| |

Document Classification Using Machine Learning
In today's era of digital advancements, businesses, and institutions encounter the formidable task of managing copious volumes of information contained within diverse document formats. The efficient organization and classification of this wealth of information are paramount to enable swift retrieval and informed decision-making. In response, the application of machine learning methods to document classification has arisen as a potent remedy, enabling automation and streamlining of these critical processes. The classification of the documentation assumes a paramount role in the realm of information management, facilitating streamlined storage, retrieval, and analysis. Through the categorization of documents into pertinent classes or categories, organizations are empowered to construct organized repositories, foster knowledge dissemination, and amplify overall productivity. Traditional manual classification methods are laborious, error-prone, and time-consuming, thus underscoring the immense value of automated machine learning techniques in this context. Sophisticated machine learning algorithms possess the capability to meticulously scrutinize document content, structure, and metadata, thereby ensuring precise classification. A plethora of supervised learning techniques, including Naive Bayes, Support Vector Machines (SVM), and Random Forests, find frequent applications in classification endeavors. These algorithms learn from annotated training data, where documents are assigned corresponding categories. In addition, unsupervised learning methods such as K-means clustering and hierarchical clustering can be harnessed to unveil concealed patterns and aggregate akin documents without the need for pre-established category information. Now we will try to implement it into code. Code: Importing LibrariesLoading the DatasetOutput: 
Output: 
Note: Class imbalance in the dataset is moderate. Divided in a tiered wayOutput: 
GPU APIsFirst, we need to check for the availability of the API. Output: 
Preparing the DataWe need to prepare the data that would be suitable for the computation. Output: 
Output: 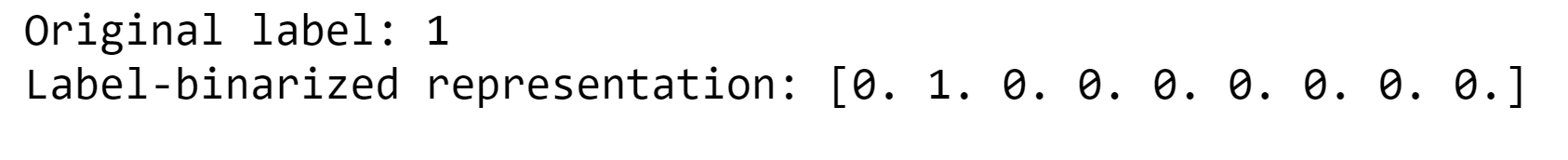
Preprocessing the DataOutput: 
Output: 
Output: 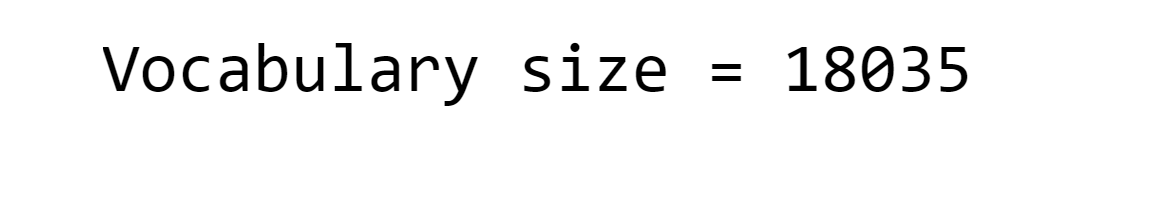
Helper MethodsHelper methods are functions or procedures that assist in performing specific tasks within a program. These methods are designed to handle repetitive or common operations, making the code more modular, readable, and maintainable. Modeling Here, We will train the model and look at its accuracy. 1. Simple Feed Forward Network Output: 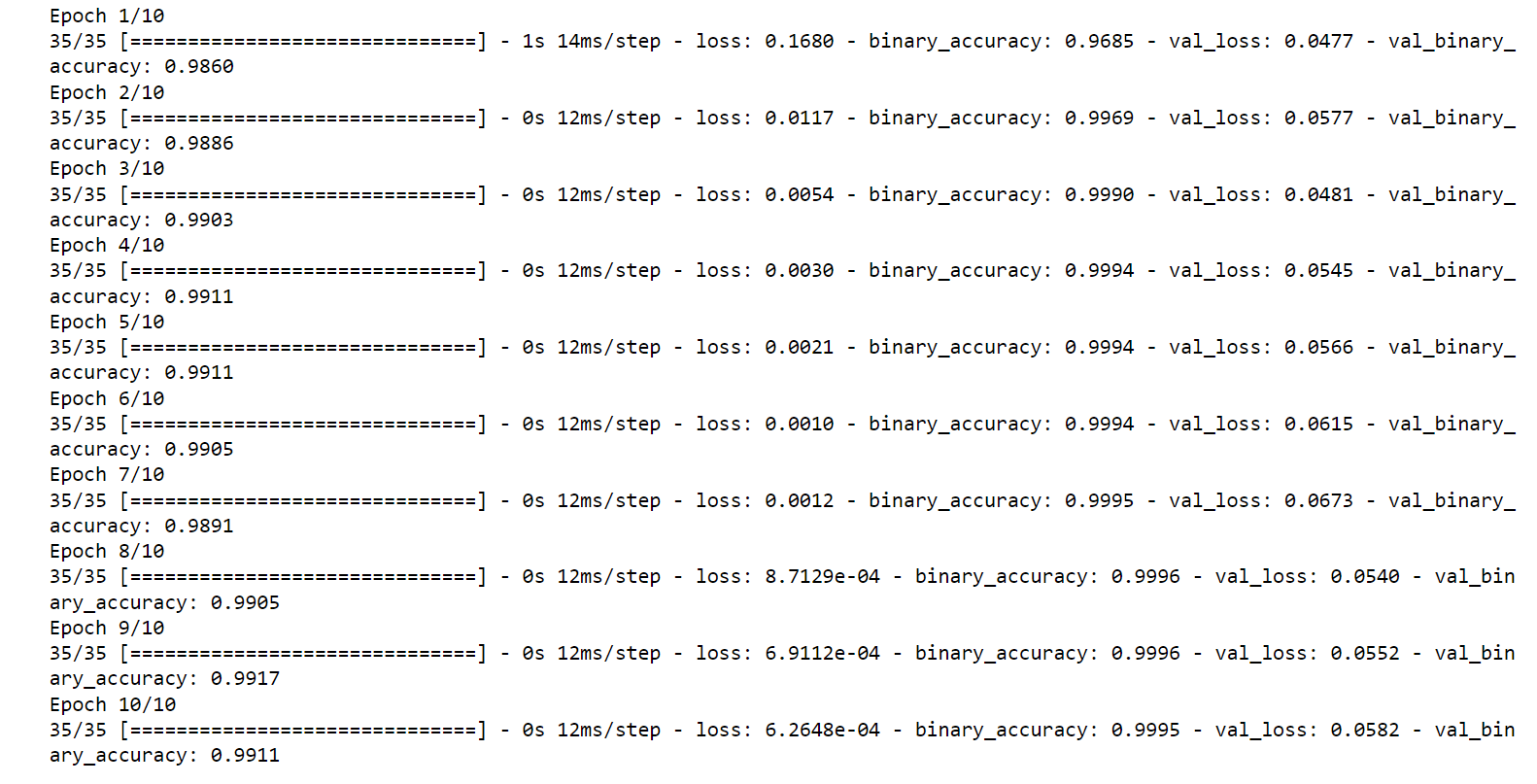
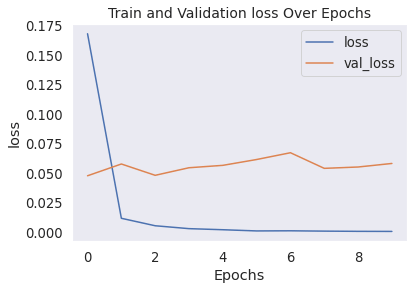
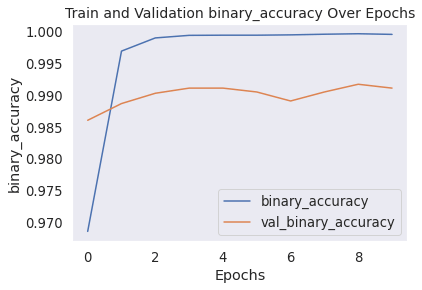
Output: 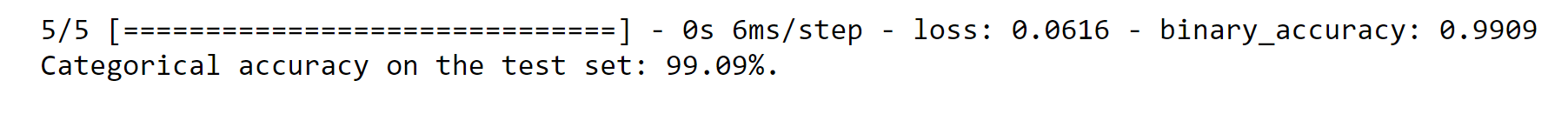
Output:
The model evaluation results show a relatively high test accuracy for most labels. Label 6 has a lower accuracy of 88.89%, indicating that the model may struggle in correctly classifying instances belonging to this label. Label 8 also has a lower accuracy of 77.78%. Labels 4 and 5 exhibit accuracies of 85.71% and 80.00%, respectively, indicating some room for improvement in accurately predicting instances of these labels. 2. Deeper FNN Output: 
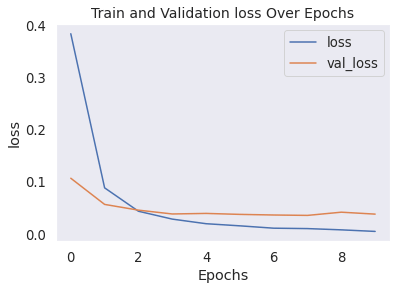
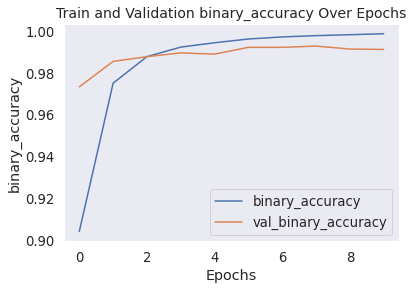
Output: 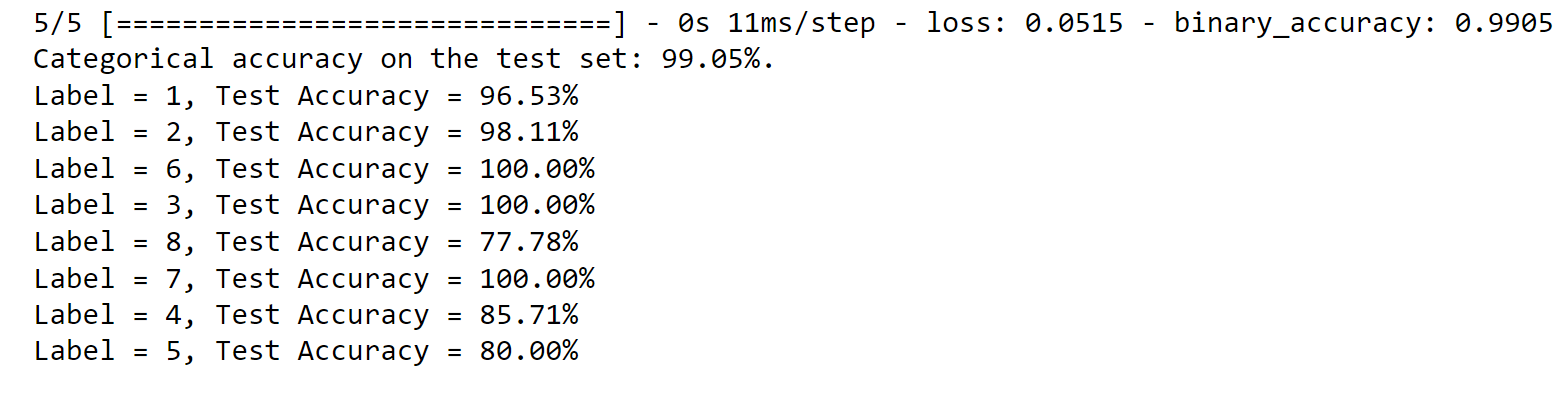
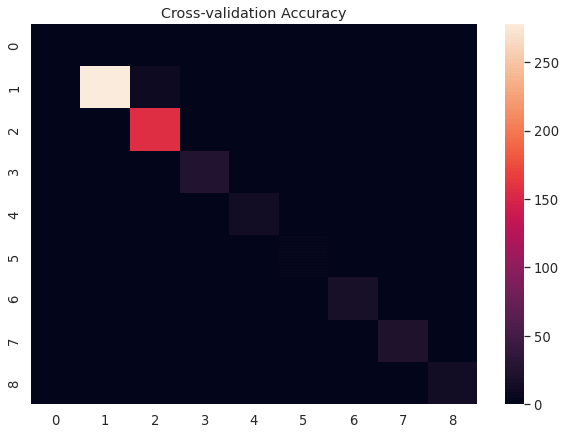
The results of the model evaluation indicate impressive performance with a high binary accuracy of 99.05% on the test set. The model demonstrates strong predictive capabilities, with most labels achieving high accuracy. However, there may be room for improvement for labels 8 and 5, which have lower accuracies. Further analysis and refinement of the model could potentially enhance its performance across all labels. ConclusionThe utilization of machine learning for document classification presents a groundbreaking remedy to efficiently organize and retrieve information. This transformative approach automates the categorization process, enabling organizations to streamline their operations, enhance decision-making, and unveil the concealed value residing within their document repositories. As technological advancements continue to unfold and challenges are systematically tackled, the future holds immense potential for the development of increasingly sophisticated and accurate documentation classification systems. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








