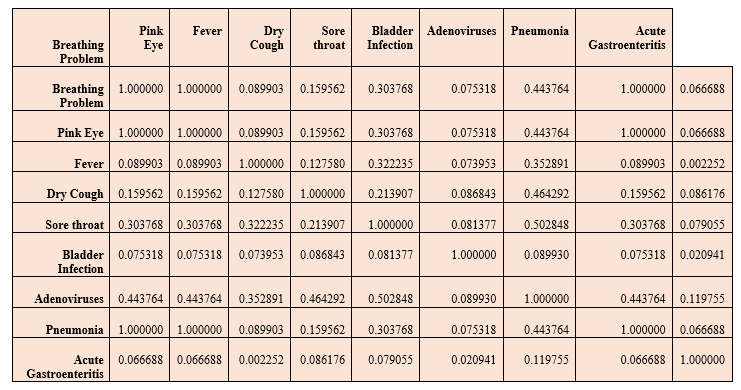
Explanation: We have printed the correlations between different features, which describe the relation of a feature to another. Step 5: Splitting the dataset We will split the dataset into training and test data using the train_test_split module of sklearn library. Code: Explanation: We have imported different models from the sklearn library, including train_test_split for splitting the dataset, metrics for making the confusion matrix, and accuracy_score for getting the accuracy. Step 6: Model building We will build our Adenovirus Disease prediction model with different algorithms and choose the best one with the highest accuracy. 1. Logistic Regression Code: Output: 92.5353485861814 Explanation: We have taken logistic regression as our first model, giving us an accuracy of 92%. 2. Random Forest Regressor Code: Output: 68.89109966539078 Explanation: We have taken Random Forest Regressor as our second model, giving us an accuracy of 68%. 3. K-Nearest Neighbours Classifier Code: Output: 92.91628534826306 Explanation: We have taken the KNeighbours Classifier as our third model, giving us an accuracy of 92%. 4. Support Vector Machines (SVM) Code: Output: 90.93532382704692 Explanation: We have taken the Support Vector Machine as our fourth model, giving us an accuracy of 90%. 5. Decision Tree Classifier Code: Output: 93.56325158663642 Explanation: We have taken the Decision Tree Classifier as our fifth model, giving us an accuracy of 93%. Step 6: Accuracy of models Code: Output:
Model Score
4 Decision Tree 93.56325158663642
2 KNN 92.91628534826306
0 Logistic Regression 92.5353485861814
3 Support Vector Machines 90.93532382704692
1 Random Forest 68.89109966539078
Explanation: We have printed the accuracy of each model in ascending order. Step 7: Analysis of the accuracy of the models We have divided the dataset into training data (80%) and testing data (20%). Then, we applied different machine-learning models and checked their accuracy. We found that the decision tree classifier has an accuracy of 93%. KNN has an accuracy of 92.9%. Logistic Regression has an accuracy of 92.5%. Support Vector Machines has an accuracy of 90%, and Random Forest has an accuracy of 68%. Out of all the models, the decision tree has the highest accuracy. It is more efficient than all other algorithms. Step 8: Predicting Adenovirus Disease We found that Decision Tree is the most efficient machine learning model. So, we are using the decision tree for predicting Adenovirus Disease for Child Healthcare. Test case 1 Output: The Patient is Adenovirus Positive(+ve) Test case 2 Output: The Patient is Adenovirus Negative(-ve)
Next TopicRNN for Sequence Labelling
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








