| |

BERT ApplicationsIntroductionIn this article, we are discussing the BERT applications. Transformers has taken the NLP international via storm. Current studies have proven Transformers, and other architectures based on it (like BERT, RoBERTa, XLNET) have been implemented to remedy many programs - sentiment category, fraud detection, neural language translation or question-answering systems. Whilst all of this is actual, there is nonetheless a variety of thriller and confusion around it. Several of the maximum not unusual asked questions are - (1) need to use the CLS token or all token's output most effectively for sentence representation (2) Will exceptional-tuning the version ahead increase the accuracy? If you have requested these questions or are getting commenced with BERT, this is the thing for you. Tag along as we first provide creation to the BERT version, after which we try to tackle every one of those questions experimentally. What is mean by BERT?BERT stands for Bi-Directional Encoder Representation from Transformers. It is a modification of Transformers where we only keep the encoder part and remove the decoder part. At publication, it achieved industry-leading results on 11 natural language processing tasks. The main motivation behind BERT is to address the limitations of existing one-way language models. This means that they only consider the left-to-right text for sentence-level reasoning. BERT, on the other hand, allows tokens to participate on both sides of the self-attention layer. 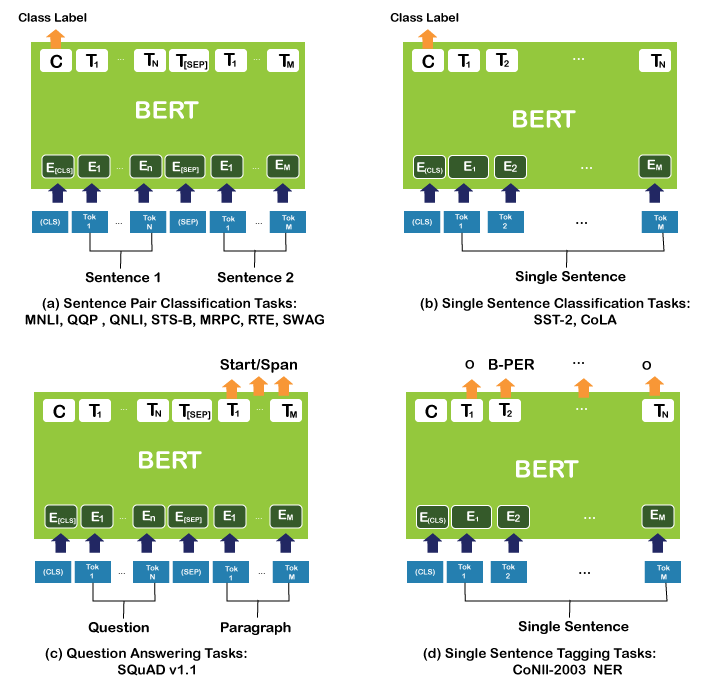
That is one of the primary reasons for its high overall performance. The top captivating feature of BERT is that it is far terrific easy to apply for a large quantity of NLP duties. The concept is to take the pre-educated BERT model and later high-quality-track it for the specific challenge. The pre-educated model is educated on a large corpus in an unsupervised way. Subsequently, the model learns the familiar representations of the tokens from a big corpus of text. This makes it smooth to best-tune later for other NLP tasks because the model comes pre-skilled with big context approximately the language, grammar, and semantic representations. Training BERT is an exciting paradigm in itself. The authentic paper proposed two unsupervised methods for education, Masked LM (mlm): in which a few percentages (15%) of the input tokens are masked randomly; the version then tries to expect the one's masked tokens. They created a unique token [MASK] for this reason. Next Sentence Prediction (NSP): in which sentences A and B are selected such that, 50% of the time, B is the real next sentence that follows A (labelled as IsNext), and 50% of the time, it is a random sentence from the corpus (labelled as NotNext). The version is educated to expect whether the second sentences comply with the primary. Sooner or later, the last thing we should realize about BERT is the input and output of the version. So, as traditional with the NLP fashions, BERT takes the sentences (after tokenizing direction) because they enter. And because it only uses the encoder as a part of the Transformer, it generates two exciting outputs; pooler_output is embedding the [CLS] special token. In many instances, it is considered a valid representation of the whole sentence. last_hidden_state incorporates the final embeddings of all tokens within the sentence from the ultimate hidden state. We will apply invariant permutation techniques (like - max, imply or sum) to combine the embeddings into a single sentence representation. Practical uses of BERT?BERT (Bidirectional Encoder representation from Transformers) is the cutting-edge and best discovery of a pre-educated model in herbal Language Processing. This switch in studying version made it smooth to other high-quality music NLP duties in the respective area of (science/technology/commerce/etc.) human hobby. This technology evaluation is set to research unique uses of instances of BERT and how it is implemented to remedy NLP issues. Why BERT is useful?Throughout fine Tuning pre-educated model is fed into labelled data for specific NLP duties to fine-track all the BERT parameters. After the first-rate track procedure, each NLP task could have a unique BERT version. So, as we can see, the realistic usability of BERT comes especially due to the following traits -
BERT Applications:Following are few applications that are developed using BERT model: 1. Smart search in Google:With BERT studies, google now can recognize the purpose of seeking text and offering relevant results. This became feasible as BERT uses Transformer to research multiple tokens and sentences parallelly with most self-interest. 2. Text Summarization or BERTSUM:BERT may be used in textual content summarization and endorse a popular framework for extractive and abstractive models. Extractive summarization systems create a summary by identifying (and, in the end, concatenating) the maximum important sentences in a document. A neural encoder creates sentence representations, and a classifier predicts which sentences must be decided on as summaries. Abstractive summarization, alternatively, is a way wherein the summary is generated utilizing producing novel sentences by either rephrasing or using brand-new words, in preference to simply extracting the important sentences. Neural methods for abstractive summarization conceptualize the mission as sequence-to-sequence trouble. 3. BioBERT:Biomedical textual content mining is becoming increasingly vital as the number of biomedical documents hastily grows. With the progress in herbal language processing (NLP), extracting treasured facts from biomedical literature has gained recognition amongst researchers. Deep mastering has boosted the improvement of effective biomedical text-mining fashions. But, immediately making use of the improvements in NLP to biomedical textual content mining frequently yields unsatisfactory results because of a word distribution shift from trendy domain corpora to biomedical corpora. BioBERT is a website-precise language illustration model pre-trained on massive-scale biomedical corpora. BioBERT substantially outperforms them on the following three consultant biomedical text mining obligations: biomedical named entity recognition (0.62% F1 rating development), biomedical relation extraction (2.8% F1 score development) and biomedical query answering (12.24% MRR development). Evaluation results show that pre-education BERT on biomedical corpora facilitates recognising complex biomedical texts. 4. ClinicalBERT:This BERT models clinical notes and hospital readmission prediction through contextual text/clinical note integrations. ClinicalBERT reveals high-quality relationships between human-tried medical concepts. Clinical Bert predicts a baseline 30-day readmission rate using discharge summaries and scores from previous days in the ICU. It saves money, time, and lives. 5. SciBERT:Over time, the exponential boom in clinical guides has made NLP an essential device for huge-scale know-how extraction and system studying of these documents. SCIBERT was centred on clinical NLP-associated responsibilities as opposed to popular language models. This model evolved by using random 1.4 million papers from semantic scholars. The corpus comprises 18% papers on computer science and 82% from a wide biomedical area. SciBERT outperforms BERT based on numerous medical and clinical NLP obligations. 6. Question-Answering and Chatbot:BERT helped the Stanford Question Answering Dataset (SQuAD) v1.1 test at 93.2 (1.5-point definite improvement) and the SQuAD v2.0 test at 83.1 (absolute improvement of 5.1 points). SQuAD is a reading comprehension dataset consisting of questions posed by outsourced workers to a set of Wikipedia articles, where the answer to each question is a fragment of text or scope in the corresponding paragraph or can remain without an answer. be (v2.0). The same functionality of BERT can be extended to work as a chatbot on small to large text. Conclusion:So, in this article, we are discussing the BERT applications. As we mentioned in our preceding articles, BERT can be used for a diffusion of NLP obligations consisting of text classification or Sentence classification, Semantic Similarity between pairs of Sentences, query Answering projects with paragraphs, textual content summarization and many others. However, BERT cannot be used for a few NLP tasks because of its bidirectional statistics retrieval property. Some missions are gadget translation, textual content Generator, common query answering ventures and many others. It wishes to get the facts from both sides. This utility is usually done with the excellent tuning of the BERT version for our project. Nice tuning is a little analogous to switch mastering, in which we take a pre-skilled version and retrain it on our small dataset by freezing some unique layers and adding some new ones. Still, there needs to be an idea of adding or freezing layers in great tuning. We will sincerely school the model on a similar dataset; it's far the shape of transfer mastering.
Next TopicXtreme: MultiLingual Neural Network
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








