| |

Image Processing Using Machine LearningImage processing involves manipulating and analyzing images to enhance their quality, extract features, or recognize patterns. Traditional image processing techniques rely on predefined rules and algorithms to perform specific tasks, such as edge detection, image segmentation, or object recognition. However, these techniques often face limitations when dealing with complex and diverse visual data. Machine learning, on the other hand, offers a more flexible and adaptive approach to image processing. By training algorithms on large datasets of labelled images, machine learning models can learn to recognize patterns and extract relevant features automatically. This ability to learn from data and adapt to new situations makes machine learning a powerful tool for image analysis and processing. One of the key applications of machine learning in image processing is object detection and recognition. By training models on labelled images that contain objects of interest, such as cars, people, or buildings, machine learning algorithms can learn to identify and locate these objects in new images. This capability has significant implications in fields like surveillance, where automated object detection can assist in identifying potential threats or anomalies. Another application of machine learning in image processing is image classification. By training models on labelled images from different categories, such as animals, landscapes, or medical images, machine learning algorithms can learn to classify new images into the appropriate categories. This capability is particularly useful in areas like healthcare, where accurate and automated image classification can aid in disease diagnosis, medical imaging analysis, and treatment planning. Now for the sake of understanding, we will try to implement it. Here we will do image processing for nucleus detection. Code: Importing LibrariesReading the ImageOutput: 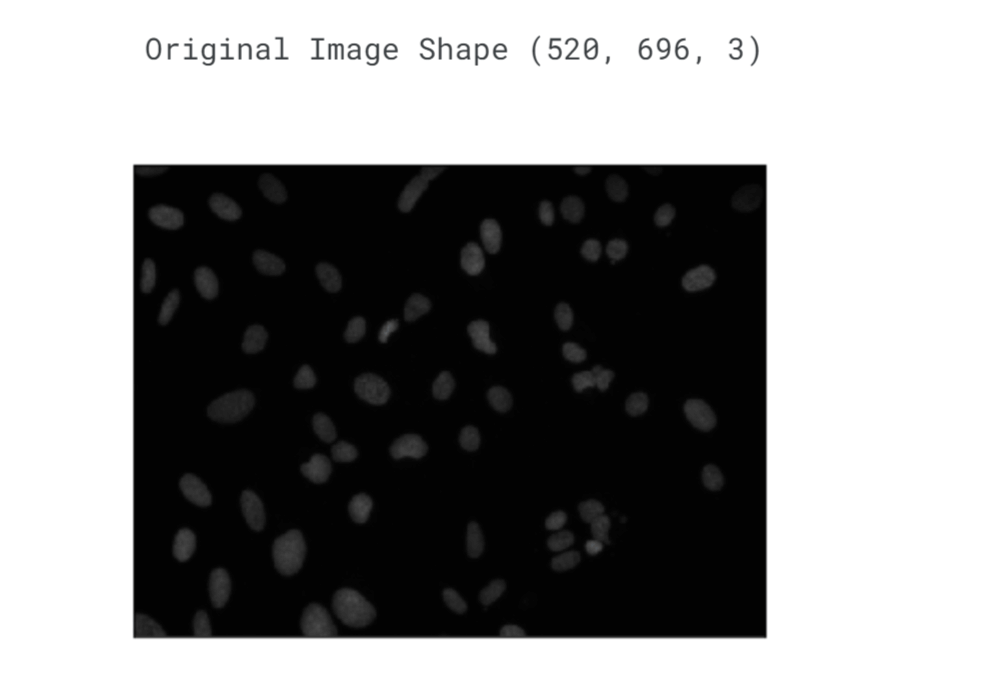
Output: 
The image is being interpreted in the BGR (Blue-Green-Red) colourspace, which means that each pixel in the image is represented by three values: the intensity of blue, the intensity of green, and the intensity of red. This colourspace is the default choice when reading images in OpenCV. In the BGR/RGB colourspace, specific combinations of red, green, and blue are used to create a wide range of colours. These three primary colours, when mixed together, can generate any chromaticity within the triangle formed by their respective values. In simpler terms, you can think of an RGB colour as encompassing all the possible colours that can be produced by mixing three coloured lights: red, green, and blue. By adjusting the intensity of these primary colours, we can create and display a vast array of different colours in an image. Basic StepsHere we will implement classical image techniques, which will hopefully serve as a useful primer. Those classical image techniques are:
Dealing with ColorOutput: 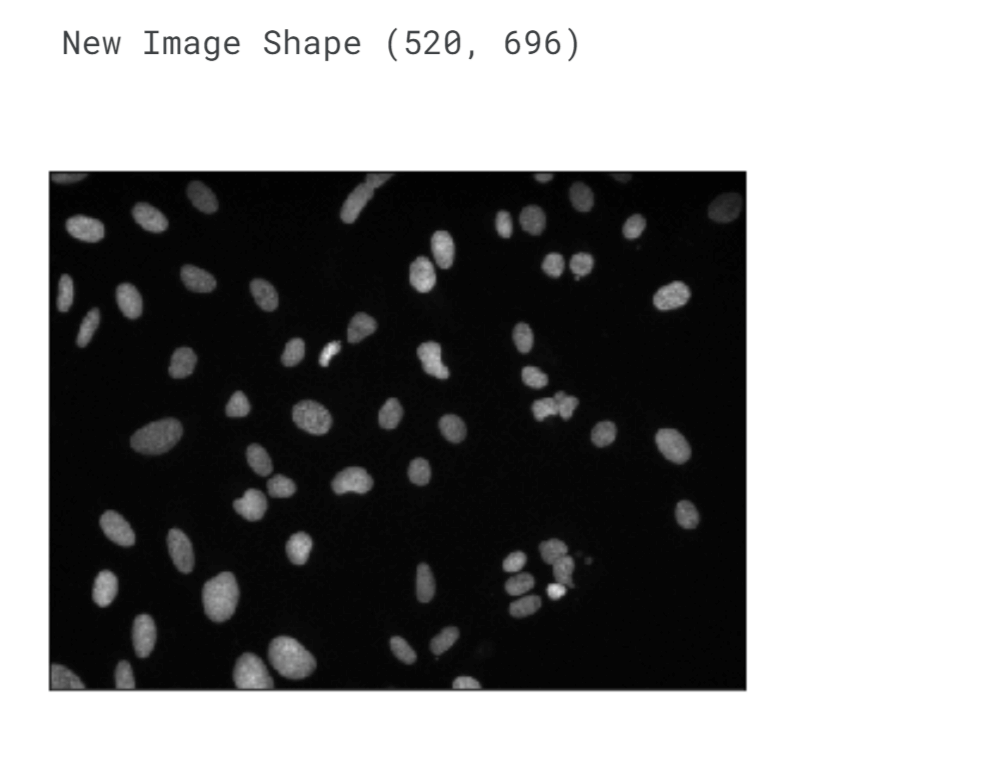
When we converted the image from the BGR colourspace to grayscale, we actually reduced one dimension. This occurred because grayscale represents a range of monochromatic shades that go from black to white. In other words, a grayscale image only contains various shades of grey and lacks any colour information (it primarily consists of black and white). The transformation from BGR to grayscale eliminates all colour data, retaining only the luminance of each pixel. In digital images, colours are displayed using a combination of red, green, and blue (RGB) values. Therefore, each pixel has three separate luminance values corresponding to these colour channels. However, when removing colour and creating a grayscale image, these three values need to be merged into a single value. Luminance can also be described as brightness or intensity, which is measured on a scale ranging from black (zero intensity) to white (full intensity). By reducing the image to grayscale, we simplify its representation to focus solely on the variations in brightness across the image, disregarding the specific colours present. Output: 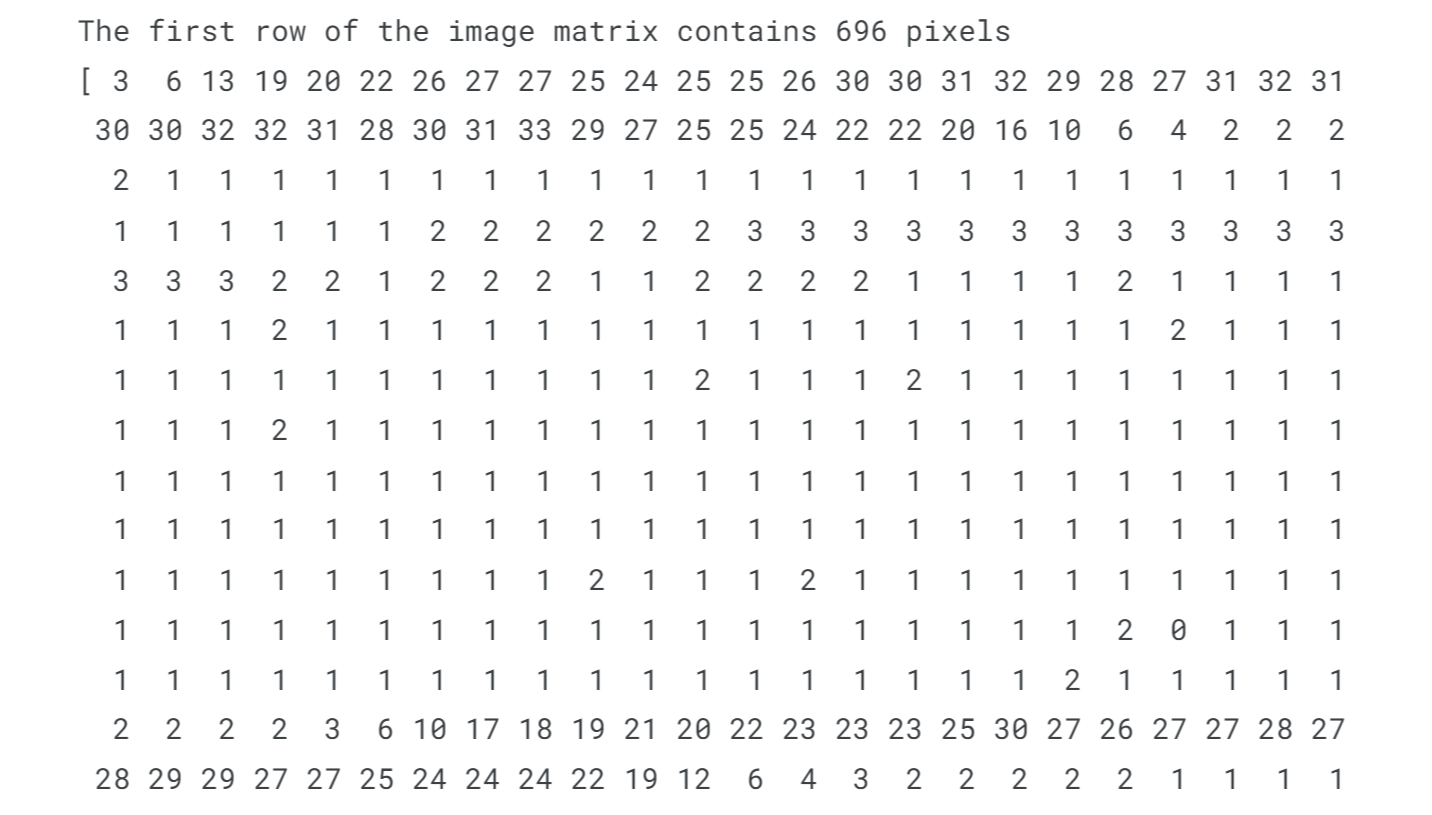

When displaying one entire row of the image matrix in grayscale, you are essentially showing the luminance or intensity values of each pixel along that row. Each pixel's luminance value represents its brightness level, ranging from black (lowest intensity) to white (highest intensity). By visualizing a row of the image matrix in grayscale, you can observe the varying intensities of the pixels within that row. This provides insight into the brightness patterns and transitions occurring horizontally across the image. It allows you to focus on the luminance variations without the distraction of colour information, highlighting the grayscale image's tonal values and emphasizing the contrast and shading present in that particular row. Thus this displays one entire row of the image matrix with the corresponding luminance or intensities of every pixel. Removing BackgroundOutput: 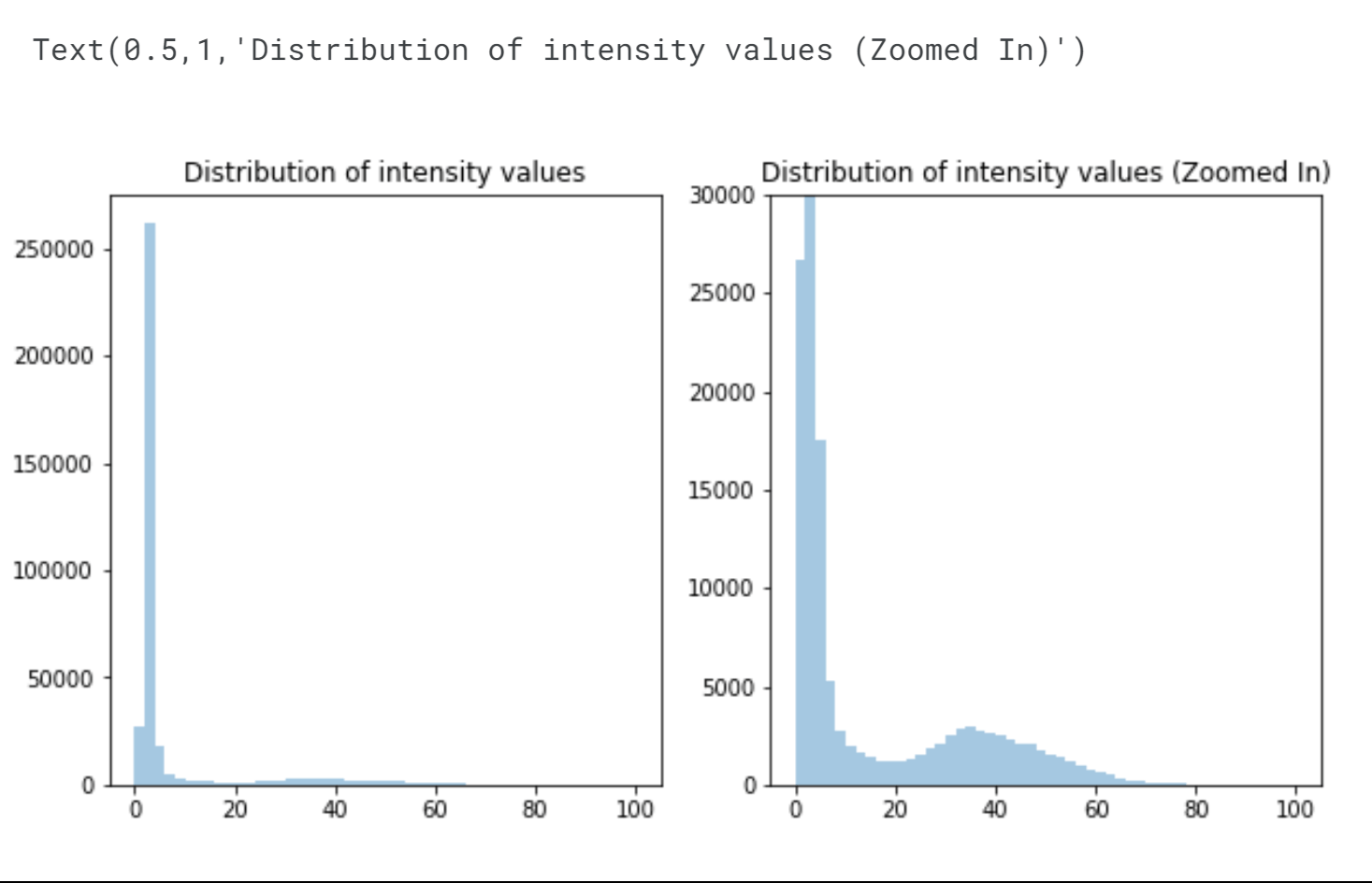
We can observe two prominent peaks in the intensity distribution. The high count of pixels with intensity values around 0 is expected because the nuclei occupy a smaller portion of the image compared to the predominantly black background. Our task here is to separate the nuclei from the background. Based on the descriptive statistics, we anticipate an optimal separation value of approximately 20. However, instead of relying solely on such statistics, we should adopt a more formal approach like Otsu's method. Otsu's method, named after Nobuyuki Otsu, is a technique used for automatic clustering-based image thresholding. It aims to convert a grayscale image into a binary image by identifying an optimal threshold. The algorithm assumes that the image consists of two classes of pixels, namely foreground pixels (nuclei) and background pixels. It calculates the threshold that minimizes the combined spread or intra-class variance of the two classes, thereby maximizing their inter-class variance. In simpler terms, Otsu's method determines the best threshold to separate the nuclei from the background based on the histogram distribution of pixel intensities. Output: 
We will encode the pixels based on their intensity values using the np.where function, we can create a mask that sets all pixels with an intensity value greater than the threshold value to 1, and all other pixels to 0. The resulting mask will indicate the separation between the nuclei (encoded as 1) and the background (encoded as 0). Deriving Mask for each objectOutput: 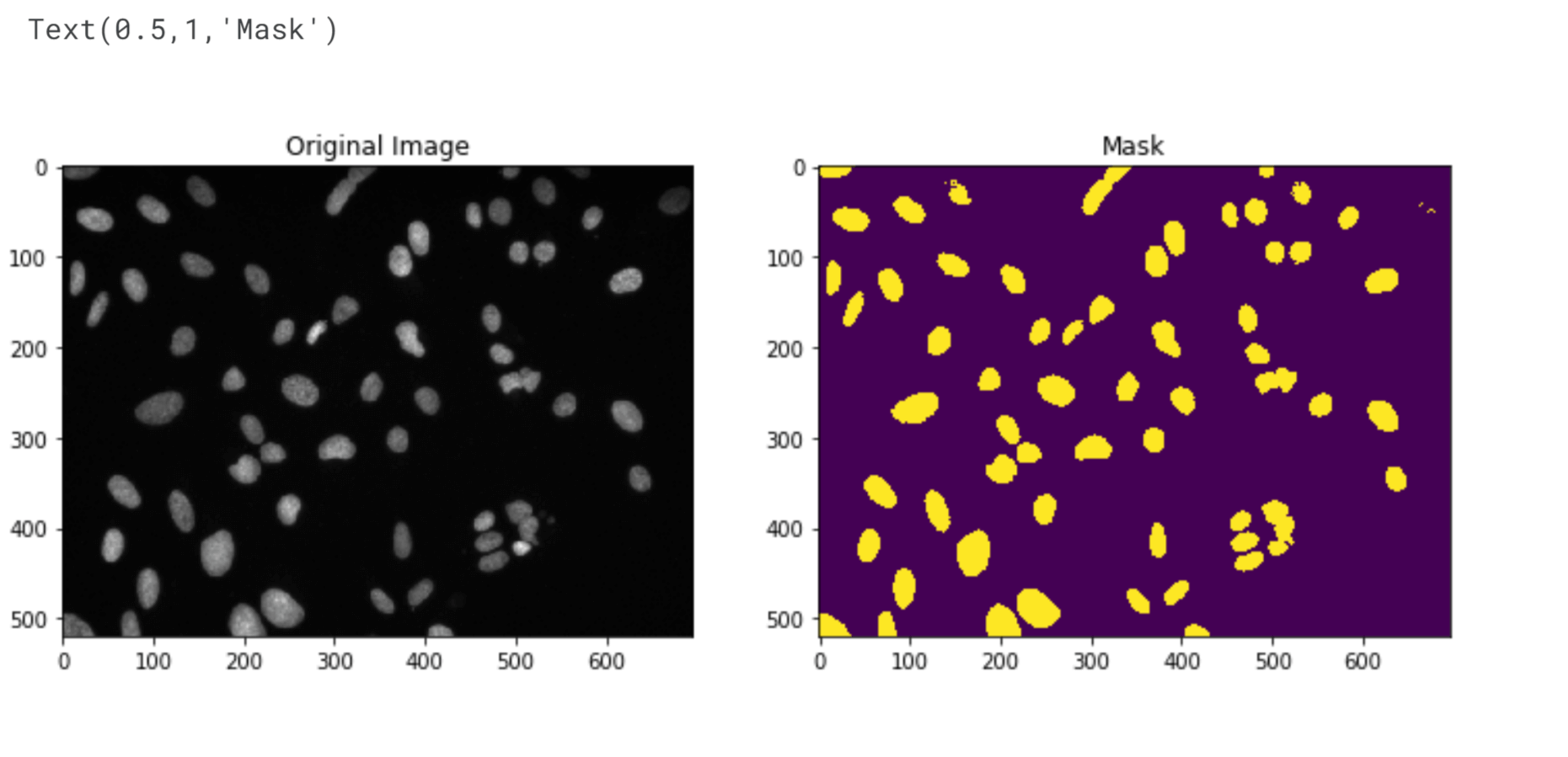
The current mask generated has some limitations. It failed to accurately detect all the nuclei, especially the two in the top-right corner. Additionally, the three nuclei around the (500, 400) mark have merged into a single cluster. The issue arises because the darker nuclei have intensity values lower than the threshold. To improve the detection of individual nuclei, we need to use more advanced techniques. These techniques involve additional image processing steps such as morphological operations or adaptive thresholding. By applying these methods, we can enhance the separation and accurately identify each nucleus. Output: 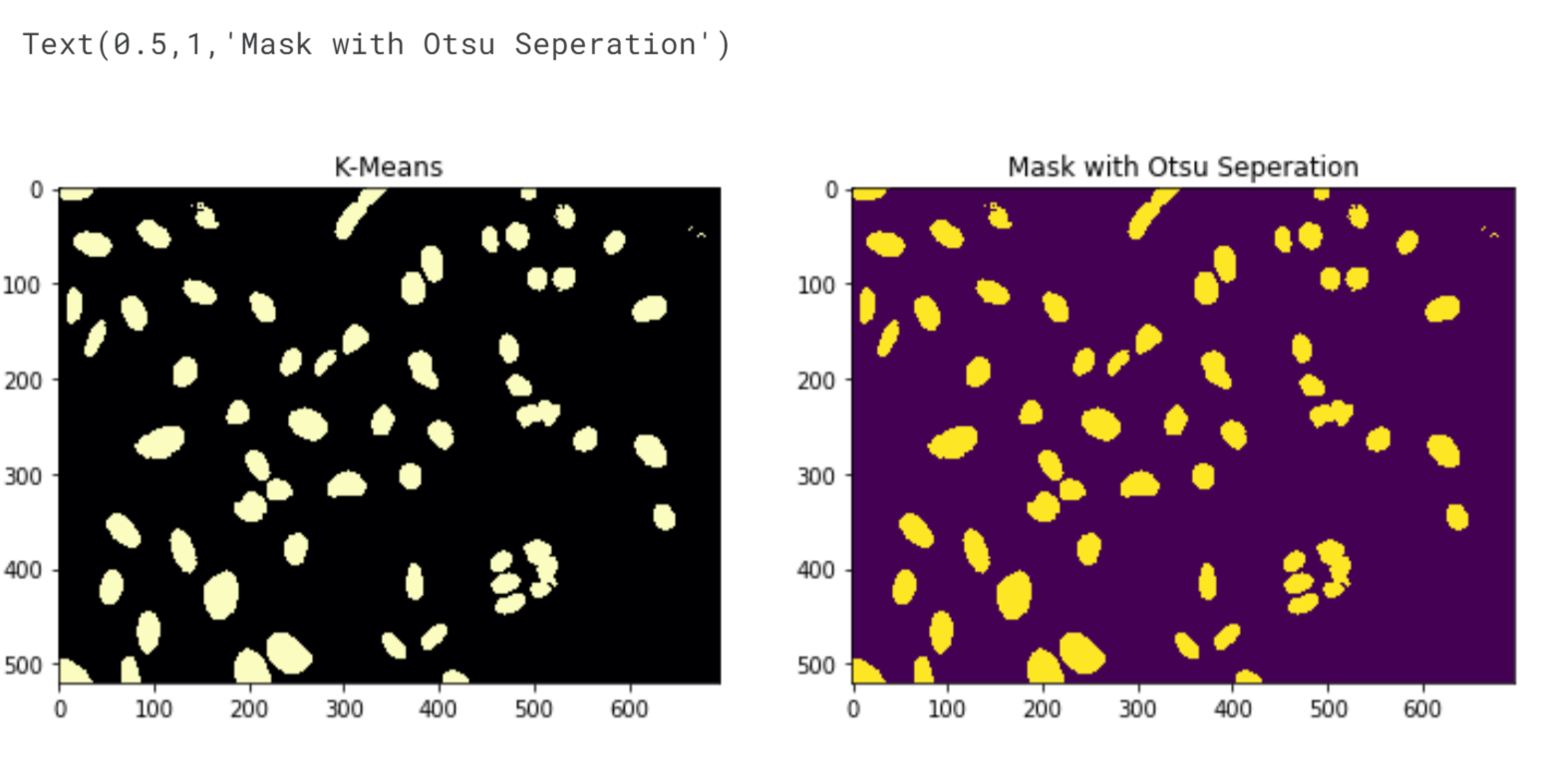
To determine if there is any difference between the labels obtained from Otsu's method and K-Means clustering at a pixel level, we can compare the labels and calculate the percentage of matching labels. If the resulting percentage is 1, it means there is no difference at all. Output: 
There is no difference at all. Object IdentificationTo get a count of the total number of nuclei, we can use the ndimage.label function, which labels features (pixels) in an array based on their interconnectedness. So, for example, if [1 1 1 0 0 1 1] was our row vector, using ndimage.label on this would give us [1 1 1 0 0 2 2] signifying the fact that there are 2 distinct objects in the row vector. The function returns the labelled array and the number of distinct objects it found in the array. Output: 
Output: 
Output: 
It is possible that there are more nuclei present in the image than we have currently identified. Some nuclei have merged together, causing them to be counted as a single object in our mask. Additionally, our mask may not have successfully detected all the nuclei, particularly those located in the top right corner. Interestingly, in the top right corner, there are two separate spots that have been labelled as distinct objects, even though they are part of the same group or cluster.
By applying the Sobel filter or Canny edge detector, we can detect the edges separating the clustered nuclei. This allows us to distinguish individual nuclei and separate them based on the detected edges. The resulting segmentation will enable more accurate identification and delineation of each nucleus, even when they are in close proximity to one another. To obtain separate masks for each nucleus, we can utilize the "stage1_train_labels.csv.zip" file, which contains the image IDs and the Run Length Encoded (RLE) vectors corresponding to each nucleus's mask. The RLE vector represents the locations of the pixels within the mask. Output: 
The 1s represent 1 such object (nucleus) in the entire picture. Run Length EncodingRLE or Run Length Encoding converts a matrix into a vector and returns the position/starting point of the first pixel from where we observe an object (identified by a 1) and gives us a count of how many pixels from that pixel we see the series of 1s. In the ndimage.label function example of [1 1 1 0 0 1 1], running RLE would give us 1 3 6 2, which means 3 pixels from the zeroth pixel (inclusive) and 2 pixels from the 5th pixel we see a series of 1s. Output: 
Merging Everything TogetherOutput: 
Edge DetectionEdge detection is a fundamental concept in image processing that involves identifying boundaries or edges between different objects or regions within an image. It plays a vital role in various fields, such as computer vision, robotics, and medical imaging. Traditional edge detection algorithms, like the Sobel operator and the Canny edge detector, use mathematical operations to locate areas of rapid-intensity transitions. Here, we will use the Sobel Filter first. Output: 
Output: 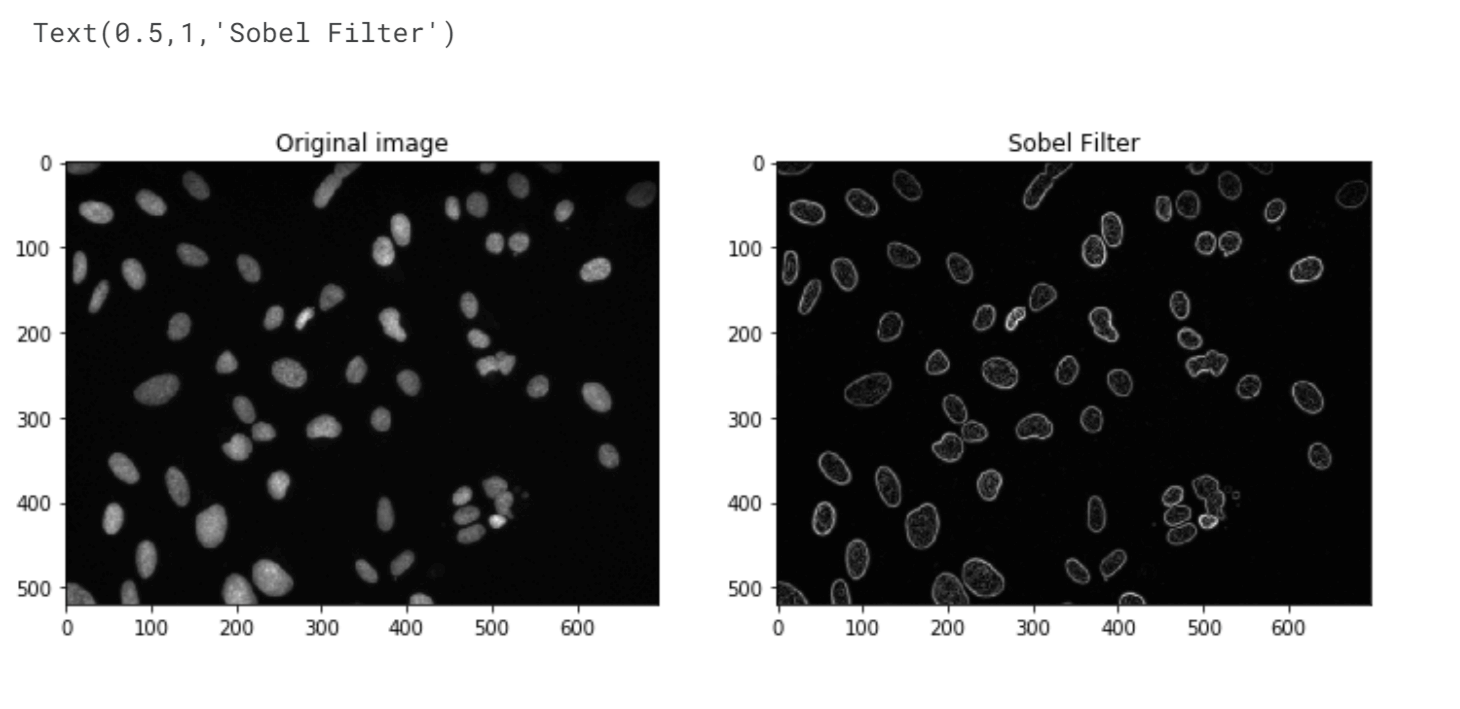
The Sobel filter has performed better than Otsu/K-Means in identifying separate objects in the image. It successfully detected the two nuclei in the top right corner and the two small nuclei near the (530,410) area. However, there is still room for improvement as it merged two out of the three overlapping nuclei in that region instead of recognizing them as separate objects. Output: 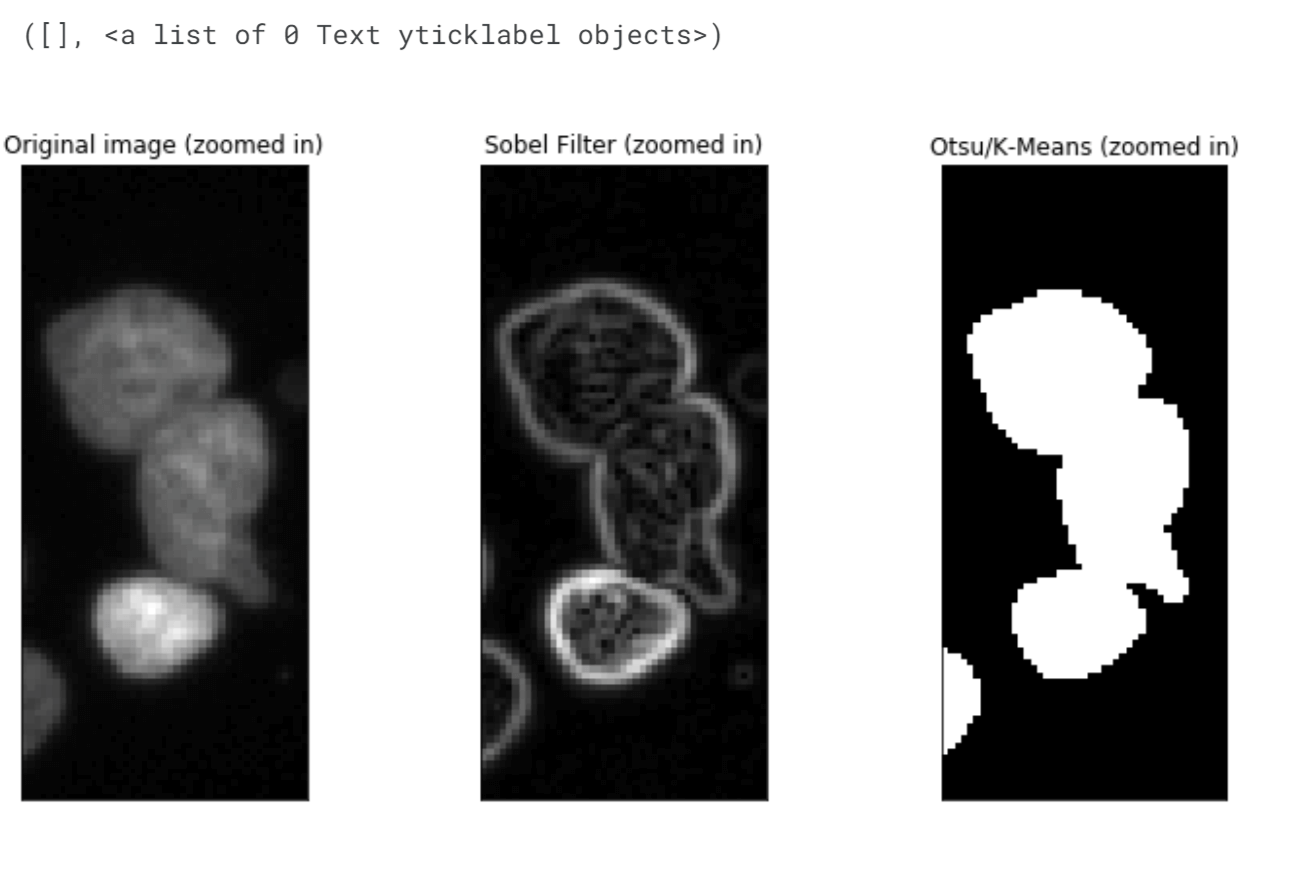
We will now employ a Canny edge detector which is a smarter Sobel Filter. Output: 
The Canny Edge Detector has detected gradients within the nuclei, which may seem excessive. However, if we focus on extracting only the external contours and use them to create masks, we can capture the regions of interest more accurately. It's important to note that similar issues to those encountered with the Sobel filter persist here. Nevertheless, the Canny Edge Detector generates a modified image matrix consisting of binary values (0 and 255), simplifying the representation of the detected edges. Output: 
Output: 
The Canny Edge Detector has successfully detected most of the nuclei, but complete masks for each nucleus are not obtained. Adjusting the minval and maxval parameters in the cv2.Canny() function can potentially improve the results, taking into account the specific characteristics of the image being processed. The canny_mask matrix output is compatible with the ndimage.labels function, which is used to identify connected components. However, it is crucial to generate complete masks for each nucleus to ensure that we do not detect more objects than are actually present in the image. Output: 
Output: 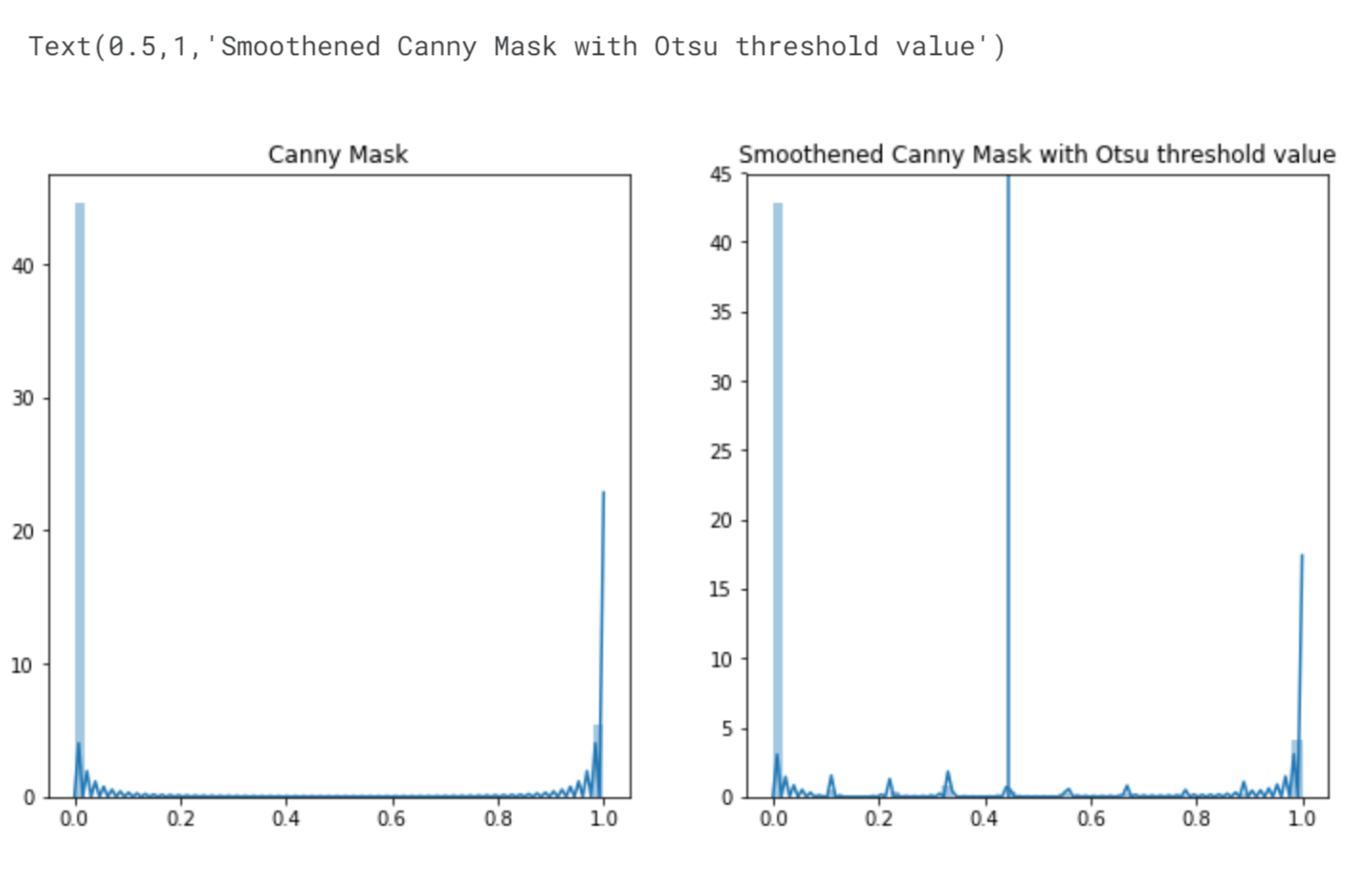
The number of pixels with intensity values equal to 1 has decreased. This reduction is attributed to the smoothing process. We performed convolution on the canny mask using a local filter, specifically a 3x3 matrix where all values are set to 1/9. This operation replaces the intensity values of the pixels with the average intensity value of their neighbouring pixels. If a pixel is surrounded by neighbouring pixels with intensity values of 1, its intensity value remains as 1 (since 1/9 multiplied by 9 equals 1). However, the pixels located at the edges of objects and in problematic areas experience a decrease in their intensity values. Output: 
Output: 
Output: 
Output: 
Overall, the current results are satisfactory. Although there are still instances where nuclei are clustered together, the important point is that we have successfully identified all the nuclei in the original image. However, before proceeding further and potentially overfitting to a specific image, it is crucial to explore different values for the MinVal and MaxVal parameters in the cv2.Canny() function to determine their effectiveness on other images. This allows us to establish a more robust approach that can generalize well across various scenarios. Output: 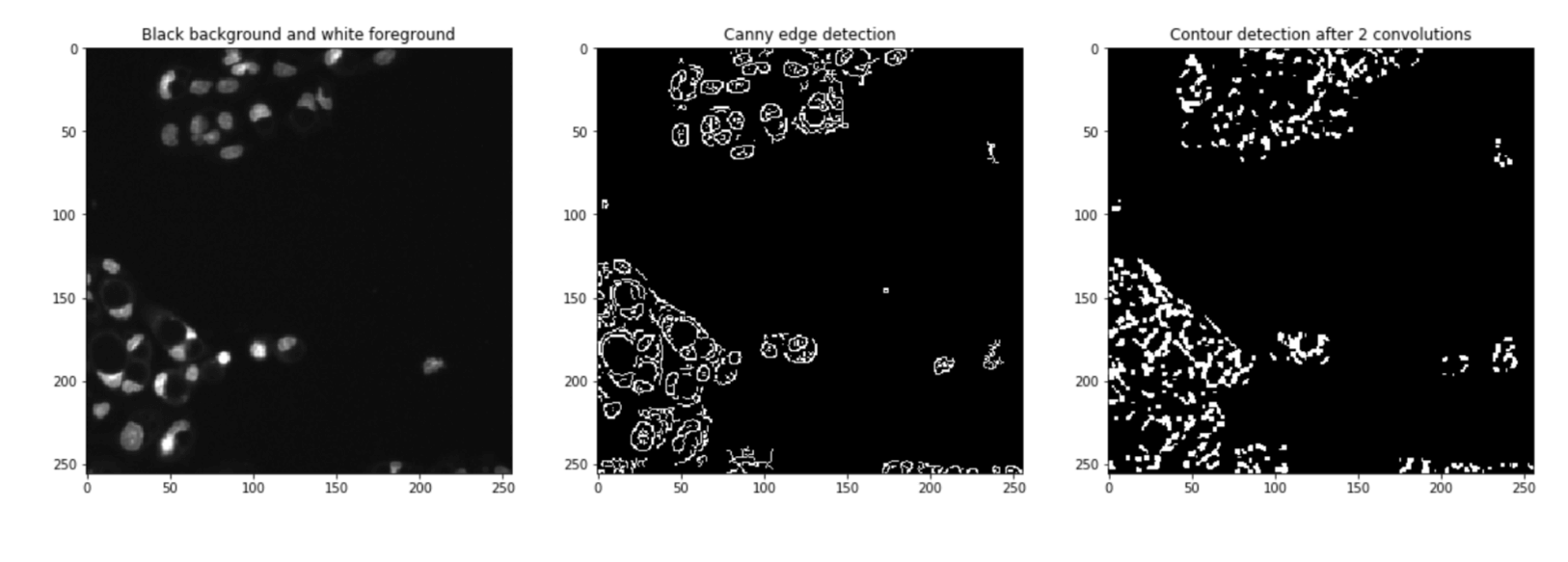
Output: 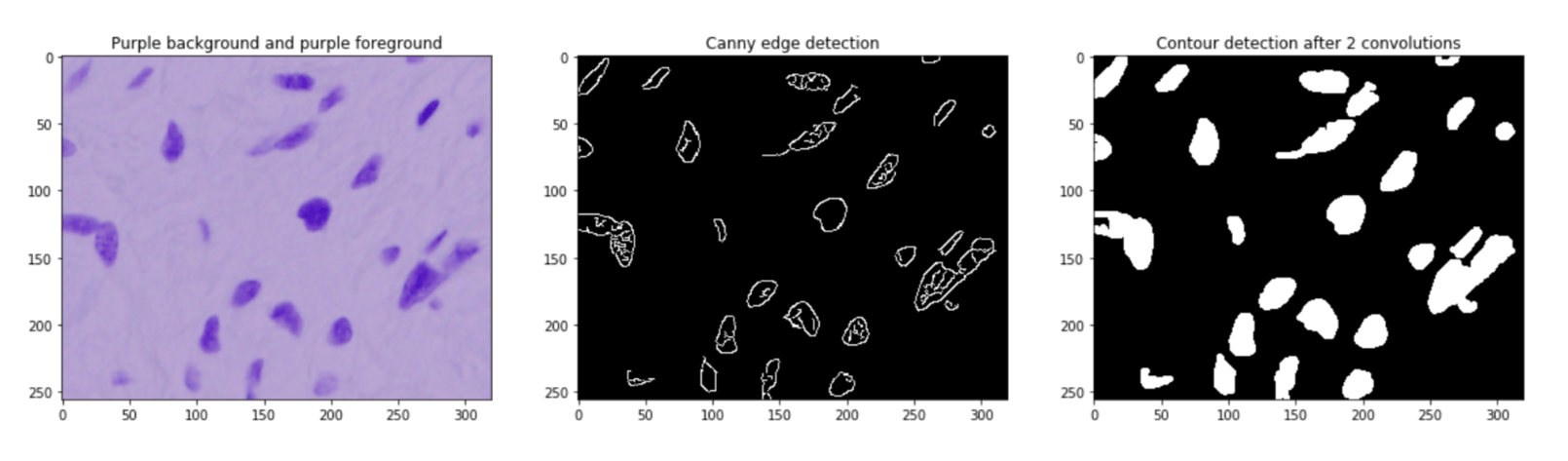
Output: 
Output: 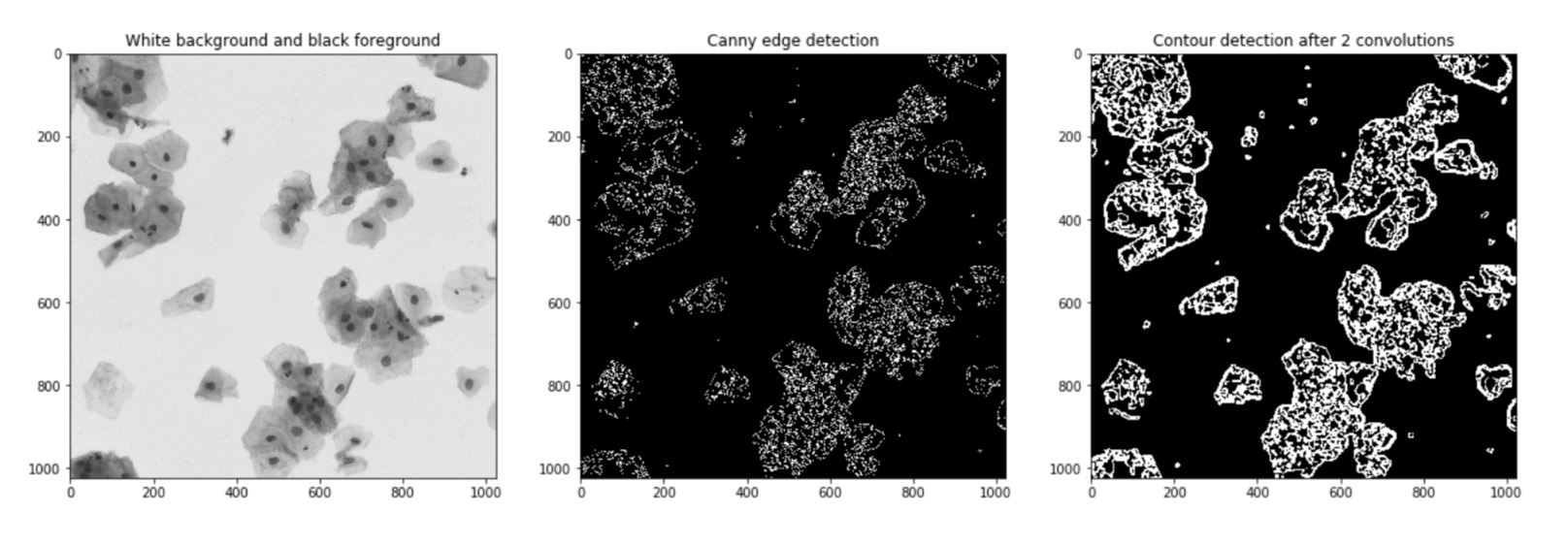
Output: 
It is not hard to see that the same parameters as on the black background and white foreground images will fail miserably on other kinds of images. Pixel ClassifierWe'll try to build a pixel classifier that classifies pixels as 0 or 255 depending on the grayscale values of the pixel and its neighbours. Output: 
We will use the bounding boxes of nuclei found in the mask to localize and classify nuclei in the original image. By considering grayscale values and corresponding labels in the combined mask, we assign labels to pixels within the bounding boxes. While some nuclei may be clustered together or result in false positives, our focus is on regions of interest. The pixel classifier relies on grayscale values and neighbouring pixel information to make accurate classifications. The goal is to ensure that all regions with nuclei are captured, avoiding false negatives while allowing the classifier to assign 0 values to non-nucleus regions. The performance of the pixel classifier depends on the defined features and their ability to accurately classify the pixels. Output: 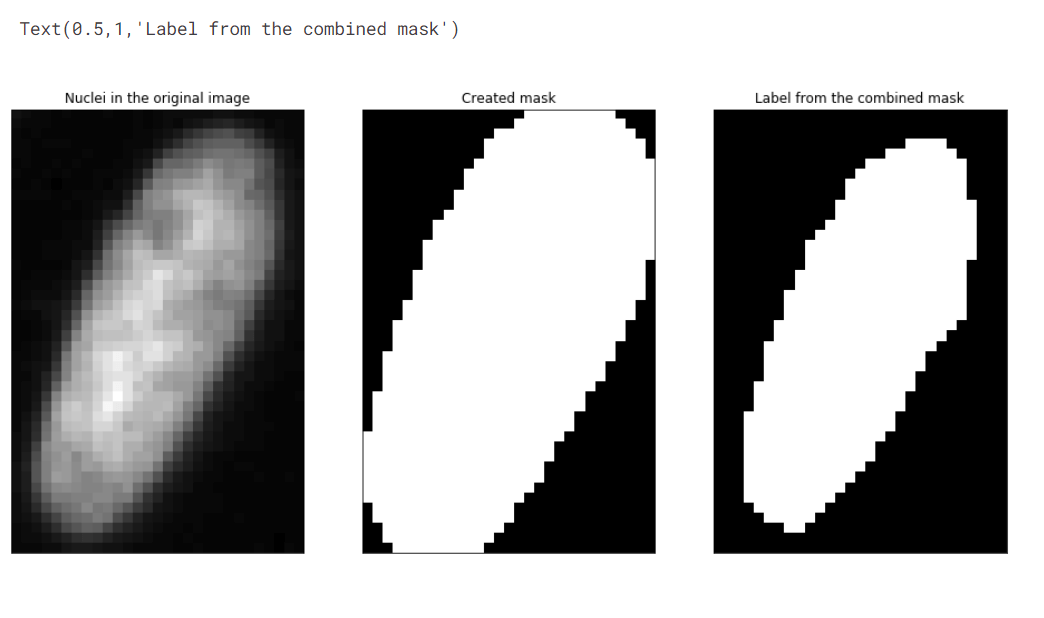
Output: 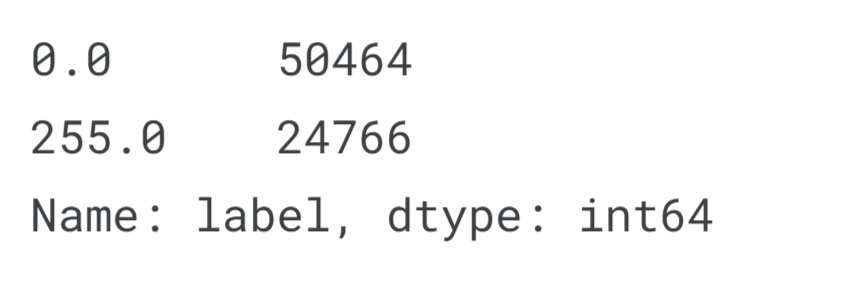
The class distribution appears to be skewed towards 0, which is unexpected when considering only pixels within the bounding boxes. This could be due to the bounding boxes encompassing larger regions than individual nuclei. Output: 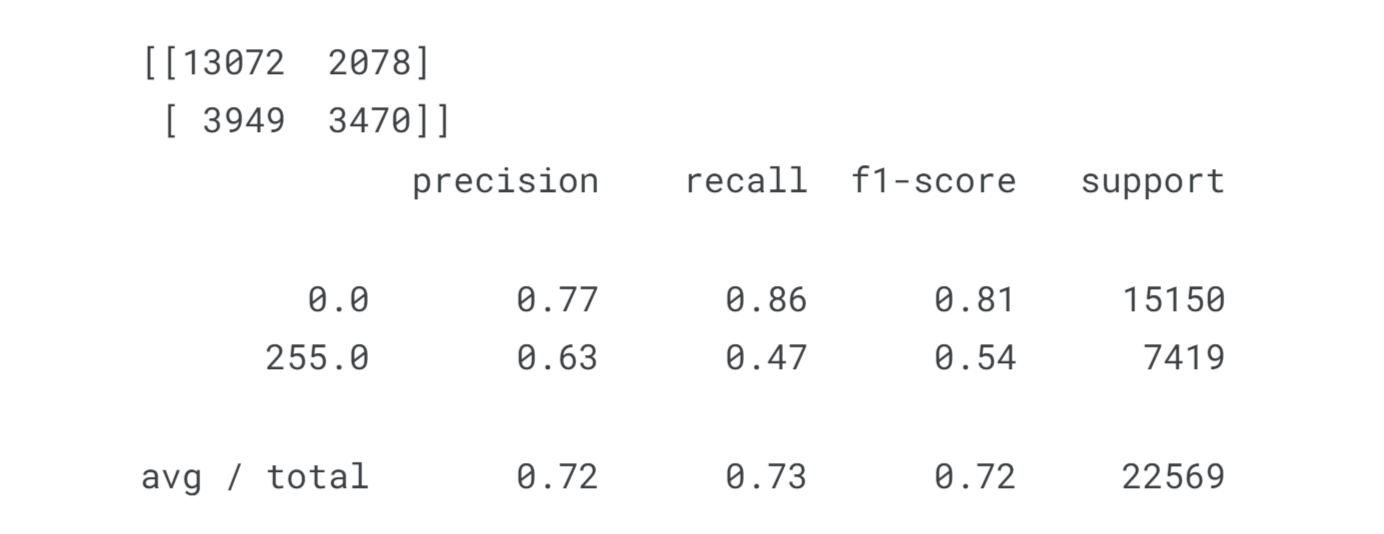
Output: 
The performance of the pixel classifier depends on the defined features. It's important to note that we have trained and tested the classifier on the same image, which could lead to overfitting. To improve performance, we can consider training the classifier on pixels within bounding boxes from all training images. Additionally, using a 5x5 window and incorporating features such as the distance between the pixel and the nucleus centre or the relative density of white pixels (255 or 1s) within the defined window on the canny mask could enhance our results. ConclusionThe combination of image processing and machine learning opens up exciting possibilities in various fields. By leveraging the power of machine learning algorithms, we can extract valuable information from visual data, automate image analysis tasks, and enhance decision-making processes. As researchers continue to innovate and refine machine learning techniques in image processing, we can expect further advancements that will transform how we interact with and derive insights from visual data.
Next TopicMachine Learning in Banking
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








