| |

Regularization in Machine LearningWhat is Regularization?Regularization is one of the most important concepts of machine learning. It is a technique to prevent the model from overfitting by adding extra information to it. Sometimes the machine learning model performs well with the training data but does not perform well with the test data. It means the model is not able to predict the output when deals with unseen data by introducing noise in the output, and hence the model is called overfitted. This problem can be deal with the help of a regularization technique. This technique can be used in such a way that it will allow to maintain all variables or features in the model by reducing the magnitude of the variables. Hence, it maintains accuracy as well as a generalization of the model. It mainly regularizes or reduces the coefficient of features toward zero. In simple words, "In regularization technique, we reduce the magnitude of the features by keeping the same number of features." How does Regularization Work?Regularization works by adding a penalty or complexity term to the complex model. Let's consider the simple linear regression equation:
y= β0+β1x1+β2x2+β3x3+⋯+βnxn +b
In the above equation, Y represents the value to be predicted X1, X2, …Xn are the features for Y. β0,β1,…..βn are the weights or magnitude attached to the features, respectively. Here represents the bias of the model, and b represents the intercept. Linear regression models try to optimize the β0 and b to minimize the cost function. The equation for the cost function for the linear model is given below: 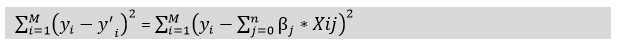
Now, we will add a loss function and optimize parameter to make the model that can predict the accurate value of Y. The loss function for the linear regression is called as RSS or Residual sum of squares. Techniques of RegularizationThere are mainly two types of regularization techniques, which are given below:
Ridge Regression
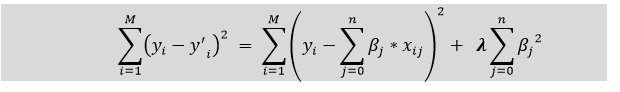
Lasso Regression:
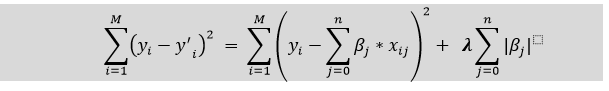
Key Difference between Ridge Regression and Lasso Regression
Next TopicExamples of Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








