| |

Meta-Learning in Machine LearningMeta-learning is commonly referred to as "learning to learn", is a group of machine learning in computer science. It is used to enhance the learning algorithm's consequences and performance by modifying specific components of the learning algorithm depending on the experiment's findings. Meta-learning enables researchers to determine which algorithms produce the best/better predictions from datasets. 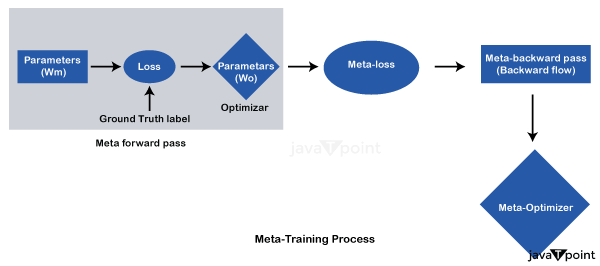
Meta-learning algorithms accept learning algorithm information as input. They then generate forecasts and offer data on the efficiency of the learning algorithms as result. The reason for meta-learning is to empower models to summarize new inconspicuous issues utilizing little information. Customary AI includes preparing models on a given dataset for a particular undertaking and assessing their exhibition on related errands. Meta-learning utilizes an alternate procedure, preparing models on a scope of errands so they may quickly adjust to new ones with minimal additional preparation. Meta-learning can be applied to various AI models, including brain organizations. Key partsI) Metalearning calculations: - Model-Skeptic Meta-Learning (MAML) is a noticeable meta-learning strategy that looks to familiarize one with a good statement of model boundaries, so a couple of slope steps on another undertaking bring about quick variation. - Reptile, as MAML, looks to distinguish an underlying arrangement of boundaries able to quickly adjust to new errands. Reptile, on the other hand, has a distinct technique for optimization. ii) Tasks and Meta-tasks: - In meta-learning, an errand is a particular issue or dataset on which the model is prepared. - A meta-task is a more significant idea that involves preparing the model on various undertakings to work on its ability to adjust to new ones. iii) Few-shot learning: - Meta-learning frequently employs few-shot learning situations in which the model is trained on a limited number of instances per task. This is critical for quickly adapting to new jobs with little data. iv) Transfer Learning: - In meta- - Meta-learning can be considered a sort of move learning, in which information obtained from dominating one bunch of errands is moved to further develop execution on another, related work. v) Gradient-based Meta-Learning: - Many meta-learning techniques use gradient-based optimization, which trains the model to update its parameters based on the gradient of the loss relative to those parameters. Types of Meta-Learningi) Model-agnostic meta-learning (MAML): - MAML seeks to learn model parameters so that a few gradient steps during meta-testing result in quick adaptation to new challenges. - Meta-training involves training the model on numerous tasks and modifying its parameters for rapid adaptation. The learnt initialization enables speedy convergence during meta-testing. ii) Reptile: - Gradient Descent Variants: Reptiles, like MAML, seek a decent initialization. However, it takes a different method, directly optimizing the model parameters using a type of gradient descent that promotes faster convergence. iii) Meta-SGD: - Meta-SGD optimizes the learning algorithm by determining an update rule for the model parameters. It modifies the stochastic gradient descent optimization approach during meta-training to improve generalization. iv) Prototype networks: - Few-Shot Classification: Prototypical Networks are intended for few-shot learning problems. They learn a prototype representation for each class during meta-training, making it useful for jobs with minimal labeled data. v) Matching networks: - Similarity Metric: Matching Networks use a learnt similarity metric to classify new instances based on relationships discovered during meta-training. They excel at things that need only one or a few learning attempts. Importance of Meta-Learning in the present casei) Adaptability to Different Tasks: In the current situation, there is an increasing demand for machine learning models that can swiftly adapt to various tasks without requiring considerable task-specific data. Meta-learning enables models to use knowledge from one task to quickly adapt to new, previously unforeseen challenges, increasing their versatility. ii) Effective Use of Limited Data: Meta-learning is ideal for situations in which gathering large labelled datasets for each job is either impractical or costly. Meta-learning allows models to generalize effectively even when data is limited by training on various tasks using few-shot learning. iii) Transfer Learning in Real-World Applications: Many real-world applications include tasks with similar underlying structures or patterns. Meta-learning's emphasis on transfer learning makes it especially useful when prior training on related tasks can greatly improve performance on a new task. iv) Automatic hyperparameter tuning: Meta-learning is more than just task adaptation; it can also include automatic tweaking of hyperparameters or model topologies. This capacity is critical in the current situation, where optimizing models for various tasks can be time-consuming and resource-intensive. Application of Meta-Learningi) Reduced annotation efforts: Meta-learning's few-shot learning nature eliminates the need for substantial human annotation, making it more practicable when gathering labelled data for each task is resource-intensive. ii) Continuous learning and lifelong learning: Meta-learning promotes continuous learning by allowing models to build knowledge across several tasks. This is consistent with the dynamic nature of data and tasks in many real-world applications. iii) Automatic Hyperparameter Tuning: Meta-learning goes beyond task-specific adaptation to incorporate hyperparameter optimization and model architecture design. This streamlines the procedure of fine-tuning models for various tasks. Meta-learning approachi) Adaptability to New and Unexpected Tasks: Meta-learning enables models to swiftly adapt to new, previously unforeseen tasks using minimum data. This adaptability is critical in dynamic situations where tasks might grow or emerge over time. ii) Few-shot learning for limited data scenarios: When generating huge labelled datasets is not feasible, meta-learning's few-shot learning capabilities enable models to generalize efficiently even with small samples per task. iii) Transfer learning across domains: Meta-learning makes information transfer easier from one task to another, allowing models to use previously learned knowledge to boost performance on related tasks. This is especially useful when jobs have common underlying structures or patterns. iv) Reduced annotation efforts: Meta-learning's few-shot learning nature eliminates the need for substantial human annotation, making it more practicable when gathering labelled data for each task is resource-intensive. v) Continuous learning and lifelong learning: Meta-learning promotes continuous learning by allowing models to build knowledge across several tasks. This is consistent with the dynamic nature of data and tasks in many real-world applications. vi) Automatic Hyperparameter Tuning: Meta-learning goes beyond task-specific adaptation to incorporate hyperparameter optimization and model architecture design. This streamlines the procedure of fine-tuning models for various tasks. How is multi-task learning related to meta-learning?Multi-task learning (MTL) and meta-learning aim to increase model performance across different tasks, but their underlying methodologies differ. Multi-task learning involves training a single model on numerous related tasks simultaneously to take advantage of shared representations and improve overall performance. On the other hand, meta-learning focuses on training models to learn efficient learning strategies across various activities, allowing them to efficiently adapt to new, previously unknown tasks using less data. While both seek to improve generalization, multi-task learning prioritizes joint optimization, whereas meta-learning focuses on gaining a higher-order understanding of learning processes, allowing for quick adaptation to novel tasks during both the training and testing phases. Despite these distinctions, the two paradigms frequently complement each other, as meta-learning can be multitasking. Challenges Facedi) Task Diversity and Representation: Diverse Task Selection: During meta-training, selecting a diverse set of tasks is critical to ensure that the model gains strong and generalizable information. Identifying tasks that accurately reflect the underlying distribution of prospective tasks might be difficult. ii) Data efficiency: Limited Data for Meta-Training: Because meta-learning is frequently used in few-shot learning scenarios, it is susceptible to lacking examples. Creating effective meta-learning algorithms that generalize from small examples remains difficult. iii) Meta-Overfitting: Over fitting to Meta-Training Tasks: Models might overfit to specific tasks discovered during meta-training, limiting their ability to generalize to previously unforeseen problems. Active research focuses on techniques to reduce meta-overfitting and improve adaptability. iv) Algorithm selection and initialization: Algorithm Sensitivity: The meta-learning algorithms used and how they are initialized can majorly impact performance. Identifying the best algorithms for certain applications and guaranteeing reliable initialization remains difficult. v) Transferability across domains: Domain Shift: Meta-learning models may fail when tasks have major domain shifts. Ensuring transferability across diverse domains and settings is difficult, especially with real-world applications. ConclusionFinally, meta-learning is a dynamic and novel approach to machine learning that addresses issues of adaptation, generalization, and efficiency across various activities. Meta-learning, which trains models to learn how to learn, allows for rapid adaptation to new, unknown tasks with insufficient data, making it especially useful in dynamic and changing contexts. Meta-learning has several benefits, including the capacity to enhance few-shot learning, transfer information across domains, and help the construction of versatile and adaptive models. However, the field of meta-learning is not without difficulties. Addressing difficulties such as task diversity, data efficiency, meta-overfitting, and algorithm sensitivity is critical to realizing meta-learning's full potential in real-world applications. Researchers continue to explore novel algorithms, model designs, and evaluation metrics that can help overcome these issues and improve the resilience and scalability of meta-learning systems.
Next TopicGeomagnetic Field Using Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








