| |

What are LSTM NetworksThis tutorial discusses the issues with conventional RNNs resulting from increasing and decreasing gradients. It also proposes a solution that solves these problems through Long Short-Term Memory (LSTM). Introduction:LST Memory is an advanced recurrent neural network (RNN) design that was developed to better accurately reflect chronological sequences and related brief relationships. Its key characteristics include the internal layout of an LSTM cell, the many changes made to the LSTM architecture, and a few in-demand LSTM implementations. LSTM Networks:LSTM networks extend the recurrent neural network (RNNs) mainly designed to deal with situations in which RNNs do not work. When we talk about RNN, it is an algorithm that processes the current input by taking into account the output of previous events (feedback) and then storing it in the memory of its users for a brief amount of time (short-term memory). Of the many applications, its most well-known ones are those in the areas of non-Markovian speech control and music composition. However, there are some drawbacks to RNNs. Long-Short-Term Memory (LSTM) was introduced into the picture as it is the first to fail to save information over long periods. Sometimes an ancestor of data stored a considerable time ago is needed to determine the output of the present. However, RNNs are utterly incapable of managing these "long-term dependencies." The second issue is that there is no better control over which component of the context is required to continue and what part of the past must be forgotten. Other issues associated with RNNs are the exploding or disappearing slopes (explained later) that occur in training an RNN through backtracking. Therefore, the problem of the gradient disappearing is eliminated almost entirely as the training model is unaffected. Long-time lags within specific issues are solved using LSTMs, which also deal with the effects of noise, distributed representations, or endless numbers. With LSTMs, they do not meet the requirement to maintain the same number of states before the time required by the hideaway Markov model (HMM). LSTMs offer us an extensive range of parameters like learning rates and output and input biases. Therefore, there is no need for minor adjustments. The effort to update each weight is decreased to O(1) by using LSTMs like those used in Back Propagation Through Time (BPTT), which is a significant advantage. Exploding and Vanishing Gradients:The primary objective of training a network is to reduce losses in the network's output. Gradient, or loss with a weight set, is determined to adjust the weights and minimize the loss. The gradient in one layer depends on aspects of the following layers, and if any component is small, it results in a smaller gradient (scaling effect). Multiplying this effect by the learning rate (0.1 to 0.001) reduces weight changes and produces similar results. When gradients are significant due to large components, weights can change significantly, causing explosive gradients. To address explosive gradients, the neural network unit was rebuilt with a scale factor of one. The cell was enhanced with gating units, leading to the development of LSTM. The architecture of LSTM Networks:The design of LSTM (Long-Short Term Memory) networks contrasts with conventional RNNs in a few key perspectives: Hidden Layer StructureThe main difference between the structures that comprise RNNs as well as LSTMs can be seen in the fact that the hidden layer of LSTM is the gated unit or cell. It has four layers that work with each other to create the output of the cell, as well as the cell's state. Both of these are transferred to the next layer. Gating MechanismsContrary to RNNs, which comprise the sole neural net layer made up of Tanh, LSTMs are comprised of three logistic sigmoid gates and a Tanh layer. Gates were added to restrict the information that goes through cells. They decide which portion of the data is required in the next cell and which parts must be eliminated. The output will typically fall in the range of 0-1, where "0" is a reference to "reject all' while "1" means "include all." Hidden layers of LSTM: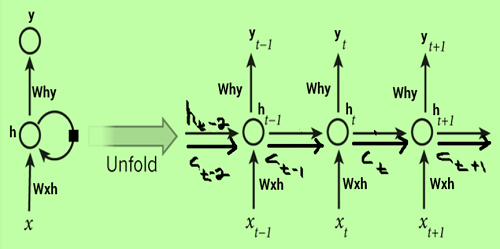
Each LSTM cell is equipped with three inputs and two outputs, ht, and Ct. At a specific time, t, which ht is the hidden state, and Ct is the cell state or memory. It xt is the present information point or the input. The first sigmoid layer contains two inputs: ht-1 and xt, where ht-1 is the state hidden in the cell before it. It is also known by its name and the forget gate since its output is a selection of the amount of data from the last cell that should be included. Its output will be a number [0,1] multiplied (pointwise) by the previous cell's state . Applications:LSTM models have to be trained using a training dataset before being used for real-world use. The most challenging applications are listed in the following sections: Text Generation: Text generation or language modelling involves the calculation of words whenever a sequence of words is supplied as input. Language models can be used at the level of characters or n-gram level as well as at the sentence or the level of a paragraph. Image Processing: LSTM organizations can investigate and depict pictures by producing printed portrayals. This application is regularly utilized in PC vision undertakings, for example, picture subtitling and object acknowledgement. Speech and Handwriting Recognition: LSTM networks can be employed to recognize and transcribe spoken language or handwritten text. This application has significant implications in speech recognition systems and optical character recognition (OCR). Music Generation: LSTM networks can generate musical sequences by learning patterns from existing musical data. This application enables the creation of new melodies, harmonies, and compositions. Language Translation: LSTM networks can be utilized in machine translation tasks to convert sequences of text from one language to another. By learning the mapping between languages, LSTM networks facilitate automatic language translation. Disadvantages of LSTM networks:
Advantages of LSTM networks:
Conclusion:All in all, LSTM networks have turned into a crucial devices in AI because of their capacity to show consecutive information and catch long-haul conditions. They have found applications in different spaces, including normal language handling, PC vision, discourse acknowledgement, music age, and language interpretation. While LSTM networks have downsides, progressing innovative work means addressing these constraints and further work on the abilities of LSTM-based models.
Next TopicPerformance Metrics in Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








