| |

Machine Learning PipelineWhat is Machine Learning Pipeline?A Machine Learning pipeline is a process of automating the workflow of a complete machine learning task. It can be done by enabling a sequence of data to be transformed and correlated together in a model that can be analyzed to get the output. A typical pipeline includes raw data input, features, outputs, model parameters, ML models, and Predictions. Moreover, an ML Pipeline contains multiple sequential steps that perform everything ranging from data extraction and pre-processing to model training and deployment in Machine learning in a modular approach. It means that in the pipeline, each step is designed as an independent module, and all these modules are tied together to get the final result. The ML pipeline is a high-level API for MLlib within the "spark.ml" package. A typical pipeline contains various stages. However, there are two main pipeline stages: 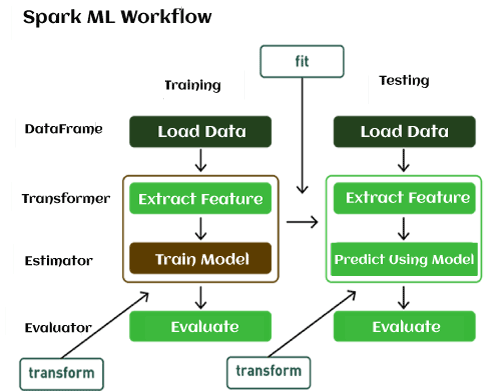
Importance of Machine Learning PipelineTo understand the importance of a Machine learning pipeline, let's first understand a typical workflow of an ML task: 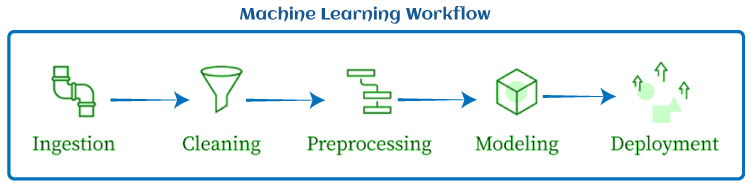
A typical workflow consists of Ingestion, Data cleaning, Data pre-processing, Modelling, and deployment. In ML workflow, all these steps are run together with the same script. It means the same script will be used to extract data, clean data, model, and deploy. However, it may generate issues while trying to scale an ML model. These issues involve:
For solving all the above problems, we can use a Machine learning pipeline. With the ML pipeline, each part of the workflow acts as an independent module. So whenever we need to change any part, we can choose that specific module and use that as per our requirement. We can understand it with an example. Building any ML model requires a huge amount of data to train the model. As data is collected from different resources, it is necessary to clean and pre-process the data, which is one of the crucial steps of an ML project. However, whenever a new dataset is included, we need to perform the same pre-processing step before using it for training, and it becomes a time-consuming and complex process for ML professionals. To solve such issues, ML pipelines can be used, which can remember and automate the complete pre-processing steps in the same order. Machine Learning Pipeline StepsOn the basis of the use cases of the ML model and the requirement of the organization, each machine learning pipeline may be different to some extent. However, each pipeline follows/works upon the general workflow of Machine learning, or there are some common stages that each ML pipeline includes. Each stage of the pipeline takes the output from its preceding stage, which acts as the input for that particular stage. A typical ML pipeline includes the following stages: 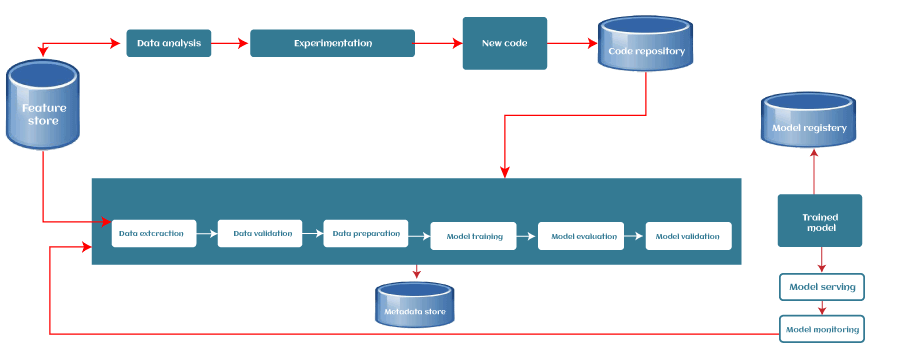
1. Data IngestionEach ML pipeline starts with the Data ingestion step. In this step, the data is processed into a well-organized format, which could be suitable to apply for further steps. This step does not perform any feature engineering; rather, this may perform the versioning of the input data. 2. Data ValidationThe next step is data validation, which is required to perform before training a new model. Data validation focuses on statistics of the new data, e.g., range, number of categories, distribution of categories, etc. In this step, data scientists can detect if any anomaly present in the data. There are various data validation tools that enable us to compare different datasets to detect anomalies. 3. Data Pre-processingData pre-processing is one of the most crucial steps for each ML lifecycle as well as the pipeline. We cannot directly input the collected data to train the model without pr-processing it, as it may generate an abrupt result. The pre-processing step involves preparing the raw data and making it suitable for the ML model. The process includes different sub-steps, such as Data cleaning, feature scaling, etc. The product or output of the data pre-processing step becomes the final dataset that can be used for model training and testing. There are different tools in ML for data pre-processing that can range from simple Python scripts to graph models. 4. Model Training & TuningThe model training step is the core of each ML pipeline. In this step, the model is trained to take the input (pre-processed dataset) and predicts an output with the highest possible accuracy. However, there could be some difficulties with larger models or with large training data sets. So, for this, efficient distribution of the model training or model tuning is required. This issue of the model training stage can be solved with pipelines as they are scalable, and a large number of models can be processed concurrently. 5. Model AnalysisAfter model training, we need to determine the optimal set of parameters by using the loss of accuracy metrics. Apart from this, an in-depth analysis of the model's performance is crucial for the final version of the model. The in-depth analysis includes calculating other metrics such as precision, recall, AUC, etc. This will also help us in determining the dependency of the model on features used in training and explore how the model's predictions would change if we altered the features of a single training example. 6. Model VersioningThe model versioning step keeps track of which model, set of hyperparameters, and datasets have been selected as the next version to be deployed. For various situations, there could occur a significant difference in model performance just by applying more/better training data and without changing any model parameter. Hence, it is important to document all inputs into a new model version and track them. 7. Model DeploymentAfter training and analyzing the model, it's time to deploy the model. An ML model can be deployed in three ways, which are:
However, the common way to deploy the model is using a model server. Model servers allow to host multiple versions simultaneously, which helps to run A/B tests on models and can provide valuable feedback for model improvement. 8. Feedback LoopEach pipeline forms a closed-loop to provide feedback. With this close loop, data scientists can determine the effectiveness and performance of the deployed models. This step could be automated or manual depending on the requirement. Except for the two manual review steps (the model analysis and the feedback step), we can automate the entire pipeline. Benefits of Machine Learning PipelinesSome of the benefits of using pipelines for the ML workflows are as follows:
Considerations while building a Machine Learning Pipeline
ML Pipeline ToolsThere are different tools in Machine learning for building a Pipeline. Some are given below along with their usage:
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








