| |

Continuous Bag of Words (CBOW) in NLPThe Continuous Bag of Words (CBOW) model is a neural network model for Natural Language Processing. It can be used for multiple tasks like language translation and text classification. It is used for predicting the words based on the surrounding words. We can train this model on a large dataset using different optimization algorithms, such as stochastic gradient descent. The CBOW model gives numerical vectors after training, known as word embeddings. The word embeddings are used to represent the words as numerical vectors. The Word2vec is a neural network-based method for creating lengthy vector representations of words that contain their contextual significance and associations. Continuous Bag of Words is the main approach to implementing Word2vec. Introduction to Continuous Bag of WordsThe Continuous Bag of Words is a natural language processing technique to generate word embeddings. Word embeddings are useful for many NLP tasks as they represent semantics and structural connections amongst words in a language. CBOW is a neural network-based algorithm that anticipates a target word based on its context words. It is an unsupervised method that learns from unlabelled data. It can be used for sentiment analysis, machine translation, and text classification. The window of surrounding words works as an input for the Continuous Bag of Words and then predicts the target word in the window's center. This model is trained on a huge dataset based on text or words. It learns from the previous data and the pattern of the input data. This model can be coupled with other natural language processing techniques, like the skip-gram model, to enhance the performance of the natural language processing tasks. The CBOW model trains to alter the neurons' weights in the hidden layer to generate the best possible target word output. The model effectively and quickly predicts the output in one go, called one-pass learning. The main aim of this model is to develop complex representations of words in which semantically comparable words are close in the embedding space. Architecture of the Continuous Bag of WordsThe CBOW model seeks to analyze the context of the words around it to predict the target word. Let's take a phrase: "Today is a rainy day." This model breaks this sentence into word pairs (context and target words). The word pairs look like ([today, a], is), ([is, rainy], a), ([a, day], rainy). The model will predict the target words using these word pairs with the window size. 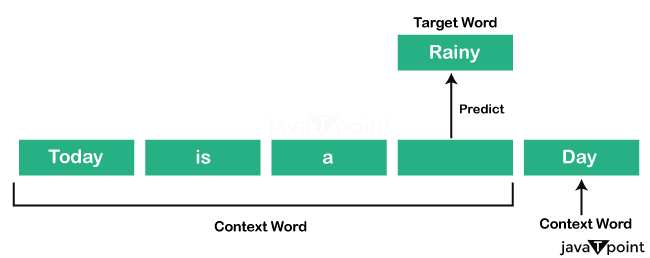
The input layer will be formed with the number of context words with the corresponding window size. For example, four 1 * W (W is the window size) input vectors will be used as the input layer if four context words are used for predicting one target word. The Hidden layer will get the input vectors and multiply them with a W* N matrix. The output of the hidden layer (1 * N) will go to the sum layer, in which the elements are first element-wise summed, and then activation is carried out to get the output. 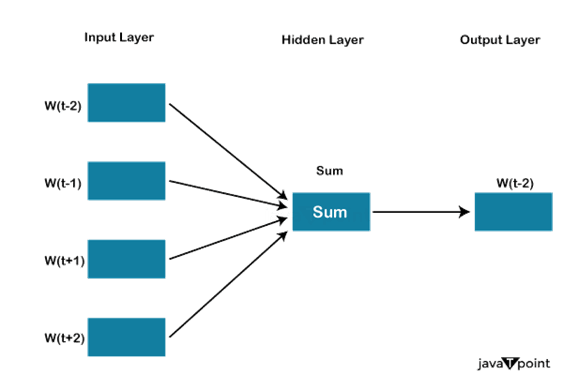
Let's implement the Continuous Bag of Words Model using Python Python provides a module named gensim, used for natural language processing that offers various embedding models. Installing gensim in PythonImplementation of the CBOW modelStep 1. Libraries and data We will import all the libraries and then load our data. We have taken an NLTK corpus named "brown". Code: We have imported the gensim model and the Word2Vec vocabulary. Along with we are using NLTK and its corpus. We have downloaded the brown corpus from the NLTK model and used it as the input data. Step 2: Initialising the Model Code: We create a CBOW model with the gensim library's Word2Vec class and configure some of the model's hyperparameters, such as minimum word count, embedding vector size, window size, and training algorithm (CBOW = 0). Step 3: Training of the model Code: During training, the CBOW model analyses the input data and modifies the biases and weights of the cells in the hidden and output layers to reduce the error between the predicted actual target word embeddings. This is known as backpropagation. The training with more epochs gives more accurate outputs. Step 4: Word Embeddings Code: In this, the model is learning the embeddings. Step 5: Checking Cosine Similarity Code: Output: The Cosine Similarity between 'girl' and 'boy': 0.61204993724823 We will calculate the cosine similarity between two words. It will tell how much the words are similar in meaning. We can analyze the similarity between words and their embeddings. Words similar in meaning or context are expected to be close to each other.
Next TopicDeploying Scrapy Spider on ScrapingHub
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








