| |

Dog Breed Classification using Transfer LearningIn this tutorial, we will learn how to classify between various dog breeds using transfer learning in Python. What is CNN?A Convolutional Brain Organization (CNN) is a kind of profound learning calculation that is especially appropriate for picture acknowledgment and handling errands. It is comprised of various layers, including convolutional layers, pooling layers, and completely associated layers. The convolutional layers are the vital part of a CNN, where channels are applied to the information picture to extricate highlights like edges, surfaces, and shapes. The result of the convolutional layers is then gone through pooling layers, which are utilized to down-example the component maps, decreasing the spatial aspects while holding the main data. The result of the pooling layers is then gone through at least one completely associated layers, which are utilized to make a forecast or characterize the picture. CNNs are prepared utilizing a huge dataset of marked pictures, where the organization figures out how to perceive examples and elements that are related with explicit items or classes. Once prepared, a CNN can be utilized to group new pictures, or concentrate highlights for use in different applications like item recognition or picture division. CNNs have accomplished cutting edge execution on an extensive variety of picture acknowledgment undertakings, including object order, object location, and picture division. They are generally utilized in PC vision, picture handling, and other related fields, and have been applied to many applications, including self-driving vehicles, clinical imaging, and security frameworks.
Convolutional Neural Network Design:
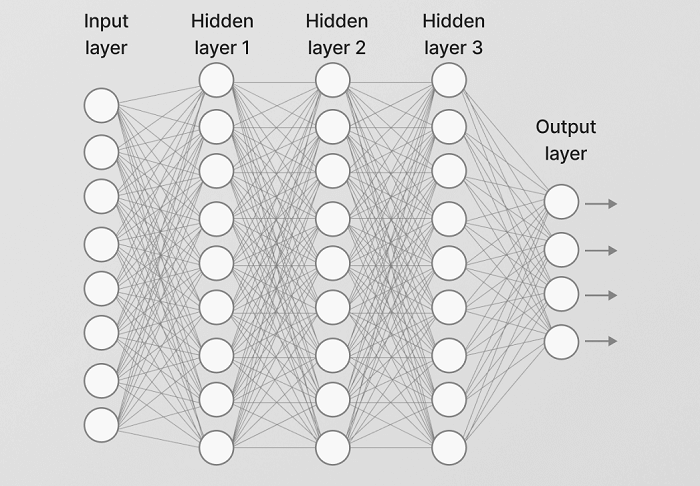
How does CNN work:A CNN can have various layers, every one of which figures out how to recognize the various elements of an info picture. A channel or part is applied to each picture to create a result that improves and more nitty gritty after each layer. In the lower layers, the channels can begin as straightforward elements. At each progressive layer, the channels expansion in intricacy to check and recognize highlights that extraordinarily address the information object. Accordingly, the result of each convolved picture - - the to some degree perceived picture after each layer - - turns into the contribution for the following layer. In the last layer, which is a FC layer, the CNN perceives the picture or the article it addresses. With convolution, the information picture goes through a bunch of these channels. As each channel actuates specific elements from the picture, it takes care of its responsibilities and gives its result to the channel in the following layer. Each layer figures out how to recognize various elements and the activities turn out to be rehashed for handfuls, hundreds or even a large number of layers. At long last, all the picture information advancing through the CNN's numerous layers permit the CNN to recognize the whole article. For picture acknowledgment, picture grouping and PC vision (CV) applications, CNNs are especially helpful on the grounds that they give profoundly exact outcomes, particularly when a great deal of information is involved. Transfer Learning: what is M, MS, ms????Transfer learning for AI is when components of a pre-prepared m are reused in another AI m. In the event that the two ms are created to perform comparable undertakings, summed up information can be divided among them. This way to deal with AI improvement diminishes the assets and measure of named information expected to prepare new ms. It is turning into a significant piece of the development of AI and is progressively utilized as a strategy inside the improvement cycle. AI is turning into a necessary piece of the advanced world. AI calculations are being utilized to follow through with complex responsibilities in a scope of businesses. Ms remembers refining showcasing lobbies for a superior return for speculation, further developing organization effectiveness, and driving the development of discourse acknowledgment programming. Transfer learning will assume a significant part in the proceeded with advancement of these ms. There is a scope of various sorts of AI, yet one of the most well-known processes is directed AI. This sort of AI utilizes marked preparing information to prepare ms. It takes ability to accurately mark datasets, and the most common way of preparing machines is in many cases asset concentrated and tedious. Transfer learning for AI is in many cases utilized while the preparation of a framework to tackle another undertaking would take an immense measure of assets. The cycle takes important pieces of a current AI m and applies it to tackle a new however comparable issue. A critical piece of Transfer learning is speculation. This implies that main information that can be involved by one more m in various situations or conditions is Transferred. Rather than ms being unbendingly attached to a preparation dataset, ms utilized in Transfer learning will be more summed up. Ms created in this manner can be used in changing circumstances and with various datasets. A m is the utilization of Transfer learning with the categorisation of pictures. An AI m can be prepared with named information to distinguish and classify the subject of pictures. The m can then be adjusted and re-used to recognize one more unambiguous subject inside a bunch of pictures through Transfer learning. The overall components of the m will remain something similar, saving assets. This could be the pieces of the m that recognizes the edge of an article in a picture. The exchange of this information saves retraining another m to accomplish a similar outcome. Transfer learning is for the most part utilized:
Make it short not more than 2 paragraphs Explain about libraries you will use How to predict the bread of the dog:In this tutorial we are going to learn about how to predict the dog bread using the CNN and Transfer Learning. In this tutorial we are going to follow the below steps: Stage 0: Import Datasets Stage 1: Distinguish People Stage 2: Distinguish Dogs Stage 3: Make a CNN to Order Dog Varieties (Without any preparation) Stage 4: Utilize a CNN to Characterize Dog Varieties (utilizing Transfer Learning) Stage 5: Make a CNN to Order Dog Varieties (utilizing Transfer Learning) Stage 6: Compose your Algorithm Stage 7: Test Your Algorithm Stage 0: Import DatasetsWe import the dataset of canine pictures for additional displaying. We populate a couple of factors by utilizing the l_files capability from the scikit-learn library. Import dog information:
Import human data Stage 1: Distinguish PeopleWe utilize OpenCV's execution of Haar highlight based overflow classifiers to distinguish human countenances in pictures. OpenCV gives numerous pre-prepared face finders, put away as XML documents on github. We have downloaded one of these locators and put away it in the haarcascades catalog. Prior to utilizing any of the face identifiers, it is standard methodology to change the pictures over completely to grayscale. The detect Multi Scale capability executes the classifier put away in f_cascade and takes the grayscale picture as a boundary. In the above code, faces is a NumPy cluster of identified faces, where each column compares to a distinguished face. Each identified face is a 1D exhibit with four sections that indicates the jumping box of the distinguished face. The initial two passages in the cluster (separated in the above code as x and y) determine the flat and vertical places of the upper left corner of the jumping box. The last two sections in the exhibit (separated here as w and h) determine the width and level of the container. Writing a Code for Human Face DetectorStage 2: Distinguish DogsIn this segment, we utilize a pre-prepared ResNet-50 m to identify canines in pictures. Our most memorable line of code downloads the ResNet-50 m, alongside loads that have been prepared on ImageNet, an exceptionally enormous, extremely famous dataset utilized for picture characterization and other vision undertakings. ImageNet contains more than 10 million URLs, each connecting to a picture containing an item from one of 1000 classes. Given a picture, this pre-prepared ResNet-50 m returns an expectation (got from the accessible classifications in ImageNet) for the item that is contained in the picture. Pre-process the InformationWhile utilizing TensorFlow as backend, Keras CNNs require a 4D exhibit (which we'll likewise allude to as a 4D tensor) as contribution, with shape where nb_samples compares to the complete number of pictures (or tests), and lines, sections, and channels relate to the quantity of columns, segments, and channels for each picture, separately. The path_to_tensor capability underneath takes a string-esteemed record way to a variety picture as info and returns a 4D tensor reasonable for providing to a Keras CNN. The capability first loads the picture and resizes it to a square picture that is pixels. Then, the picture is switched over completely to a cluster, which is then resized to a 4D tensor. For this situation, since we are working with variety pictures, each picture has three channels. Similarly, since we are handling a solitary picture (or test), the returned tensor will constantly have shape The paths_to_tensor capability takes a NumPy cluster of string-esteemed picture ways as info and returns a 4D tensor with shape. Here, nb_samples is the quantity of tests, or number of pictures, in the provided exhibit of picture ways. It is ideal to consider nb_samples as the quantity of 3D tensors (where every 3D tensor relates to an alternate picture) in your dataset! Making Predictions with ResNet-50:Preparing the 4D tensor for ResNet-50, and for some other pre-prepared m in Keras, requires some extra handling. In the first place, the RGB picture is changed over completely to BGR by reordering the channels. All pre-prepared ms have the extra standardization step that the mean pixel (communicated in RGB as and determined from all pixels in all pictures in ImageNet) should be deducted from each pixel in each picture. This is carried out in the imported capability p_input. Assuming you are interested, you can really look at the code for p_input. Since we have a method for designing our picture for providing to ResNet-50, we are presently prepared to utilize the m to extricate the expectations. This is achieved with the foresee strategy, which returns a array whose
By taking the argmax of the anticipated likelihood vector, we get a whole number comparing to the m's anticipated article class, which we can relate to an item classification using this word reference. Compose a Dog Detector:While taking a gander at the word reference, you will see that the classifications comparing to canines show up in a continuous grouping and relate to word reference keys 151-268, comprehensive, to incorporate all classes from 'Chihuahua' to 'Mexican smooth'. In this way, to verify whether a picture is anticipated to contain a canine by the pre-prepared ResNet-50 m, we want possibly check in the event that the ResNet50_predict_labels capability above returns a worth somewhere in the range of 151 and 268 (comprehensive). We utilize these plans to finish the dog_detector capability underneath, which returns Valid in the event that a canine is identified in a picture (and False if not). Stage 3: Make a CNN to classify Dog Varieties (Without any preparation)Since we have capabilities for recognizing people and canines in pictures, we really want a method for foreseeing breed from pictures. In this step, you will make a CNN that groups canine varieties. You should make your CNN without any preparation (thus, you cannot utilize Transferadvancing yet!), and you should achieve a test precision of no less than 1%. In Sync 5 of this journal, you will have the potential chance to utilize Transferfiguring out how to make a CNN that accomplishes significantly further developed precision. Be cautious with adding an excessive number of teachable layers! More boundaries implies longer preparation, and that implies you are bound to require a GPU to speed up the preparation interaction. Fortunately, Keras gives a helpful gauge of the time that every age is probably going to take; you can extrapolate this gauge to sort out what amount of time it will require for your calculation to prepare. We notice that the errand of relegating breed to canines from pictures is viewed as particularly testing. To see the reason why, consider that even a human would have extraordinary trouble in recognizing a Brittany and a Welsh Springer Spaniel. 
It is easy to find other canine variety matches with negligible between class variety (for example, Wavy Covered Retrievers and American Water Spaniels). In like manner, review that labradors come in yellow, chocolate, and dark. Your vision-based calculation should vanquish this high intra-class variety to decide how to characterize these various shades as a similar variety. 
We likewise notice that irregular opportunity presents an outstandingly low bar: saving the way that the classes are somewhat imbalanced, an irregular estimate will give a right response approximately 1 of every multiple times, which compares to a precision of under 1%. Pre-process the Data:Model Architecture:How to compile the model:Syntax:Using the below syntax we can compile the Model Architecture: How to train the Model:How to Test the Model:We should test our model to know the output of our model: Predict Dog Breed with the Model:Step 5: Make a CNN to Order Dog Varieties (utilizing Move Learning)In Sync 4, we utilized move figuring out how to make a CNN utilizing VGG-16 bottleneck highlights. In this part, you should utilize the bottleneck highlights from an alternate pre-prepared model. To make things simpler for you, we have pre-processed the highlights for the organizations that are all as of now accessible in Keras:
Simply have to follow similar strides as the step4, then, at that point, we have a last Test exactness of 80.5024%. Step 6: Compose your AlgorithmCompose a calculation that acknowledges a document way to a picture and first decides if the picture contains a human, canine, or not one or the other. Then, in the event that a canine is recognized in the picture, return the anticipated variety. on the off chance that a human is recognized in the picture, return the looking like canine variety. assuming nor is recognized in the picture, give yield that demonstrates a blunder. Stage 7: Test Your Calculation: Result: (show the result) The eventual outcomes appears to be pretty precision, we can see that the canine variety expectation for canines are right, and the looking like variety for human are check out. Move learning works much more better than the CNN model I worked without any preparation. Primarily on the grounds that the model from move learning is prepared overwhelmingly of information, so the engineering previously comprehended what sort of highlights are generally delegate for a picture, which makes the order cycle substantially more simpler, and we do not have to forfeit the precision regardless of whether we have a lot of information. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








