| |

Digit Recognition Using Machine LearningIn today's digital era, where vast amounts of data are generated every second, the ability to accurately recognize and classify digits holds immense value. Whether it's automated form processing, optical character recognition, or even enhancing user experience in various applications, digit recognition plays a vital role. At its core, digit recognition is the process of identifying and classifying handwritten or printed digits. Traditionally, this task required complex algorithms and extensive manual effort. However, with the advent of machine learning techniques, we can now automate this process by training models on large datasets of labelled digits. Machine learning algorithms equip us with the capability to derive valuable characteristics from unprocessed input data and comprehend patterns and connections. In the domain of digit recognition, Convolutional Neural Networks (CNNs) have gained prominence as formidable tools. CNNs emulate the human visual system, displaying proficiency in detecting and discerning patterns within images. Through training these models on datasets containing labelled digits, they acquire the ability to accurately identify and classify digits. Application of Digit Recognition Using Machine LearningDigit recognition has a wide range of applications across various industries. In the banking sector, it enables automated check processing, making transactions faster and more efficient. In postal services, it plays a crucial role in automating sorting processes by recognizing postal codes. Moreover, digit recognition is leveraged in the field of document analysis, where it aids in extracting information from forms, invoices, and other handwritten documents. It has also found applications in the field of healthcare, where it assists in analyzing medical records and prescription digitization. Now we will try to implement digit recognition using Machine Learning into code. Code: Importing LibrariesData PreparationData preparation is a crucial step in any machine-learning project. It involves transforming raw data into a format that is suitable for analysis and modelling. This process ensures that the data is clean, consistent, and ready to be used by machine learning algorithms. Loading the DataOutput: 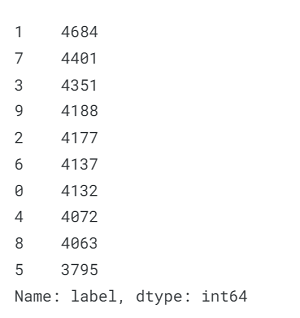
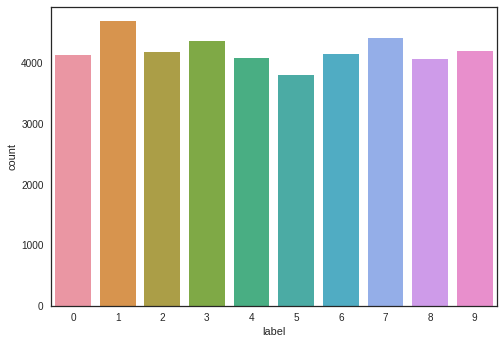
We have approximately equal frequencies for each of the 10 digits. Checking for Null and Missing ValuesNow it becomes necessary for us to perform this task of checking for null and missing values. Output: 
We examine the dataset for any corrupted images or missing values. Fortunately, there are no missing values in the dataset, allowing us to proceed confidently. NormalizationWe apply grayscale normalization to minimize the impact of variations in illumination. Additionally, Convolutional Neural Networks (CNNs) tend to converge more quickly when trained on data ranging from 0 to 1 rather than 0 to 255. ReshapeThe training images, initially represented as 1D vectors of 784 values, have been stored in a pandas DataFrame. We then reshape the data into 3D matrices of size 28x28x1. In the case of grayscale images used in the MNIST dataset, only one channel is required. However, for RGB images with three colour channels, we would reshape the 784-pixel vectors into 3D matrices of size 28x28x3 to accommodate all three channels. Label EncodingThe labels in our dataset are represented as 10-digit numbers ranging from 0 to 9. To process these labels in our machine-learning model, we need to encode them as one-hot vectors. For example, the label '2' would be encoded as [0, 0, 1, 0, 0, 0, 0, 0, 0, 0], where the '1' indicates the corresponding digit and the other positions are filled with '0's to represent the remaining digits. Splitting the DatasetWe have decided to divide the training set into two parts: a small portion (10%) will be used as the validation set to evaluate the model, and the remaining portion (90%) will be used to train the model. Since we have a total of 42,000 training images with balanced labels, a random split of the training set will not result in any labels being overrepresented in the validation set. However, it is important to note that when working with unbalanced datasets, a simple random split could lead to inaccurate evaluation during the validation process. To address this issue, you can use the "stratify=True" option in the "train_test_split" function (available in sklearn versions >=0.17) to ensure that the class distribution is maintained in both the training and validation sets. One way to gain a better understanding of an example is by visualizing the image and examining its corresponding label. By visualizing the image, we can get a visual representation of the data and observe its features, while the label provides us with information about its classification or category. This visual inspection allows us to interpret and analyze the data more effectively, leading to insights and a deeper understanding of the example at hand. Output: 
ModelWe employed the Sequential API in Keras, which allows us to add one layer at a time, starting from the input. The first layer is the convolutional (Conv2D) layer, consisting of a set of learnable filters. We opted for 32 filters in the first two Conv2D layers and 64 filters in the remaining two. Each filter applies a transformation to a portion of the image, defined by the kernel size. The kernel filter matrix is then applied to the entire image. These filters can be viewed as a way to transform the image. The CNN can extract relevant features from these transformed images, which are represented as feature maps. The next crucial layer in CNN is the pooling (MaxPool2D) layer. This layer acts as a downsampling filter by selecting the maximum value from neighbouring pixels. It helps reduce computational complexity and, to some extent, mitigates overfitting. The pooling size, determining the area pooled at each step, affects the level of downsampling. By combining convolutional and pooling layers, CNNs are capable of capturing both local and global features of the image. To prevent overfitting, we incorporated dropout regularization. This technique randomly ignores a proportion of nodes in a layer (setting their weights to zero) during training. It introduces randomness, encouraging the network to learn features in a distributed manner and improving generalization. The activation function 'relu' (rectifier) introduces non-linearity to the network, enhancing its learning capacity. The Flatten layer is used to convert the final feature maps into a 1D vector. This flattening step is necessary to utilize fully connected layers after convolutional and pooling layers. It combines all the local features identified by the preceding layers. Finally, we employed two fully connected (Dense) layers, which resemble artificial neural networks (ANN) classifiers. In the last layer (Dense(10, activation="softmax")), the network outputs a probability distribution for each class. Setting Optimizer and AnnealerOnce we have added the layers to our model, we need to configure a score function, a loss function, and an optimization algorithm. The loss function is defined to measure how accurately our model predicts the labels of the images. It calculates the error rate between the observed labels and the predicted ones. For categorical classification tasks with more than two classes, we use a specific form of loss function called "categorical_crossentropy". The optimizer is the most crucial function as it iteratively adjusts the parameters of the model, such as filter kernel values, weights, and biases of neurons, to minimize the loss. We have chosen RMSprop as our optimizer, which is highly effective. The RMSProp update is a modification of the Adagrad method that aims to reduce the aggressive, monotonically decreasing learning rate. Alternatively, we could have used a Stochastic Gradient Descent (SGD) optimizer, but it tends to be slower than RMSprop. The metric function "accuracy" is used to evaluate the performance of our model. It measures how well the model predicts the correct labels. It is important to note that the results from the metric evaluation are not used during the training of the model; they are only used for evaluation purposes. To facilitate faster convergence of the optimizer towards the global minimum of the loss function, we implemented an annealing method for the learning rate (LR). The learning rate determines the size of the steps taken by the optimizer as it navigates the landscape of the loss function. A higher learning rate results in larger steps and faster convergence. However, using a high learning rate can lead to poor sampling, and the optimizer may get stuck in a local minimum. To overcome this, we employed a decreasing learning rate during training to ensure more efficient convergence towards the global minimum of the loss function. To leverage the benefits of faster computation with a high learning rate, we dynamically reduced the learning rate every X step (epochs) based on whether it was necessary, specifically when the accuracy did not improve. We utilized the ReduceLROnPlateau function from the Keras.callbacks module, which automatically reduced the learning rate by half if the accuracy did not improve after 3 epochs. This approach helped us fine-tune the learning rate and optimize the model's performance. Data AugmentationTo address the issue of overfitting, we employed data augmentation techniques to expand our existing handwritten digit dataset. This approach involved artificially altering the training data through various transformations to replicate the variations that occur when someone writes a digit. For instance, we accounted for scenarios where the number was not centred, the scale varied (some individuals write with larger or smaller numbers), or the image was rotated. Data augmentation techniques involve modifying the training data while keeping the label the same, thereby changing the array representation. Popular augmentations include grayscaling, horizontal and vertical flips, random crops, colour jitters, translations, rotations, and more. By applying just a few of these transformations to our training data, we significantly increased the number of training examples, effectively doubling or even tripling the dataset. This augmentation process enhanced the robustness of our model, enabling it to better generalize and mitigate the risk of overfitting. Note: The improvement achieved through data augmentation is substantial. When training the model without data augmentation, we obtained an accuracy of 98.114%. However, by implementing data augmentation techniques, we were able to significantly enhance the model's performance, resulting in an impressive accuracy of 99.67%.To augment the training data, we implemented several transformations to introduce variations and increase the diversity of the dataset. Specifically, we chose the following augmentation techniques:
We made a deliberate choice not to apply vertical or horizontal flips to the images. This decision was motivated by the fact that flipping symmetrical digits, such as 6 and 9, could potentially lead to misclassification. By excluding these flips, we ensure that the model focuses on learning distinctive features of the digits without being misled by symmetrical similarities. Output: 
Evaluating the ModelTo evaluate the performance of our model, we used the validation set, which contains a separate set of images that the model has not seen during training. This allows us to assess how well the model generalizes to new and unseen data. Training and Validation CurvesOutput: 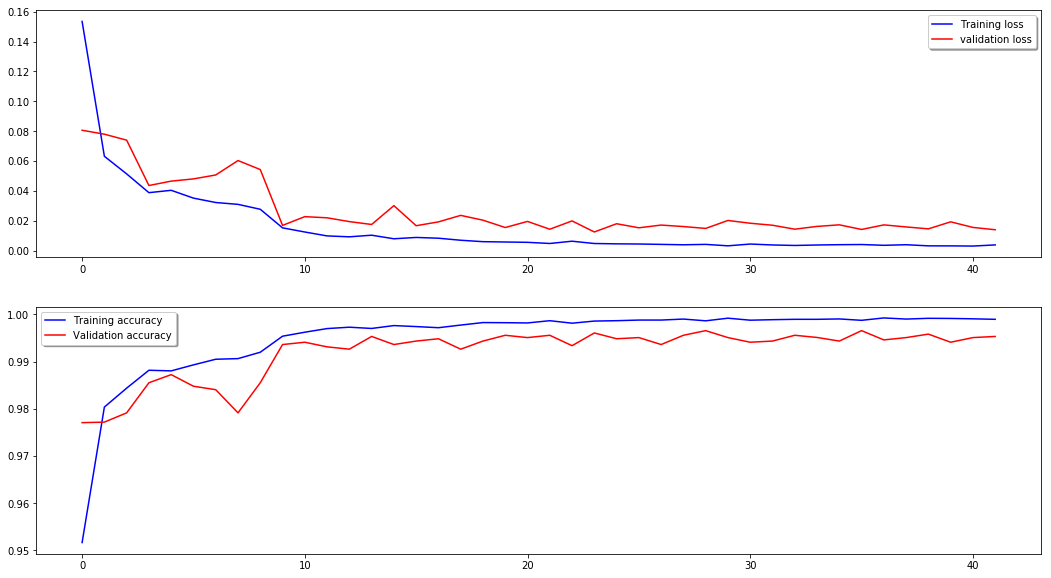
The model's performance is impressive, achieving an accuracy of nearly 99% on the validation dataset after just 2 epochs. Notably, the validation accuracy consistently surpasses the training accuracy throughout the training process. This indicates that our model is effectively generalizing and not overfitting the training set. Confusion MatrixAnalyzing the confusion matrix enables us to identify specific areas where the model may struggle or encounter challenges. This information helps us understand the model's limitations and provides guidance for potential improvements. To achieve this, we plot the confusion matrix based on the validation results, allowing us to visualize the model's performance and identify any patterns or trends in misclassifications. Output: 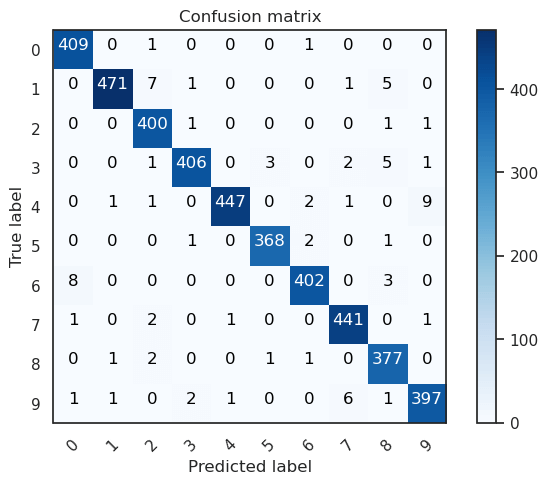
In our evaluation of the CNN model, we observe excellent performance across all digits with minimal errors, considering the size of the validation set, which consists of 4,200 images. However, we do notice a slight challenge for our CNN when classifying the digit 4, as it occasionally misclassifies it as 9. This can be attributed to the inherent difficulty in distinguishing between these two digits when their curves are smooth and visually similar. Despite this minor issue, overall, our CNN demonstrates impressive accuracy and proficiency in recognizing and classifying the various digits in the dataset. Let's examine the errors more closely. Our aim is to identify the most significant errors by examining the disparity between the probabilities of the actual values and the predicted values in the results. This will allow us to pinpoint the instances where the model's predictions deviate the most from the true values. Output: 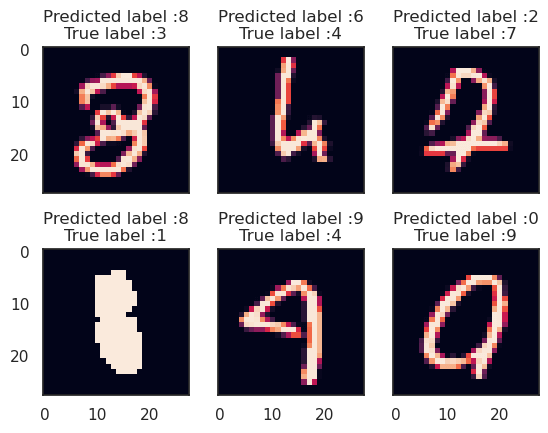
The most crucial errors are also the most intriguing. In these six cases, the model's performance is not absurd. Some of these errors could also be made by humans, particularly in the case of one instance where a 9 closely resembles a 4. The last 9 is also quite misleading, as it appears to be more like a 0, in my opinion. Challenges and Future Aspects of Digit Recognition Using Machine LearningWhile machine learning-based digit recognition has achieved remarkable success, challenges still exist. One significant challenge is the ability to handle variations in writing styles, especially when dealing with handwritten digits. Ongoing research focuses on improving model robustness and addressing these challenges. Researchers are exploring techniques such as data augmentation, where the training dataset is artificially expanded to include variations in writing styles, scale, and orientation. Furthermore, advancements in deep learning, such as the integration of recurrent neural networks, hold promise for enhancing digit recognition accuracy. ConclusionDigit recognition using machine learning has revolutionized various industries by automating and streamlining processes that involve the identification and classification of digits. With the power of convolutional neural networks and other machine learning algorithms, we have witnessed significant advancements in digit recognition accuracy. As research and technology continue to evolve, we can expect even more sophisticated models capable of handling complex variations in writing styles. Digit recognition is undoubtedly a field that will continue to thrive, making significant contributions to diverse applications and shaping the future of artificial intelligence. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








