| |

Different Types of Methods for Clustering Algorithms in MLThe algorithms for clustering are of a variety. They do not have all the models they use for their clusters and therefore are not easily categorized. In this tutorial, we will give the most popular methods of algorithms for clustering because there are more than 100 clustering algorithms that have been published. Distribution Based Methods:It is a clustering model that can fit data based on the likelihood that it is likely to be part of an identical distribution. The clustering that is done could be either normal as well as gaussian. Gaussian distribution can be more prevalent in the case of a fixed number of distributions, and all the data that is to come will be incorporated into it so that data distribution can be maximized. This results in the grouping, which is illustrated in the figure as follows: 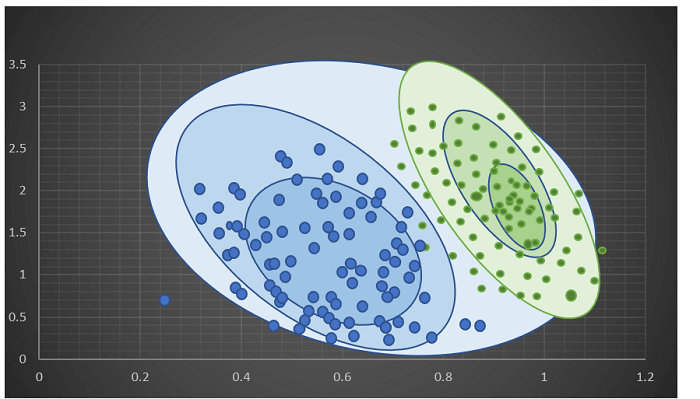
Additionally, Distribution-based clustering generates clusters that rely on concisely specified mathematical models for the data, which is a high-risk assumption for certain data distributions. This model is able to work well with synthetic data as well as diversely sized clusters. However, this model could have problems if the constraints were not applied to reduce the complexity of the model. For example: The expectation-maximization algorithm, which uses multivariate normal distributions, is one of the popular examples of this algorithm. Centroid Based Methods:This is the most basic of the algorithms for iterative clustering in which clusters are formed due to the proximity of points of information to the centre of the cluster. In this case, the cluster's centre, i.e., the centroid, is constructed in a way that the distance between data points is minimal with the centre. This is the most basic of the NP-Hard challenges, and therefore solutions are usually constructed over several trials. For example: K- which is a reference to the algorithm, can be one of the most popular instances of the algorithm. 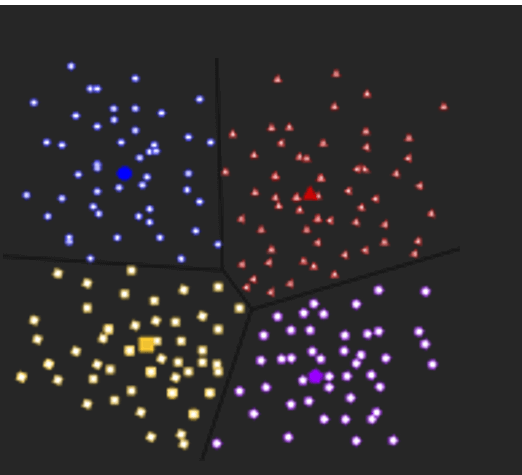
The main issue in this algorithm is that we have to define K prior to the start of the process. The algorithm also has issues when dense clusters are based on density. Connectivity Based Methods:The fundamental idea behind the model based on connectivity is similar to the Centroid model, that is basically defining clusters on the basis of the distance between data points. This model is based on the idea that data points that are closer share the same behaviour in comparison to data point further away. The choice of the distance functions is a matter of personal preference. It's not a simple parting out of the data set; rather, it offers an extensive array of clusters that merge at specific distances. These models are easy to understand, but they lack the ability to scale. 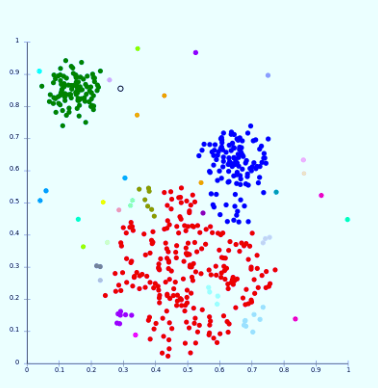
For example: Hierarchical algorithm and its variations. Density Models:This model of clustering will search the data space to find areas with the various amount of data points that are in this data area. It will separate different density areas according to the different densities that exist within the space of data. For example: DBSCAN in addition to OPTICS. 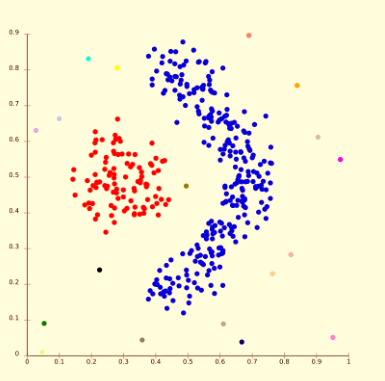
Subspace Clustering Method:Subspace-based clustering (subspace) is an unsupervised method that seeks to group data points into clusters in order that all the data points in one cluster are located in a linear subspace of low-dimensional. It is an extended form of feature selection in the same way as to feature selection. Subspace clustering requires a search technique and evaluation criteria; however, the subspace-based clustering method limits the range of criteria for evaluation. Subspace clustering algorithms localize the search to relevant dimensions and allow it to identify the cluster present across multiple subspaces. Subspace clustering was initially designed to solve specific computer vision issues that require the subspace structure to be merged into the data. Still, it is gaining more attention in the machine learning communities. It is used in movie and social network recommendations as well as biological datasets. Subspace clustering raises questions regarding data privacy since numerous of these applications work with sensitive data. Data points are believed to be incoherent since it protects only the distinct privacy of each aspect of a user instead of the complete profile of the database user. There are two types of subspace clustering based on their search strategies.
ConclusionIn this tutorial, we have discussed different types of methods used for clustering algorithms, which can be used for differentiating the attribute values.
Next TopicEM Algorithm in Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








