| |

Xtreme: MultiLingual Neural NetworkIntroductionIn this article, we are discussing Xtreme MultiLingual neural NETwork. A recurrent neural network (RNN) is a type of neural network in which the output of a previous step is used as the input of the current step. In a traditional neural network, all inputs and outputs are independent of every difference. Still, when the next word in a sentence needs to be predicted, the previous sentence is needed to predict the previous work. Thus, RNN came into existence, which solved this problem with a hidden layer. The main and most crucial characteristic of RNN is the Hidden state, which recollects some statistics approximately a series. 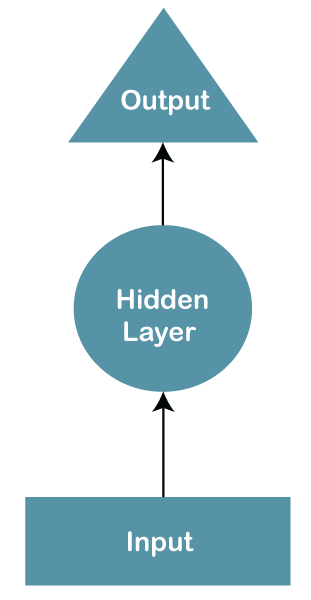
RNNs have a "memory" which remembers all statistics about what has been calculated. It uses the same parameters for every entry because it plays the identical mission on all the inputs or hidden layers to provide the output. This reduces the complexity of parameters, now not like one of a kind neural network. Working of RNNThe working of an RNN may be understood with the assistance of the below instance: there may be a deeper network with one enter layer, three hidden layers, and one output layer. Then like one-of-a-kind neural networks, each hidden layer will have its non-public set of weights and biases, allowing, say, for hidden layer one, the weights and biases are (w1, b1), (w2, b2) for the second hidden layer, and (w3, b3) for the 0.33 hidden layer. Because of this, every one of those layers is independent of the alternative, i.e., they do now not memorize the previous outputs. Xtreme Task and Evaluation:The duties blanketed in XTREME cowl several paradigms, which include sentence type, structured prediction, sentence retrieval, and query answering. Consequently, for models to succeed on the XTREME benchmarks, they should examine representations that generalize to many preferred cross-lingual switch settings. Each of the tasks covers a subset of the 40 languages. To gain additional statistics within the low-resource languages used for analyses in XTREME, the check units of two consultant duties, natural language inference (XNLI) and query answering (XQuAD), have been routinely translated from English to the closing languages. We display those fashions using the translated check sets for these tasks exhibited performance similar to those using human-labeled test units. 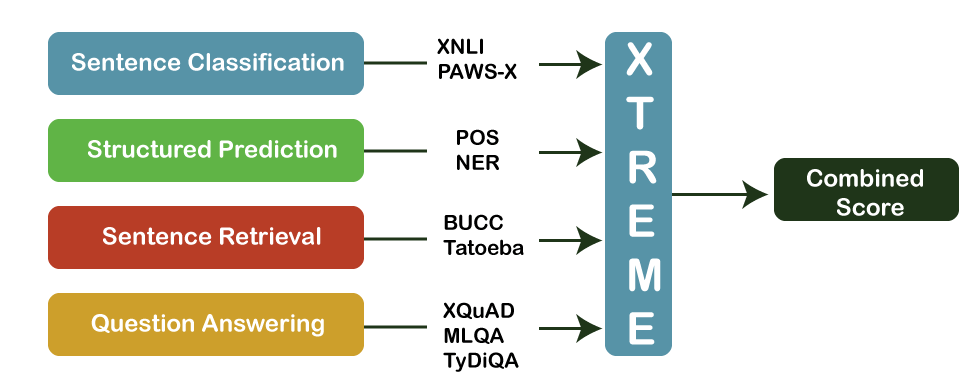
Zero-shot of Evaluation:To evaluate performance using XTREME, models should first be pre-educated on multilingual textual content using goals encouraging move-lingual mastering. Then, they may be nice-tuned on venture-particular English information, considering that English is the most likely language in which labeled statistics is available. XTREME then evaluates these fashions on zero-shot cross-lingual switch performance, i.e., on different languages without assignment-particular data. The three-step system, from pre-education to nice-tuning to the 0-shot switch, is shown in the figure under. In exercise, one of the benefits of this 0-shot putting is computational performance - a pre-educated version handiest wishes to be fine-tuned on English data for every task and can then be evaluated at once on other languages. Though, for tasks where labeled facts are to be had in different languages, we also compare them against first-class-tuning on in-language data. Ultimately, we offer a composite score by acquiring the 0-shot scores on all nine XTREME tasks. Test Bed for Transfer Learning:We experiment with several state-of-the-art pre-trained multilingual models, including Multilingual BERT, a multilingual extension of the popular BERT model; XLM and XLMR, two larger versions of multilingual BERT on more data for training; and a large-scale multilingual machine translation model, M4. A common feature of these models is that they are pretrained on large amounts of data from multiple languages. We chose variants of these pretrained models for our experiments on about 100 languages, including the 40 languages we benchmarked. While models perform close to humans on most existing English tasks, many other languages perform much worse. Among all the models, the structured prediction and question-answering tasks have the largest performance gap in English and the rest of the languages. In contrast, the structured prediction and sentence retrieval tasks have the largest performance gap cross-linguistic. For example, in the figure underneath, we show the overall performance of the first-rate-performing model in the 0-shot putting, XLM-R, by using venture and language throughout all language households. The ratings across tasks are not similar, so the main consciousness must be the relative ranking of languages throughout duties. As we can see, many excessive-aid languages, specially from the Indo-ecu language family, are constantly ranked higher. In comparison, the version achieves decreased overall performance in many languages from other language families, including Sino-Tibetan, Japonic, Koreanic, and Niger-Congo languages. In standard, we made several thrilling observations. In the zero-shot putting, M4 and mBERT are competitive with XLM-R on some of the less difficult obligations. At the same time, the latter outperforms them in the specifically tough query answering duties, amongst others. For example, on XQuAD, XLM-R scored 76.6 compared to 64.5 for mBERT and 64.6 for M4, with comparable spreads on MLQA and TyDi QA. We find that baselines utilizing system translation, translating the schooling records, and test facts are very aggressive. On the XNLI task, mBERT scored 65.4 in the zero-shot transfer placing and 74.0 using translated schooling facts. We examine that the few-shot setting (i.e., the usage of restricted quantities of in-language labeled statistics, while available) is specifically aggressive for simpler duties, together with NER, however much less useful for the extra complicated query answering responsibilities. This could be seen in the performance of mBERT, which improves by using 42% on the NER venture from 62.2 to 88.3 within the few-shot putting, but for the query answering undertaking (TyDi QA), most effective improve via 25% (59.7 to 74.5). A huge gap between overall performance in English and other languages remains throughout all models and settings, suggesting much capacity for research on the move-lingual switch. Transfer Analytics of the Cross-lingual:Like previous observations on the generalizability of deep models, results improve if more pretrained data is available for a language, e.g., mBERT has more pretrained data. However, we found that this correlation does not apply to structured prediction tasks, parts of speech (POS) tagging, and named entity recognition (NER), suggesting that pre-trained models currently deeps can only partially utilize pre-trained models. - training data to be transferred to such syntactic tasks. We also found issues with converting the template to non-Latin scripts. This is evident in the POS task, where mBERT achieves zero shooting accuracy of 86.9 in Spanish but only 49.2 in Japanese. For the herbal language inference task, XNLI, we find that a version makes the same prediction on a check example in English and at the equal example in another language approximately 70% of the time. Semi-supervised strategies might be useful in encouraging stepped forward consistency among the predictions on examples and their translations in different languages. We also locate that model's warfare to expect POS tag sequences that were no longer visible in the English training statistics on which they have been nice-tuned, highlighting that these fashions conflict with studying the syntax of other languages from the huge amounts of unlabelled records used for pre-schooling. For named entity reputation, models have the maximum difficulty predicting entities no longer visible in the English training data for distant languages - accuracies on Indonesian and Swahili are 58.0 and 66.6, respectively, compared to 82.3 and 80.1 for Portuguese and French. Multilingual Transfer Learning:English has been the focus of maximum latest advances in NLP despite being spoken by way of best around 15% of the world's populace. We consider that building on deep contextual representations, and we now have the gear to make huge development on structures that serve the remainder of the sector's languages. We hope that XTREME will catalyze studies in multilingual transfer mastering, just like how benchmarks which include GLUE and SuperGLUE have spurred the development of deep monolingual fashions, consisting of BERT, RoBERTa, XLNet, AlBERT, and others. Stay tuned to our Twitter account for records on our upcoming internet site launch with a submission portal and leader board. Advantages of the neutral network:
Disadvantages of the Neutral Network:
Application of the Neutral Network:Medicine, Electronic Nose, Securities, and Loan Applications are proof-of-concept apps that use neural networks to decide whether to grant a loan, which has been used more successfully than many.
Next TopicHistory of Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








