| |

Injury Prediction in Competitive Runners Using Machine Learning
Running is a popular sport worldwide, with a large number of individuals participating in activities such as jogging, running, or trail running. In the United States alone, around 60 million people engaged in these activities in 2017. However, a worrisome statistic reveals that about half of the runners experience injuries annually. Dealing with these injuries can be a difficult and time-consuming process, prompting runners to adopt various strategies to minimize the chances of getting injured. Some of these preventive measures include using rollers, getting massages, and seeking guidance from professional coaches. Unfortunately, not everyone can afford these resources, making injury prevention a significant concern for many runners. In response to this concern, experts and data scientists are increasingly embracing the capabilities of machine learning to forecast and avert injuries in competitive runners. By harnessing sophisticated algorithms and extensive datasets, machine learning models possess the ability to transform injury prevention methodologies, ultimately elevating the overall welfare of athletes. Benefits of Injury Prediction in Competitive Runners Using Machine Learning
Challenges of Injury Prediction in Competitive Runners Using Machine LearningWhile the potential of machine learning in injury prediction is promising, there are also significant challenges that need to be addressed:
Machine Learning Injury Prediction Using PythonAbout the DatasetThe dataset comprises a comprehensive training log from a renowned Dutch high-level running team spanning seven years (2012-2019). It includes middle and long-distance runners competing in races between 800 meters and the marathon. This choice is justified by their comparable endurance-based training regimes. Notably, the team's head coach remained consistent throughout the data collection period. There are records from 74 runners in the dataset, with 27 women and 47 men. On average, the athletes had been part of the team for about 3.7 years. The majority of runners competed at the national level, while some participated in international competitions. The study strictly adhered to the Declaration of Helsinki guidelines and received approval from the ethics committee of the second author's institution. Here, we will try to predict the injury in the competitor and look for the best model for the injury prediction.
We'll begin with basic data exploration to determine if the data set contains any anomalies or inconsistencies. Output: 
Output: 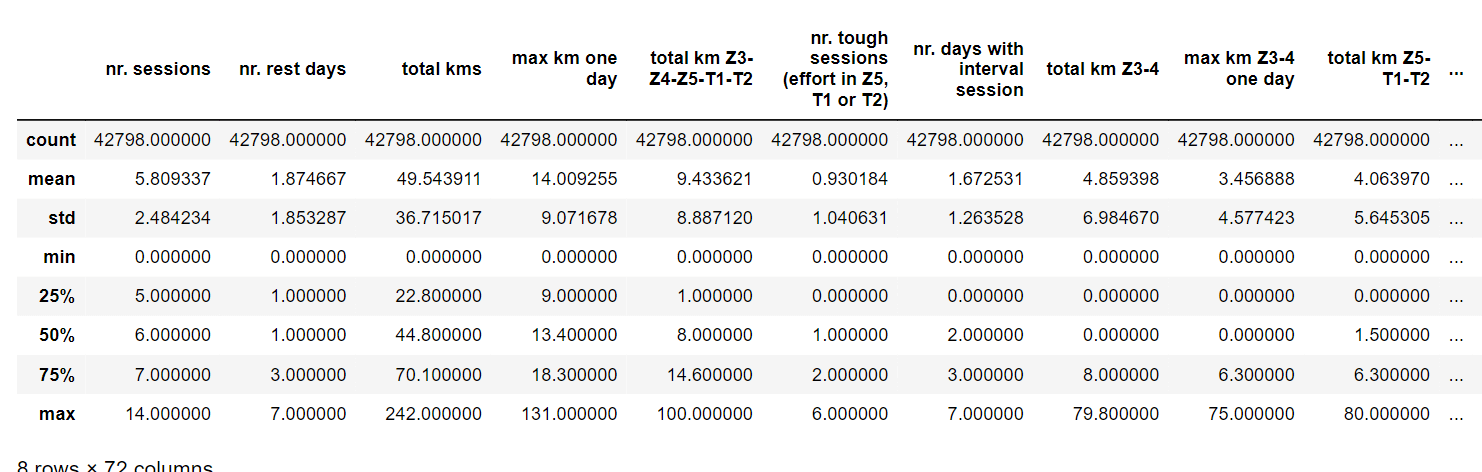
Output: 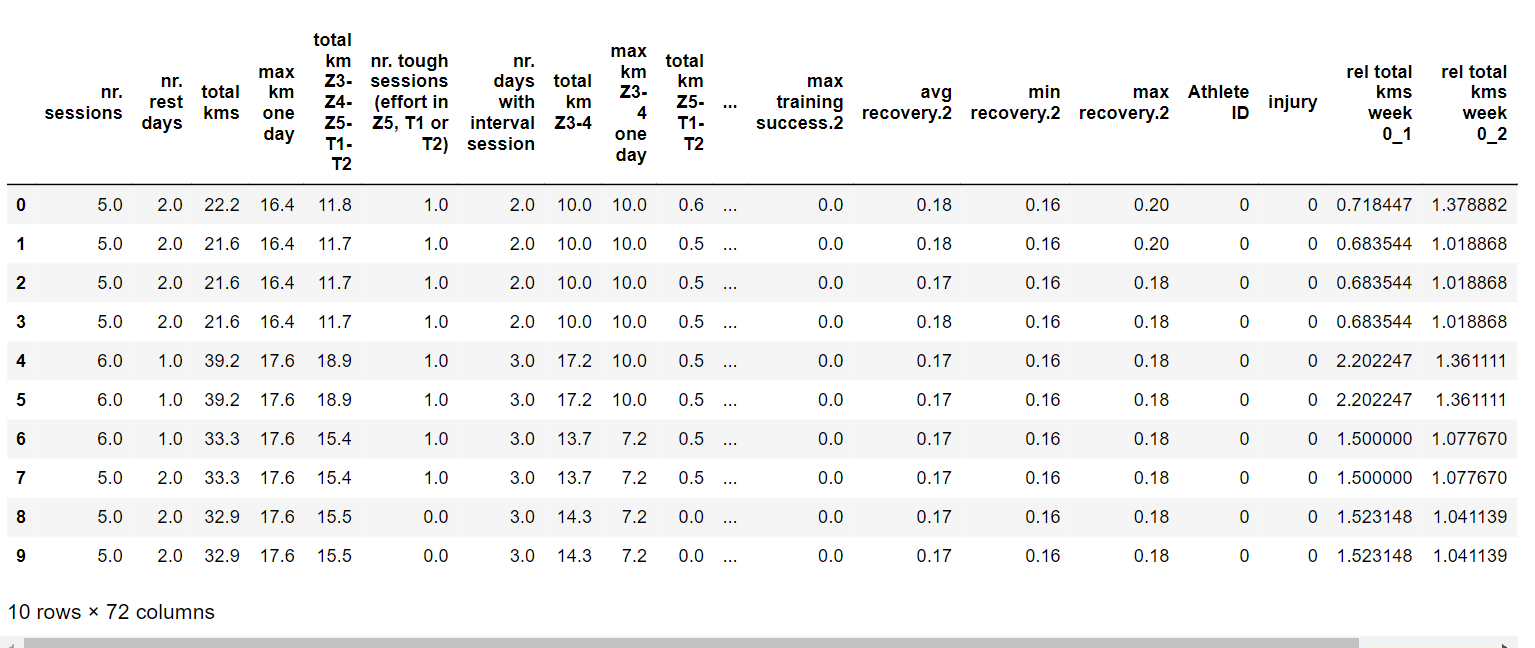
The dataset we have is quite high-dimensional, making it challenging to begin data analysis. To simplify the process, we decided to drop certain attributes based on empirical analysis. Specifically, we removed attributes that were related to how the person feels, as we wanted to focus on predicting data solely based on quantitative running quality. Although attributes related to recovery could potentially provide valuable insights, relying solely on survey questions to gauge a runner's physical condition is challenging and may not yield accurate results. To maintain objectivity and adopt a data-driven approach in our analysis, we chose to exclude subjective attributes and focus on more concrete and measurable factors. Output: 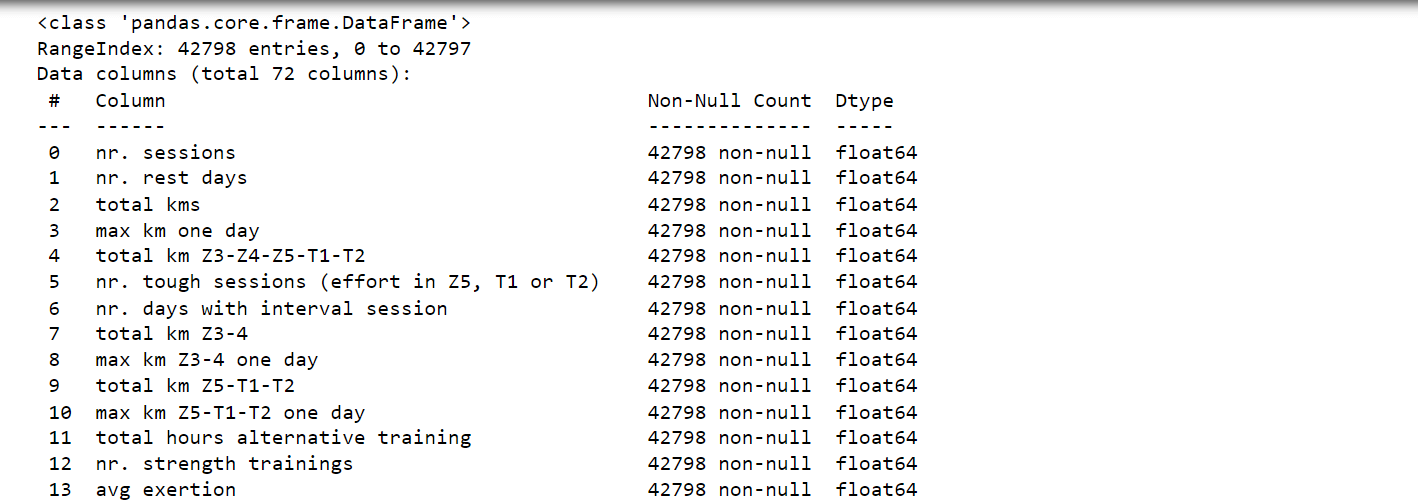
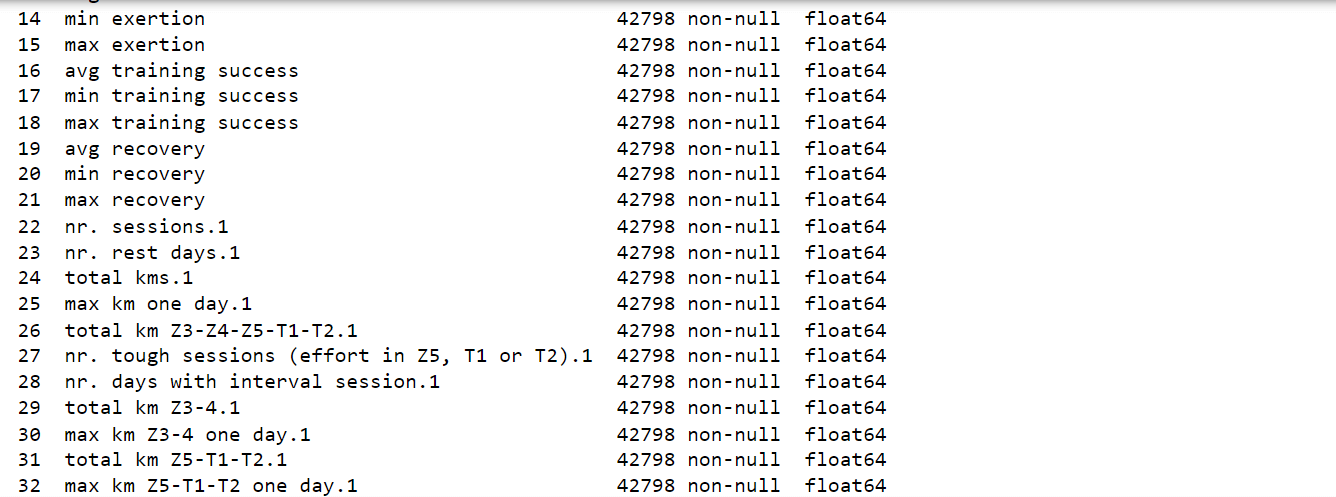
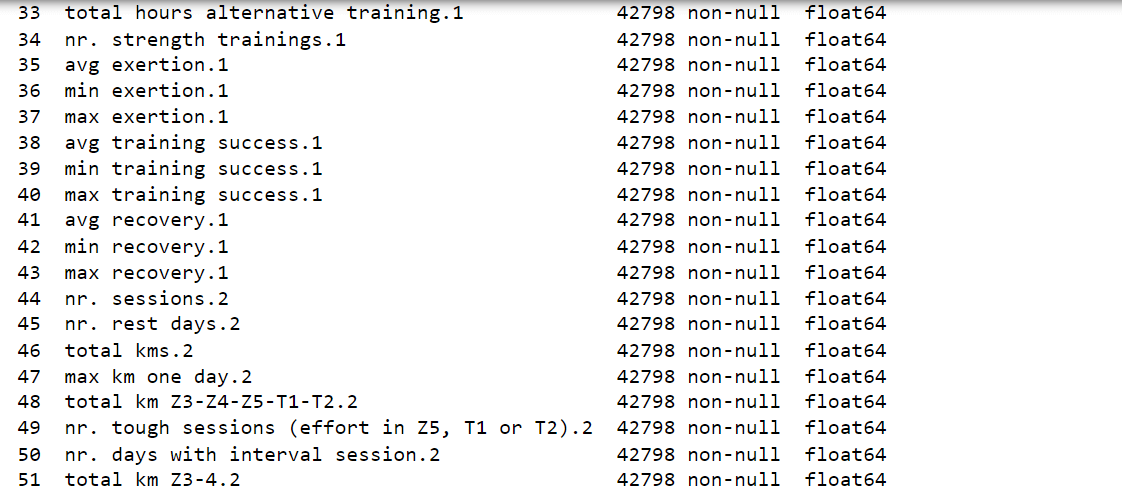
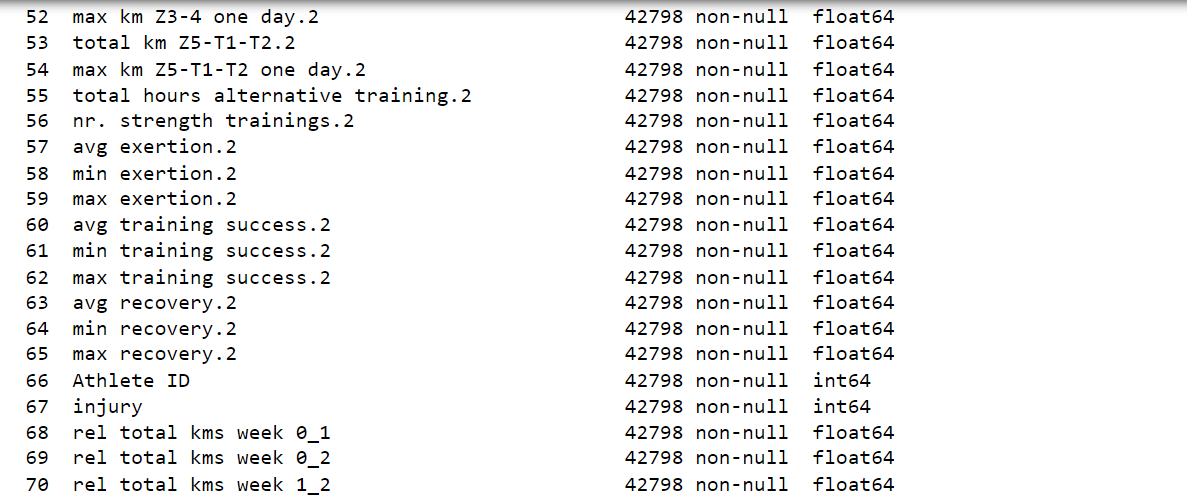
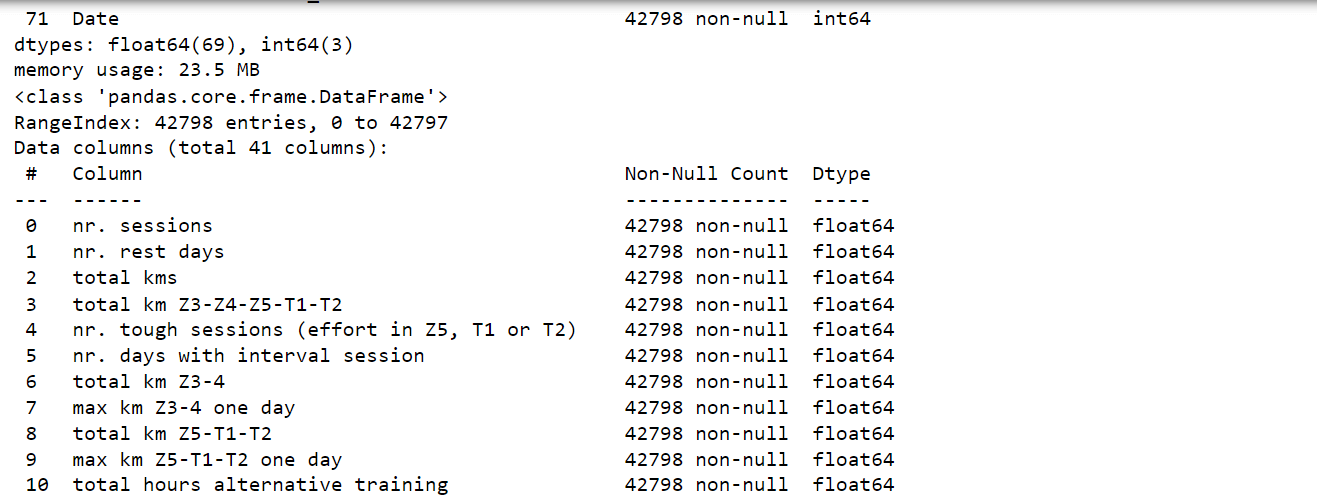
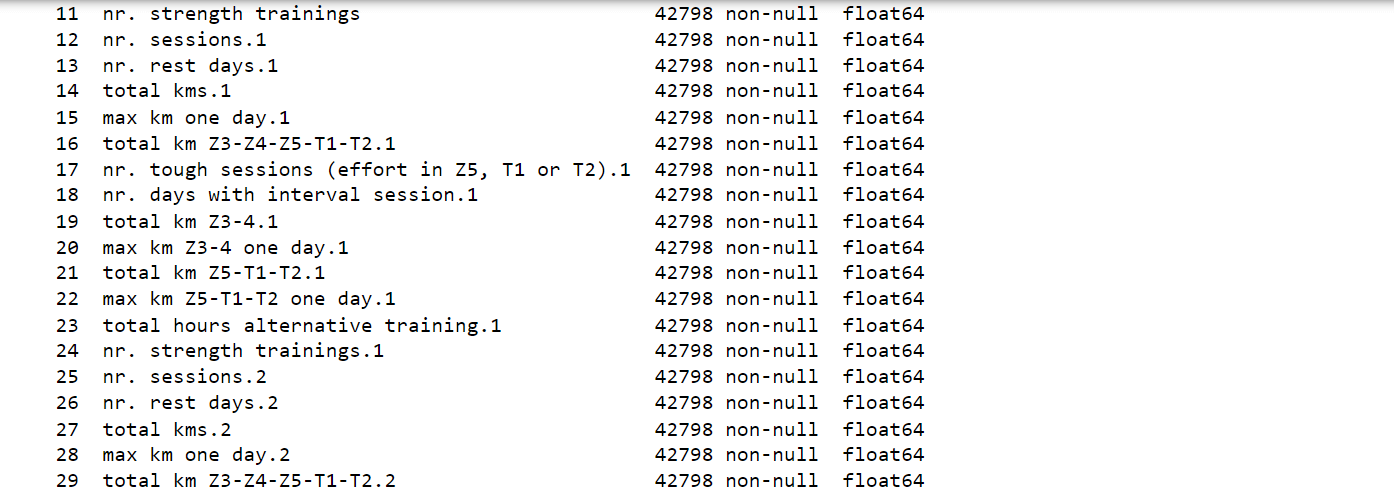
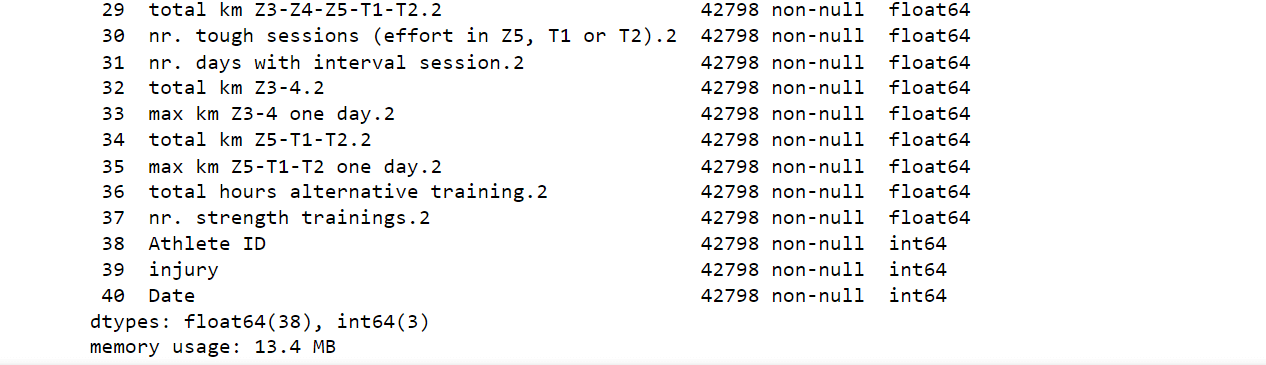
After careful analysis, we have successfully reduced the number of attributes in the dataset from 72 to 41. While this progress is promising, the dataset still remains high-dimensional, posing a challenge for further analysis and modeling. Output: 
Altogether, there are 74 athletes in the dataset. Now, let's focus on examining the training data of the first athlete to gain insights into their training patterns. Output: 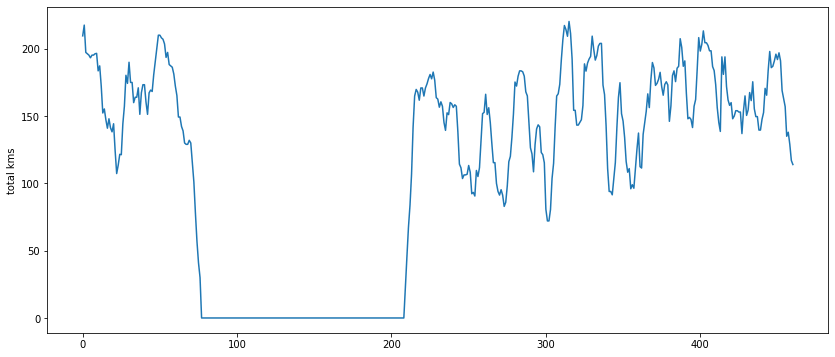
This graph raises some intriguing questions. We wonder why there is a significant decline in training for such an extended period for this particular athlete. If each data point represents a week, being injured for over one hundred weeks seems unusual. Alternatively, if the points indicate days, one hundred days of injury is still quite substantial and merits further investigation. The attributes with '.1', '.2', and '.3' in the data set are perplexing. We find it challenging to comprehend their significance concerning the dates attribute, even after referring to the Metadata file. The meaning and relevance of these attributes remain unclear and warrant further clarification. Output: 
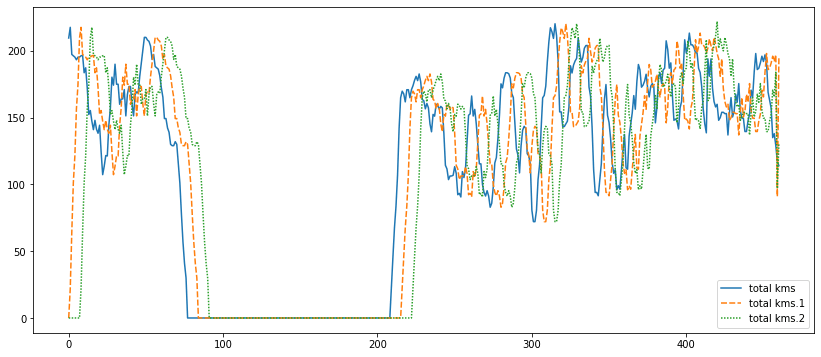
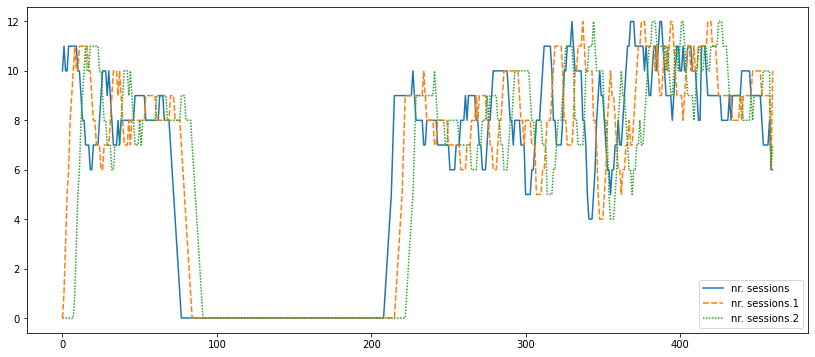
The 'dates' attribute in this dataset is also puzzling. To gain a clearer understanding of its significance, we will attempt to visualize it and explore its patterns. Output: 

The sudden jump in the 'dates' attribute from 400 to 700 for an athlete is perplexing and raises questions. To make accurate predictions and analyze the data effectively, we need consecutive and sequential dates. Despite some uncertainty and potential missing insights, we will still attempt to classify the running data. Moreover, our data exploration revealed a significant bias towards non-injured data points in the dataset. This imbalance could impact the model's performance and predictions. Output: 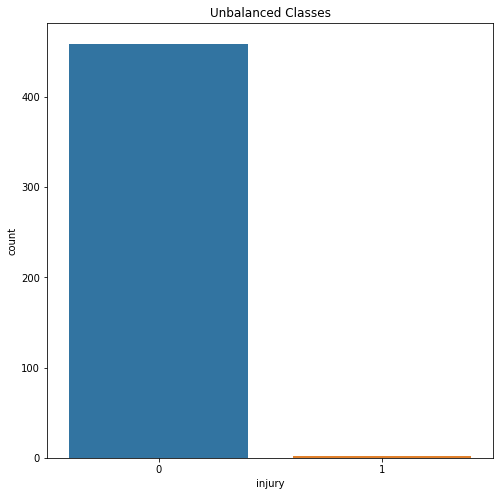
In this visualization, it becomes evident how heavily skewed the dataset is towards non-injured cases. Output: 
In order to prevent overfitting in our predictive models, we have balanced the dataset using sampling techniques. This ensures that both the injured and non-injured cases are equally represented in the training data.
Here, we will employ various machine learning algorithms along with their accuracies and confusion matrix. Let's begin by demonstrating the impact of a skewed dataset. In the unbalanced dataset, the accuracy of the classifier appears to be very high because it simply identifies all data points as non-injured. However, this approach is not helpful for the objectives of this project, as it fails to accurately predict the injured cases. Output: 
Output: 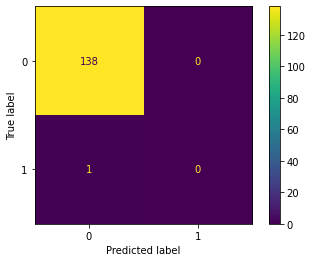
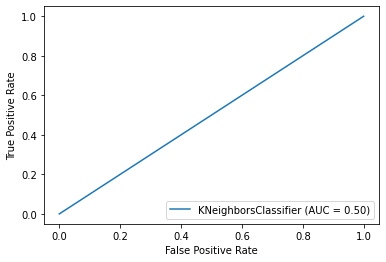
In the confusion matrix shown above, all data points are classified as non-injured. To address this issue, we will now proceed to use the balanced dataset. Output: 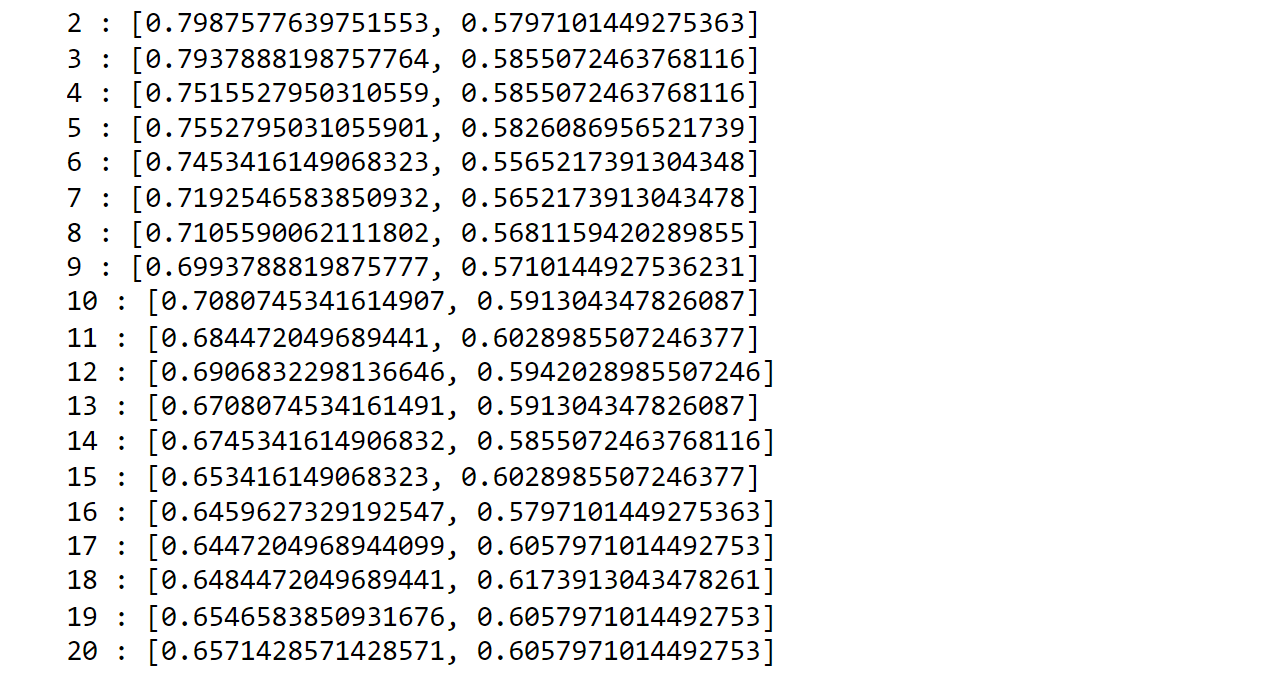
In this analysis, we observe that as we increase the parameter k, the training accuracy declines notably (from approximately 80% to 65%), while the testing accuracy slightly improves (from around 58% to 60%). To evaluate the model's performance in handling both non-injured and injured data, we will utilize the confusion matrix. Output: 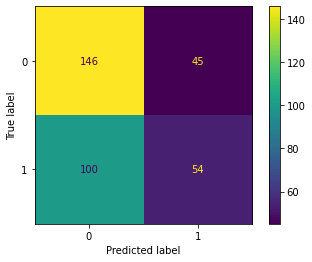
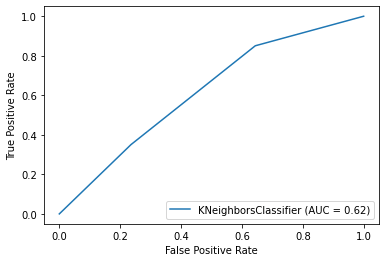
With a k value of 2, the classifier demonstrates higher accuracy in predicting non-injured data. Output: 
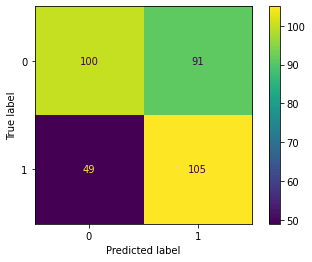
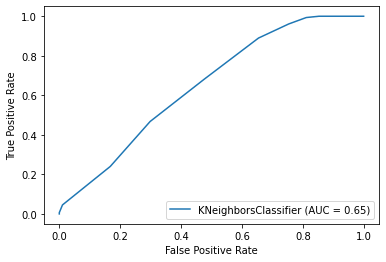
When using a high k value of 21, the injury prediction becomes more accurate. However, this also leads to a significant increase in false positives for non-injured data, meaning that the classifier mistakenly identifies more people who are not injured as injured. After conducting extensive experimentation with various parameter values, we identified the optimal equilibrium point with a k value of 12. The classifier achieved an overall accuracy rate of 60%, displaying 52% accuracy in predicting non-injured data points and 68% accuracy in predicting injured data points. Considering the dataset's inherent bias, this level of accuracy is commendable. Nevertheless, we continue to explore alternative binary classifiers and different balancing methods to further enhance the accuracy of our predictions. The code below demonstrates the utilization of a support vector machine classifier to make injury predictions for data points. To handle the imbalanced nature of our dataset, we adopt the undersampling technique. By balancing the representation of injured and non-injured cases, we aim to improve the classifier's accuracy in making predictions for both categories. Output: 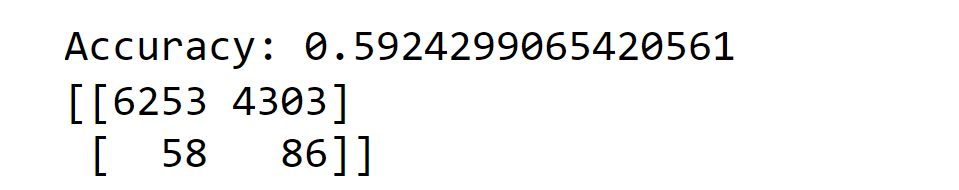
In the code below, we utilize a support vector machine classifier to make predictions about whether a data point corresponds to an injury or not. To address the issue of our imbalanced dataset, we employ the oversampling technique. This approach aims to create a more balanced representation of the data by duplicating or generating additional instances of the minority class (injured data), allowing the classifier to achieve better accuracy in predicting both injured and non-injured cases. Output: 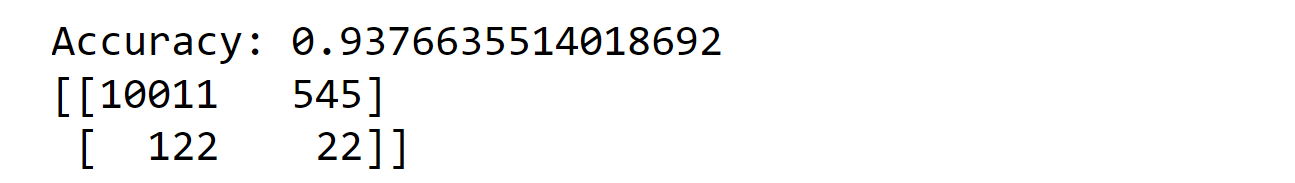
In the code below, we implement a bagging classifier with undersampling to make predictions about whether a data point corresponds to an injury or not. Output: 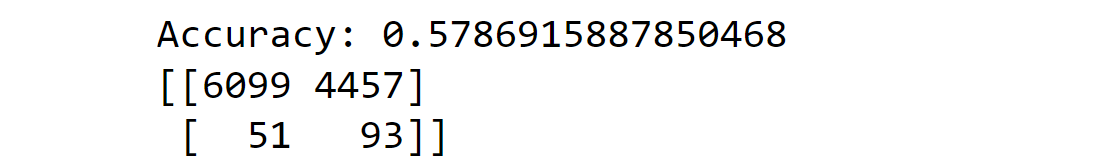
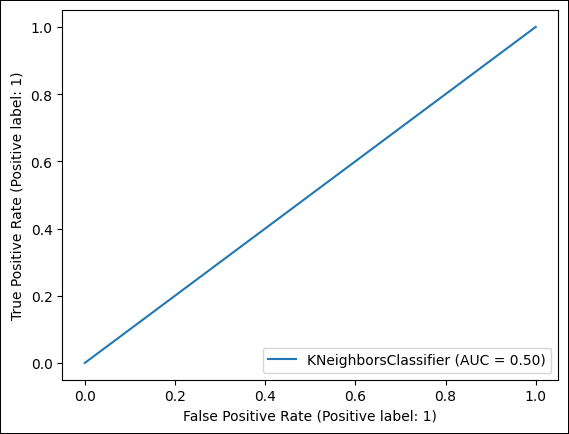
In the code below, we implement a bagging classifier with oversampling to make predictions about whether a data point corresponds to an injury or not. Output: 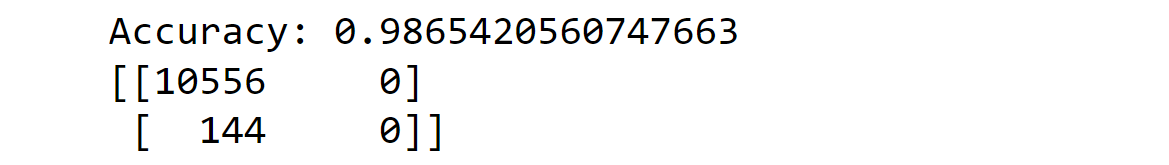
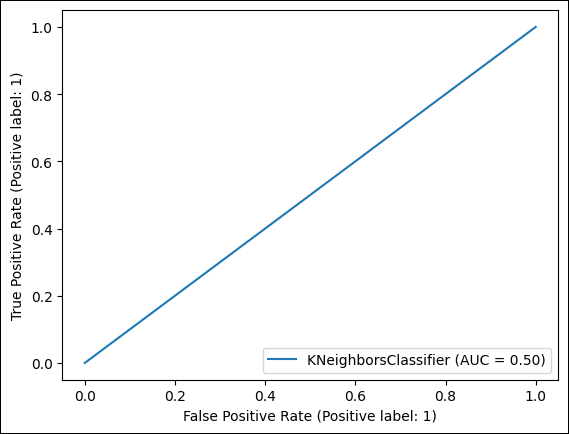
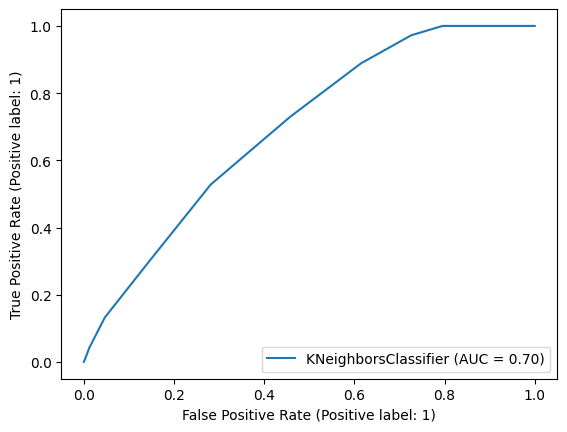
Here, we use a bagging classifier to predict whether a data point is injured or use the undersampling technique to counter our imbalanced data set. Output: 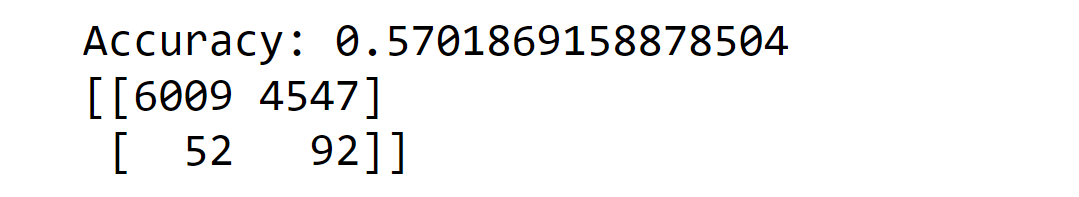
We employ a bagging classifier to determine if a data point corresponds to an injury, addressing the imbalance in our dataset through the use of the oversampling technique. Output: 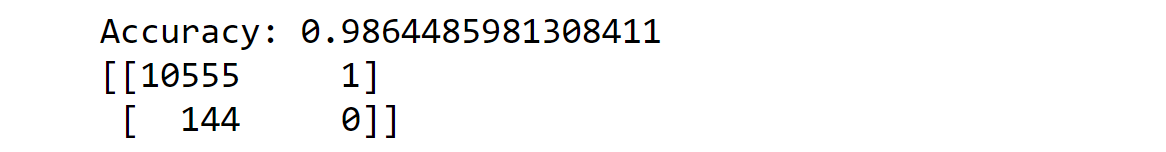
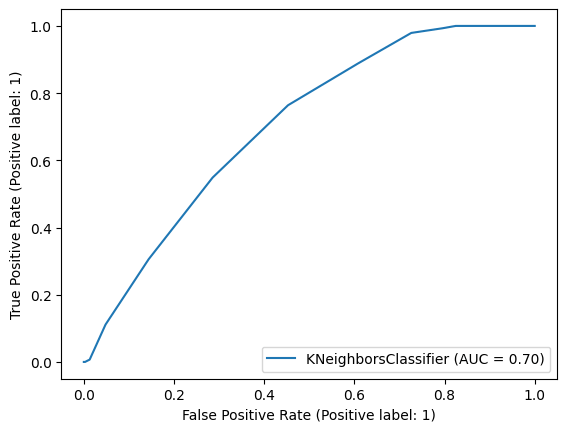
The model's accuracy was influenced mainly by the sampling method used. The oversampling approach performed better in classifying non-injured data points, while the undersampling method excelled in accurately identifying the injured data points. To balance the data set, we applied various strategies like sampling, oversampling, and undersampling. Afterward, we evaluated the different balanced datasets using multiple binary classifiers, including KNN, SVM, Bagging, and XGBooster. The best performance was achieved using XGBooster and Bagging, with an impressive accuracy rate of around 99%. Future Aspects of Injury Prediction in Competitive Runners Using Machine LearningMachine learning holds great promise for sports medicine and athlete care. With advancements in wearable technology and data collection methods, machine learning models can analyze comprehensive datasets, providing deeper insights into athletes' performance, biomechanics, and physiological parameters. Integrating multi-modal data, such as genetics and environmental conditions, may reveal new patterns contributing to injury risk. Longitudinal studies will be crucial in building accurate prediction models by monitoring athletes over time. Moreover, machine learning can offer personalized injury prevention plans based on individual characteristics. By embracing these advancements, injury prediction can optimize athlete performance and foster a healthier and more successful athletic community. ConclusionInjury prediction in competitive runners using machine learning holds tremendous promise for transforming sports medicine and enhancing athlete well-being. With the aid of advanced algorithms and extensive datasets, machine learning models offer real-time injury risk assessments, personalized training guidance, and data-driven injury prevention strategies. However, the full benefits of machine learning in injury prediction can be achieved by addressing challenges like data quality, model interpretability, and accounting for complex risk factor interactions. Collaboration between data scientists, sports medicine experts, coaches, and athletes will be key in overcoming these hurdles and unlocking the full potential of machine learning in competitive running. As researchers and practitioners explore the possibilities, injury prediction through machine learning can revolutionize how competitive runners approach training, recovery, and injury prevention, ultimately leading to a healthier and more successful athletic community.
Next TopicProtein Folding Using Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








