| |

Predicting Student Dropout Using Machine Learning
In the realm of modern education, the issue of student dropout looms as a pressing challenge, impacting individuals and educational institutions alike. The ramifications of high dropout rates extend beyond academic achievements, extending into future career prospects and overall well-being. However, detecting and addressing this issue at its early stages can significantly mitigate its negative consequences. Enter machine learning, an innovative field within artificial intelligence. Machine learning algorithms possess the potential to accurately predict student dropout by harnessing extensive data and advanced analytical techniques. By examining various factors and intricate patterns, these models can identify students who are more susceptible to dropping out. This article delves into the realm of machine learning's application in forecasting student dropout, highlighting the advantages, obstacles, and potential implications it presents for the education sector. To comprehend the intricate landscape of student dropout, it is imperative to acknowledge the multitude of factors that contribute to this phenomenon. Student dropout is a multifaceted occurrence influenced by a diverse range of individual, societal, and institutional elements. Academic struggles, disengagement, socio-economic constraints, familial circumstances, and insufficient support mechanisms are among the common catalysts for dropout. By attaining a deep understanding of these underlying factors, educators and policymakers can develop targeted interventions and comprehensive strategies to tackle the dropout challenge head-on. In this context, machine learning emerges as a valuable ally, offering unique insights and innovative approaches to combat student dropout. Cutting-edge machine learning algorithms possess a remarkable ability to dissect extensive and heterogeneous datasets, enabling them to discern intricate patterns and make reliable forecasts. In the realm of predicting student dropout, these machine-learning models can effectively harness a diverse array of data points. Demographic details, academic achievements, attendance records, levels of engagement, socio-economic indicators, and an assortment of pertinent factors all come into play. Through careful analysis of this rich dataset, machine learning algorithms have the potential to unveil concealed patterns and interdependencies that may elude human analysts. By leveraging historical data, these algorithms learn to accurately gauge the probability of a student discontinuing their education, leveraging the student's unique characteristics and individual circumstances as vital inputs for their predictions. Benefits of Predicting Student DropoutThe utilization of machine learning in predicting student attrition yields numerous advantages for educational institutions, policymakers, and students themselves. Firstly, the early identification of students at risk of dropping out allows for prompt interventions and the establishment of support systems. Educators can deliver personalized assistance, provide supplementary resources, and implement targeted measures to enhance students' likelihood of success. This proactive approach significantly curtails attrition rates and bolsters student retention. Secondly, the predictive aspect facilitates the efficient allocation of institutional resources. By pinpointing students who are susceptible to dropout, educational institutions can concentrate their efforts and resources on furnishing the necessary support to these individuals. This targeted approach ensures that interventions are directed precisely where they will have the most impact, optimizing resource utilization. Moreover, the integration of machine learning in dropout prediction fosters the development of evidence-based policies and strategies. By scrutinizing the underlying factors contributing to attrition, policymakers can devise interventions that address the core issues and foster a more supportive and conducive learning environment. This data-informed approach empowers informed decision-making and assists in formulating effective policies aimed at enhancing student outcomes. Challenges of Predicting Student Dropout Using Machine LearningWhile embracing machine learning for predicting student attrition shows immense potential, it is imperative to acknowledge and address the associated challenges and ethical implications. One key challenge revolves around the accessibility and quality of data. Building accurate prediction models necessitates sufficient and reliable data. Educational institutions must establish robust protocols for data collection, storage, and privacy to uphold the confidentiality and integrity of student information. Another hurdle involves the potential bias within machine learning models. If the training data used to develop the models is biased or incomplete, the predictions may become skewed or unfair. Addressing bias requires a conscientious effort to train models on diverse and representative datasets, fostering reliable and impartial predictions. Ethical considerations play a pivotal role when deploying machine learning to forecast student attrition. Responsible utilization of predictive models should prioritize student privacy, consent, and transparency. Students should be informed about the purpose of data collection and how it will be employed in predicting attrition. Furthermore, mechanisms must be established to address concerns pertaining to privacy and data protection, ensuring a responsible and accountable approach to safeguarding student rights. About the DatasetThis dataset provides a comprehensive view of students enrolled in various undergraduate degrees offered at a higher education institution. It includes demographic data, social-economic factors, and academic performance information that can be used to analyze the possible predictors of student dropout and academic success. This dataset contains multiple disjoint databases consisting of relevant information available at the time of enrollment, such as application mode, marital status, course chosen, and more. Additionally, this data can be used to estimate overall student performance at the end of each semester by assessing curricular units credited/enrolled/evaluated/approved as well as their respective grades. Finally, we have the unemployment rate, inflation rate, and GDP from the region, which can help us further understand how economic factors play into student dropout rates or academic success outcomes. This powerful analysis tool will provide valuable insight into what motivates students to stay in school or abandon their studies for a wide range of disciplines such as agronomy, design, education, nursing journalism, management, social service, or technologies. Columns
Now we will implement it in the code. We will try to find the model for the best accuracy for predicting the student dropout rate. Code: Importing LibrariesReading the DatasetUnderstanding the DatasetOutput: 
Output: 
Output: 
Output: 
Output: 
Looks like there are no nulls or duplicates, but still, we can check and handle them if required. Output: 
Output: 
Only the Target column is non-numeric, which we can convert to numeric. The target column is an output column, so we need it in numeric form so that we can find its correlation with others. Output: 
So there are 3 unique values in the target column which we can replace by
Output: 
Output: 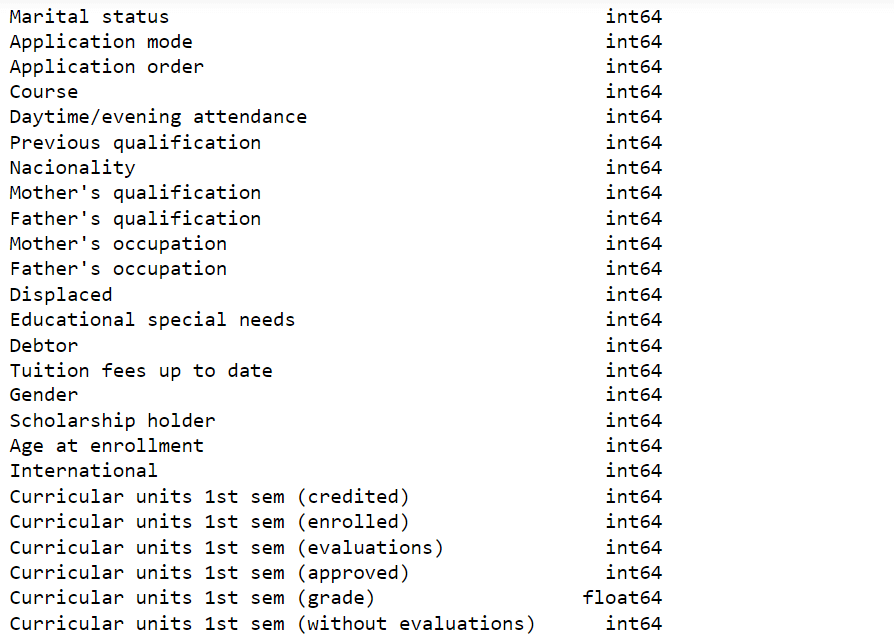
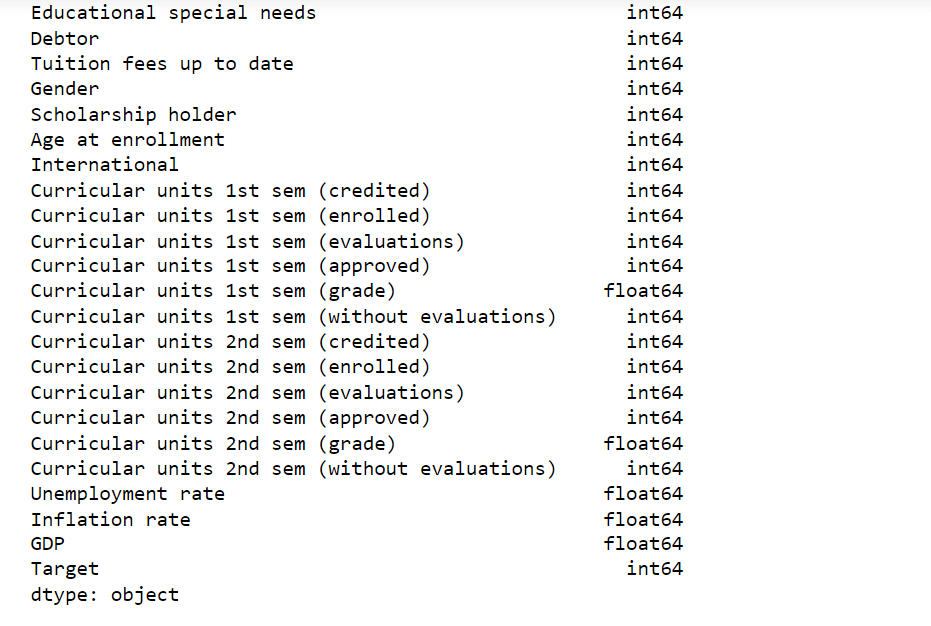
Output: 
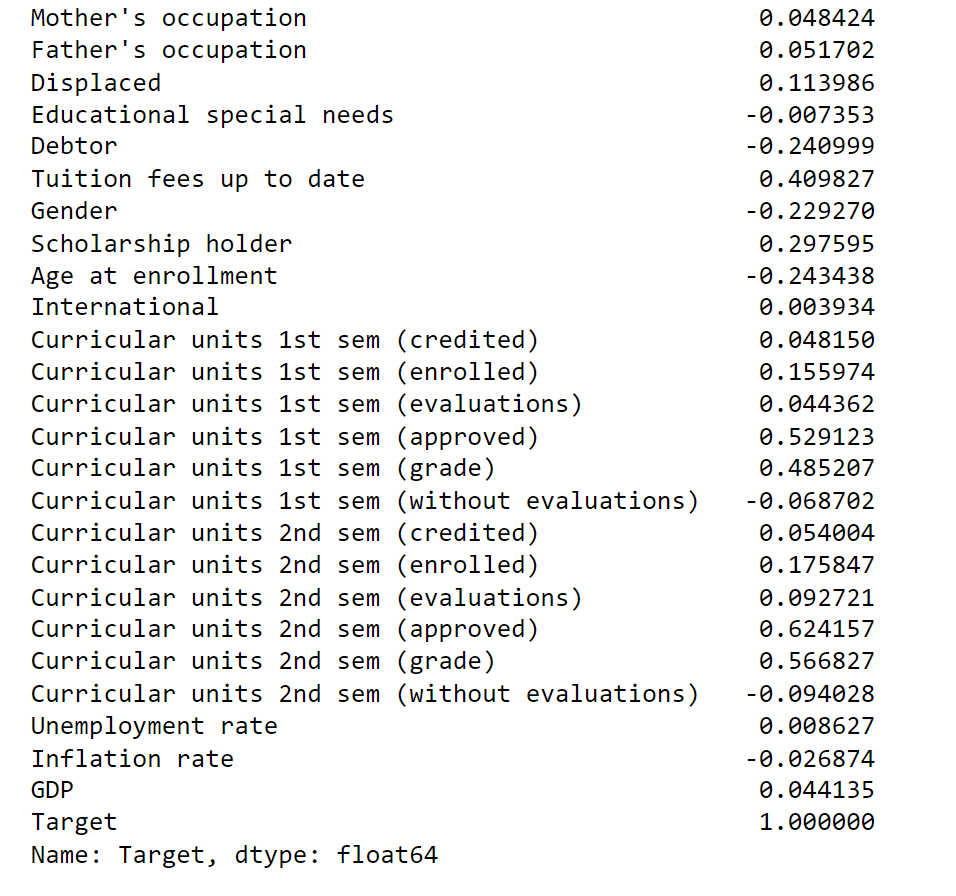
Finally, find the correlation of Target with all other numeric columns. Output: 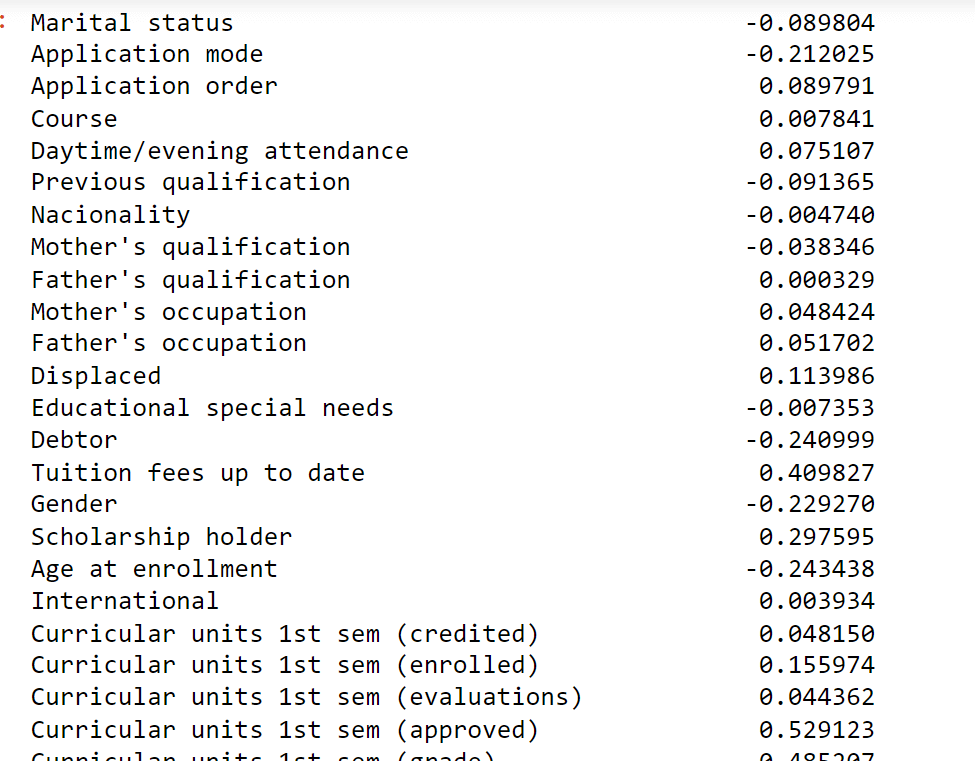
Output: 
This is the new Df considering relevant input and output columns. Output: 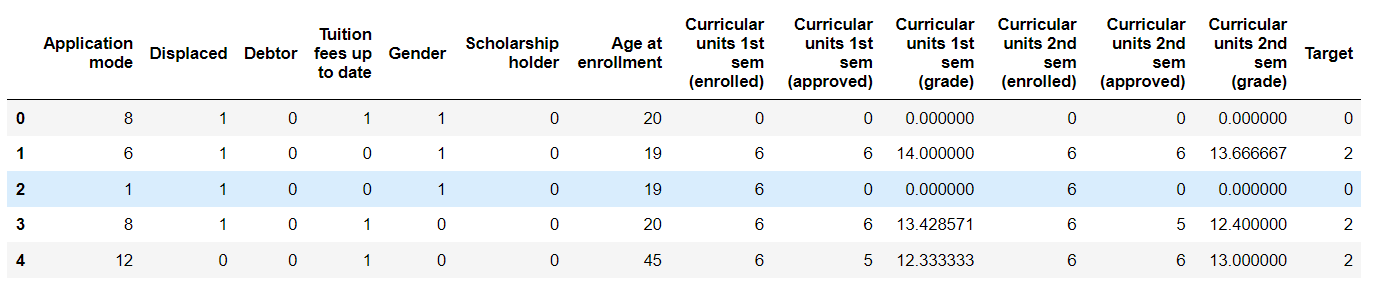
Output: 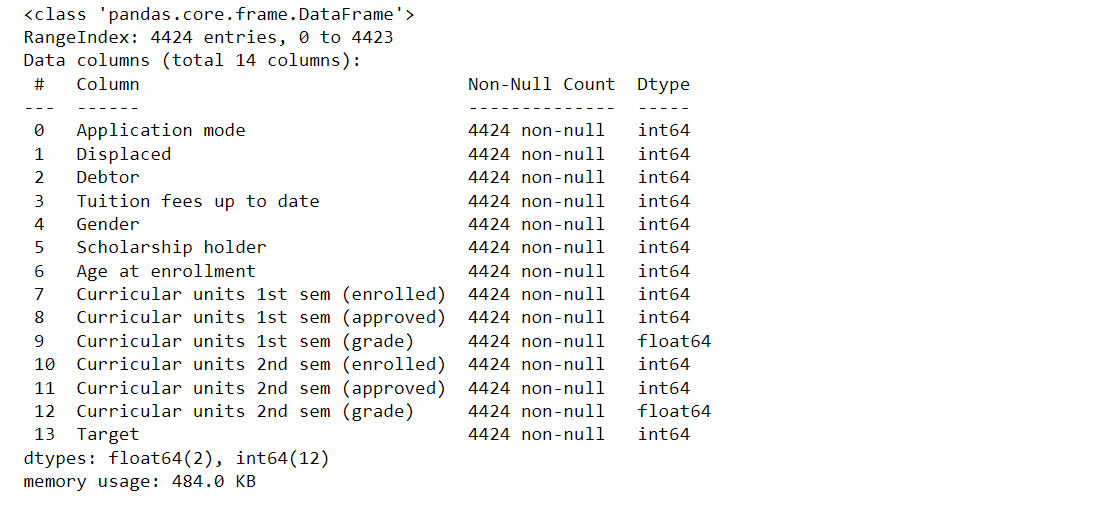
Output: 
EDA(Exploratory Data Analysis)In our exploration of the Student Dropout dataset, we will engage in a process called Exploratory Data Analysis (EDA). Think of it as our way of investigating and getting to know the data better. It's like peeling back the layers of an onion to reveal its true nature. By using different tools and techniques, we will examine the dataset closely, looking for interesting patterns and insights. EDA helps us understand the factors behind student dropout and enables us to make informed decisions to address this issue. Output: 
Output: 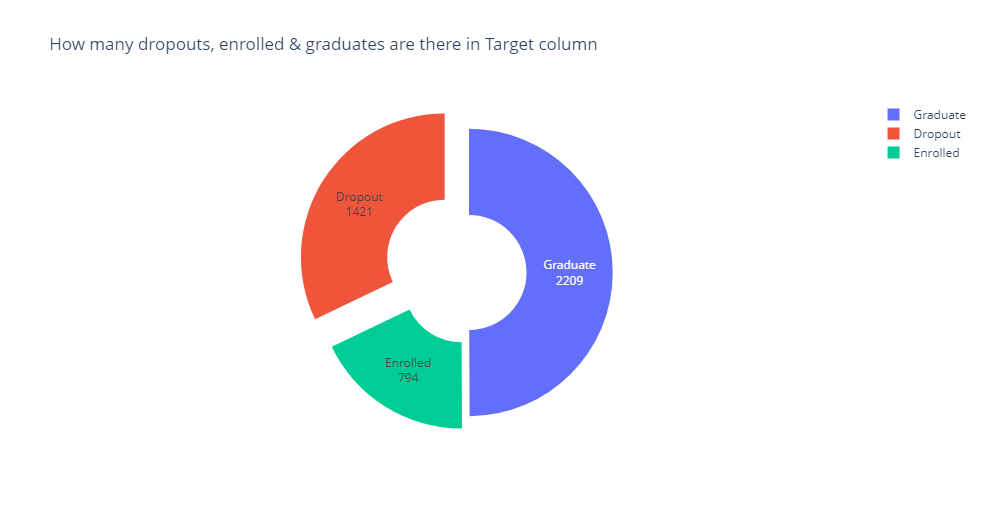
Output: 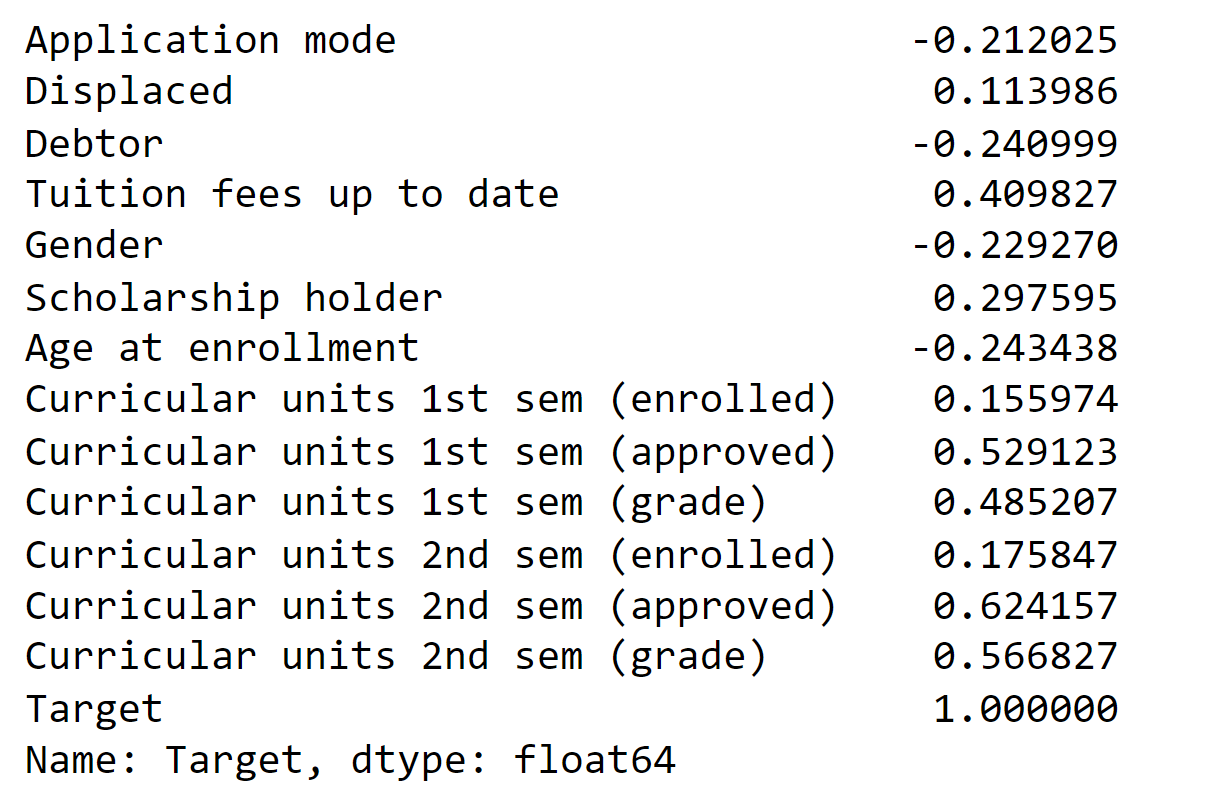
Output: 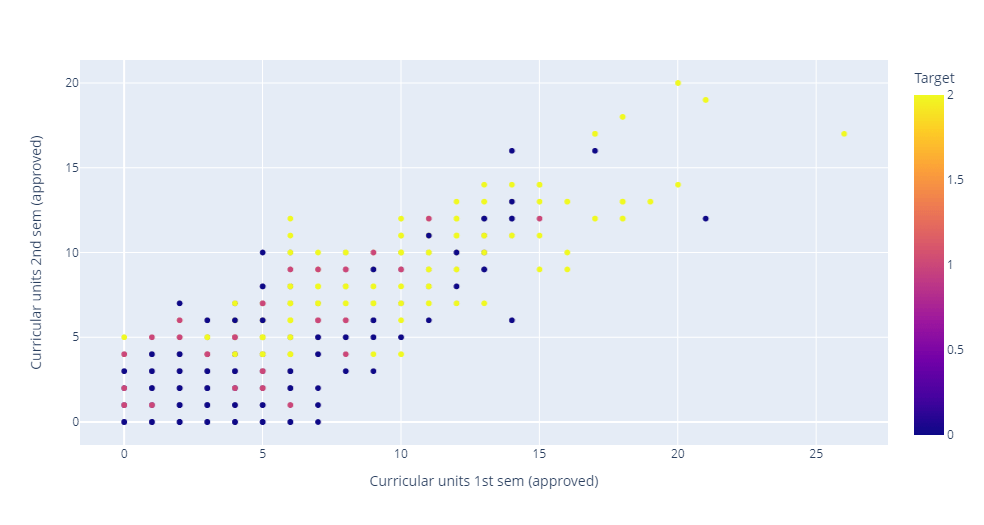
Let's plot the column Curricular units 1st sem (grade) against Curricular units 1st sem (grade) and differentiate Target by color. Output: 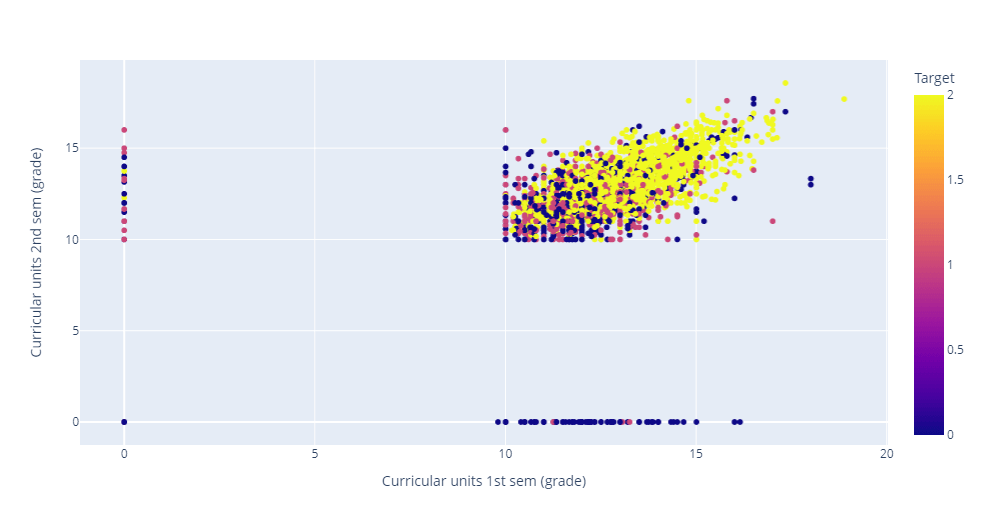
Output: 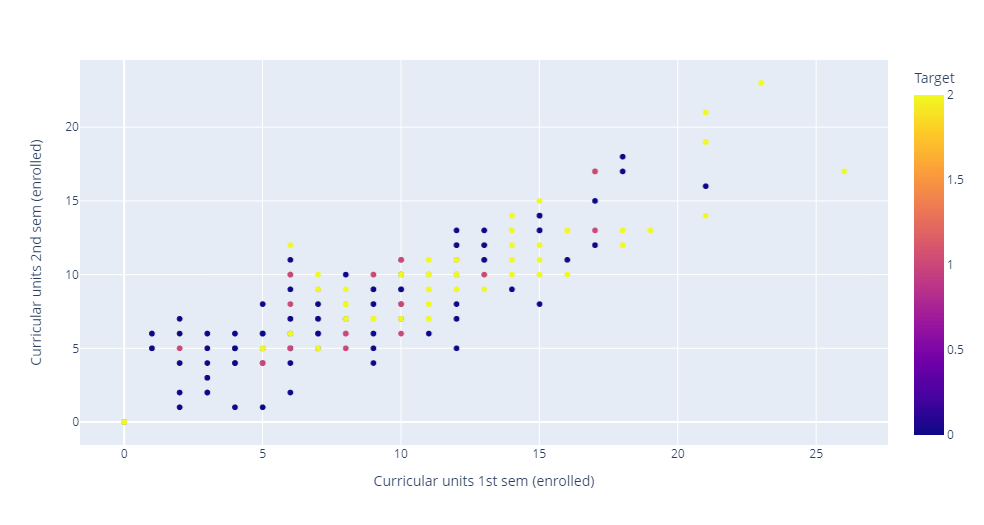
Output: 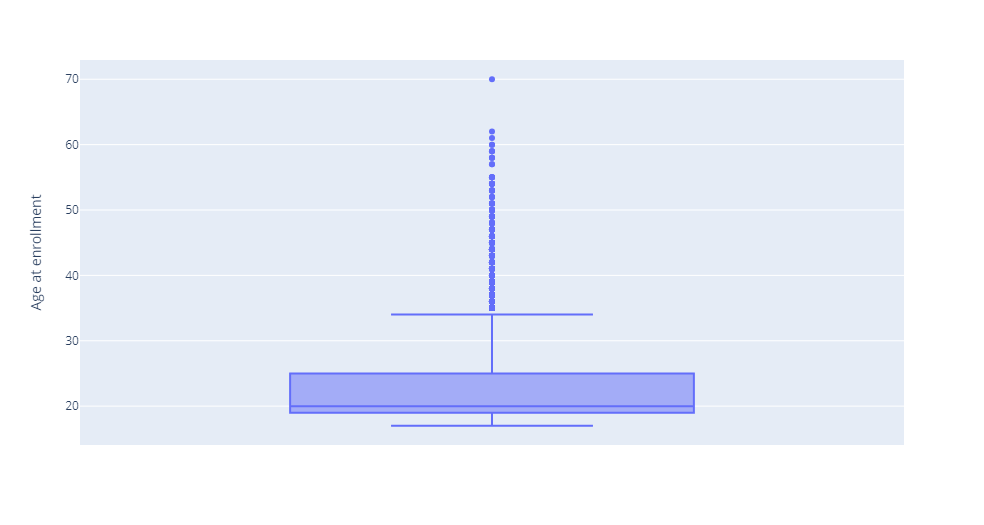
Output: 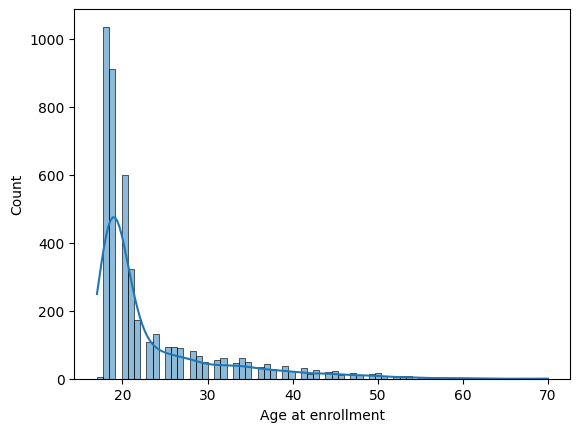
Output: 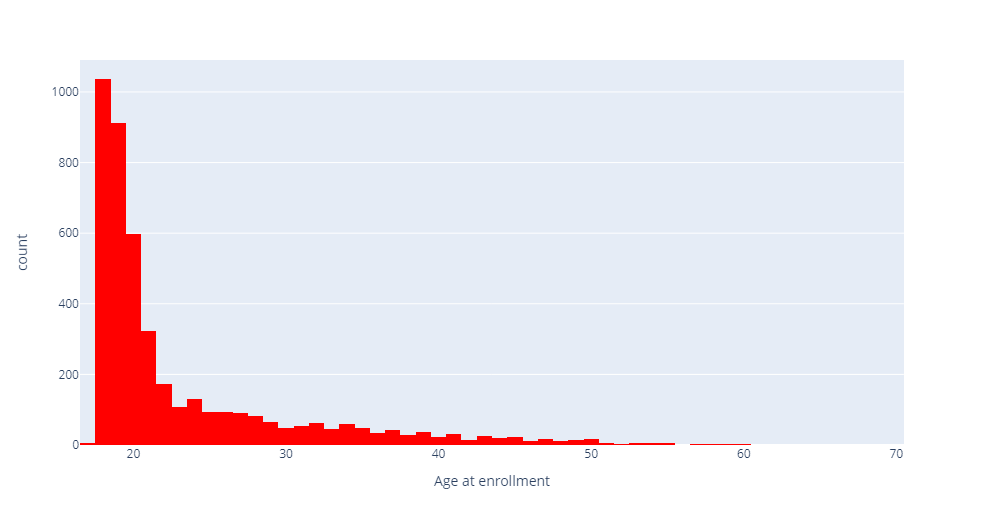
Extract Input & Output Columns Output: 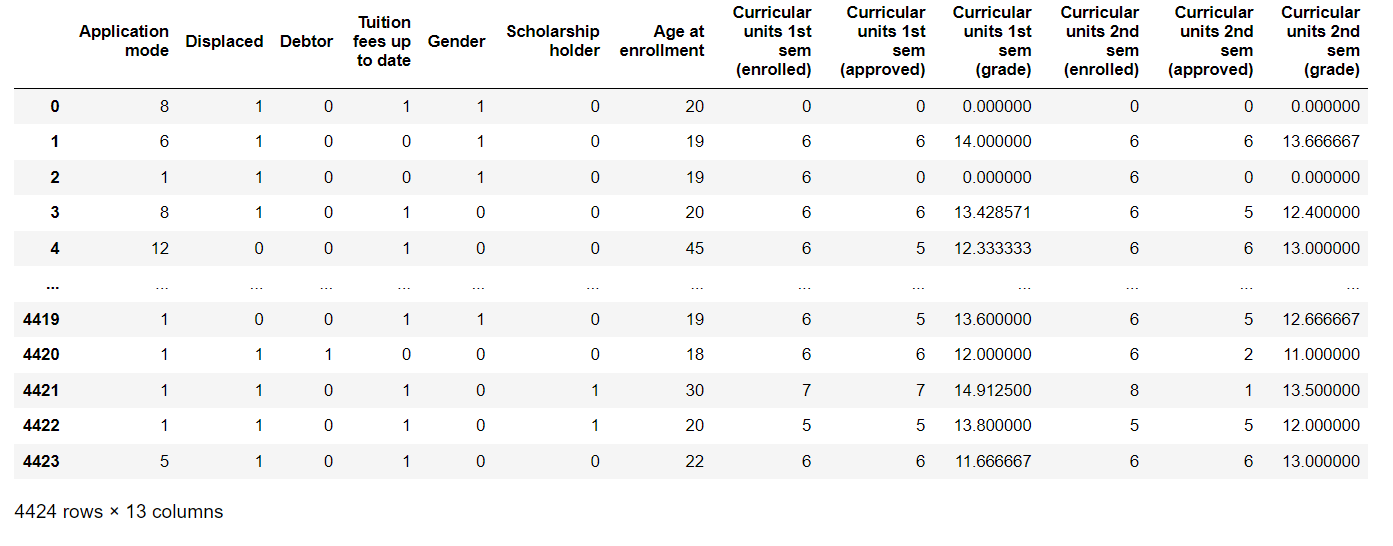
Splitting the Dataset into Training and Testing SetsOutput: 
ModelingModeling is a crucial step in the predictive analytics process. It involves training and testing various machine learning models to determine their accuracy and performance in predicting student dropout. During this stage, different algorithms are applied to the dataset, each with its own strengths and weaknesses. Here, we will train various models and then look for their accuracy. Logistic Regeression Output: 
Stochastic Gradient ClassifierOutput: 
PerceptronOutput: 
Logistic Regression CVOutput: 
Decision Tree ClassifierOutput: 
Random Forest ClassifierOutput: 
Support Vector MachineOutput: 
NuSVCOutput: 
Linear SVCOutput: 
Naive BayesOutput: 
Output: 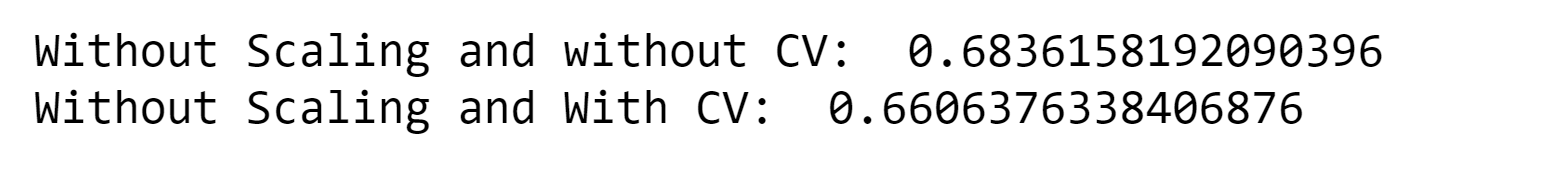
Output: 
Output: 
Output: 
After evaluating and comparing multiple machine learning models for predicting student dropout, the Random Forest model emerged as the top performer with an accuracy of 76.94% and 77.08% with cross-validation, as the Random Forest algorithm is known for its ability to handle complex datasets and capture intricate relationships between variables. Model SelectionSelect the model which gives maximum accuracy. So we select Random Forest with accuracy 76.94 & 77.08 with Cross Validation. Output: 
We will use GridSearchCV for hyperparameter tuning in a Random Forest classifier model. Output: 
Here, the accuracy of the model has been improved. Output: 
Considering all the points Random Forest Classifier can be used as the model for the prediction of student dropouts. ConclusionIn conclusion, the application of machine learning in predicting student attrition presents a transformative opportunity for educational institutions to tackle this widespread issue effectively. By leveraging the capabilities of machine learning algorithms, educators, policymakers, and institutions can take proactive measures, provide targeted support, and foster an environment conducive to student success. Nevertheless, it is imperative to navigate challenges pertaining to data quality, bias, and ethical considerations to ensure the conscientious and equitable use of these predictive models. As machine learning and data analysis continue to advance, we hold the potential to make substantial strides in reducing student attrition, enhancing educational outcomes, and cultivating an inclusive and supportive education system that caters to the needs of all students.
Next TopicImage Processing Using Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








