| |

Cataract Detection Using Machine Learning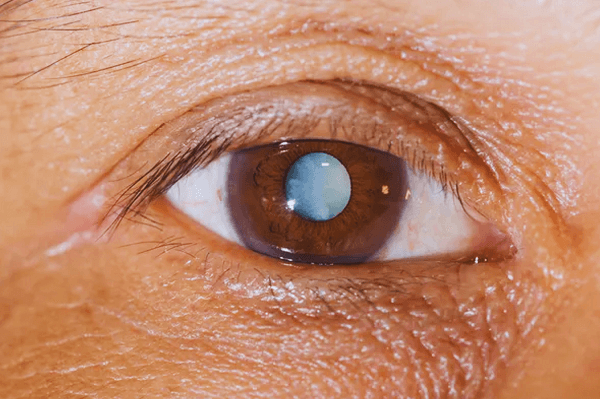
A lot of individuals get cataracts, which is a common eye problem, especially as they age. Because of this disorder, the eye's lens becomes clouded, impairing vision, sensitivity to light, and reduced nighttime vision. It is essential to identify cataracts as soon as possible in order to enable prompt treatment and stop future vision loss. By examining photographs of the eye, machine learning algorithms have the potential to help in the early diagnosis of cataracts. Working of Machine Learning Algorithm for Detecting CataractsA part of artificial intelligence called machine learning involves teaching algorithms to spot patterns in data. Machine learning algorithms may be trained on a huge dataset of eye pictures in the context of cataract diagnosis to learn how to distinguish between healthy and cataract-affected eyes. Researchers frequently utilize a collection of labeled eye photos to train a machine-learning system to identify cataracts. The algorithm is trained to identify patterns in the photos that separate cataract-affected eyes from normal eyes by categorizing each image in the dataset as either having a cataract or not. The algorithm may then be put to the test on a different set of eye photos to see how well it works. The sensitivity and specificity of the algorithm are determined to assess the accuracy of cataract detection. The following steps are commonly involved in the machine learning method for cataract detection:
Benefits of Cataract Detection Using Machine Learning
Limitations of Cataract Detection Using Machine Learning
Code ImplementationWe will try to distinguish the images of people, whether they have normal or cataract eyes. Here we will use two datasets: the Cataract dataset and Oculur Disease Recognition.
A Python package called "glob" is used to expand the paths to files and directories. Users may utilize wildcard patterns to search for files, and it will return a list of file paths that satisfy the search criteria. The "glob" library offers a simple way to find files using patterns like file names, file extensions, or directory names. In data science and machine learning projects, reading numerous files with identical names or esxtensions is a typical practice.
Two crucial machine learning operations, that are setting configurations and reading metadata, can boost the model's performance and can help in precise data handling. Setting configuration entails adjusting numerous settings or parameters for a model. These parameters may include hyperparameters like epochs, batch size, and learning rate, as well as those that have an impact on model behavior, such as regularisation techniques or optimizer algorithms. Data containing information about other data is known as metadata. Metadata in machine learning might include details on a dataset's size, the kinds of features or labels it contains, and other details about the data collection process, etc. In order to guarantee that the data is handled and processed correctly, reading metadata is a crucial step in machine learning. Developers can use suitable methods, such as imputation, to manage missing values, for instance, if the metadata shows some characteristics in the dataset that it has missing values.
Data must be gathered, cleaned, integrated, transformed, reduced, separated, and visualized as part of the processing of a dataset. To guarantee that the data is precise, consistent, and appropriate for analysis or machine learning, each step is crucial. Any data science or machine learning project must include data processing, which necessitates careful planning and close attention to detail. You may get the most out of your data by using these methods to prepare it for analysis or machine learning. Here we will be processing the Cataract Dataset. Output: 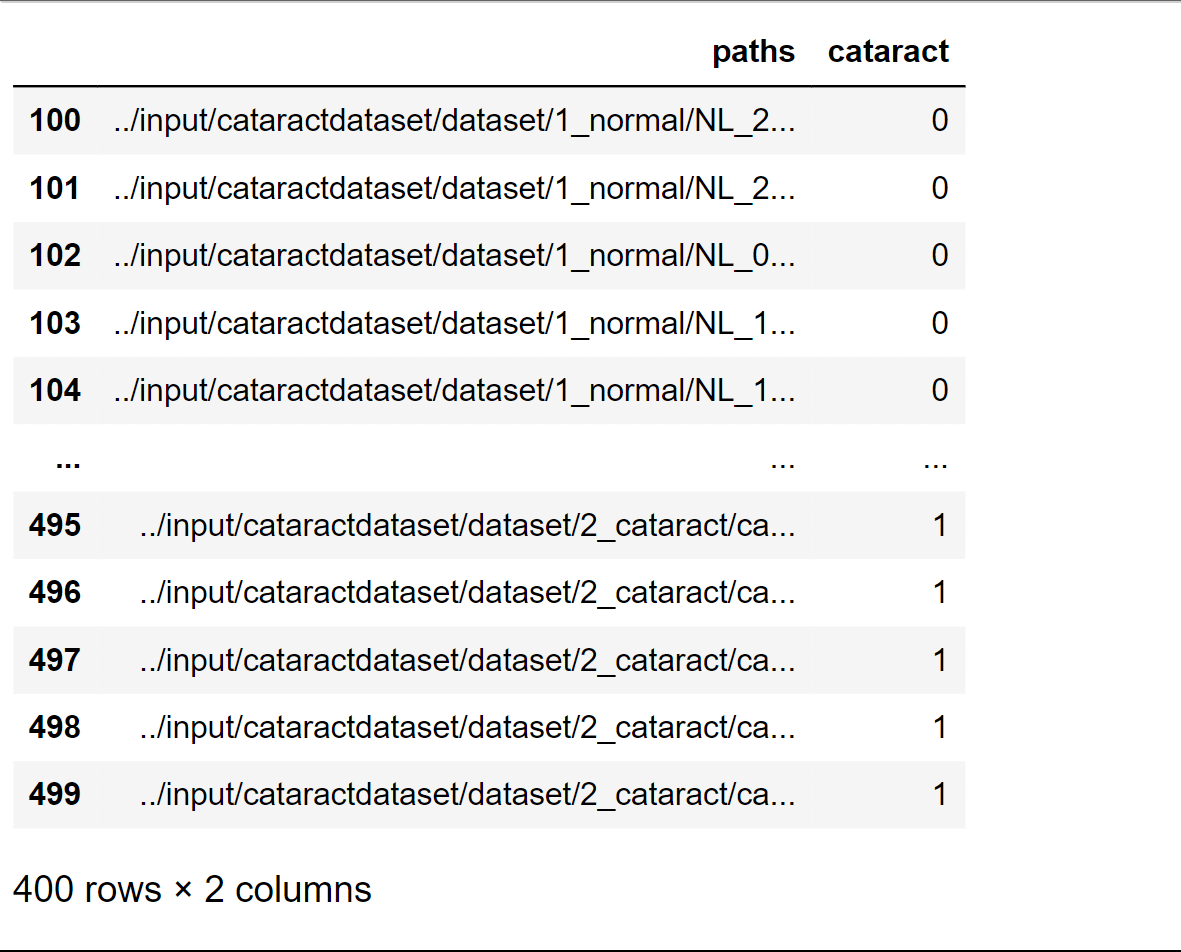
Output: 
Here we can see that there are 300 normal eye images and 100 images that are of cataracts.
Now we will be processing the Oculur Disease Recognition Dataset. Output: 
We made a function that will label the data whether the person has a cataract or not. Output: 
Here we get the file path of the left-eye images. Output: 
Here we get the file path of the right-eye images. Output: 
Here we obtained the number of left eye and right eye that has cataracts or not. Output: 
Output: 
Here we get the file path, where all the ocular disease-based images are present.
Here we will combine two metadata so that we can use it to load image data and to create a new dataset. Output: 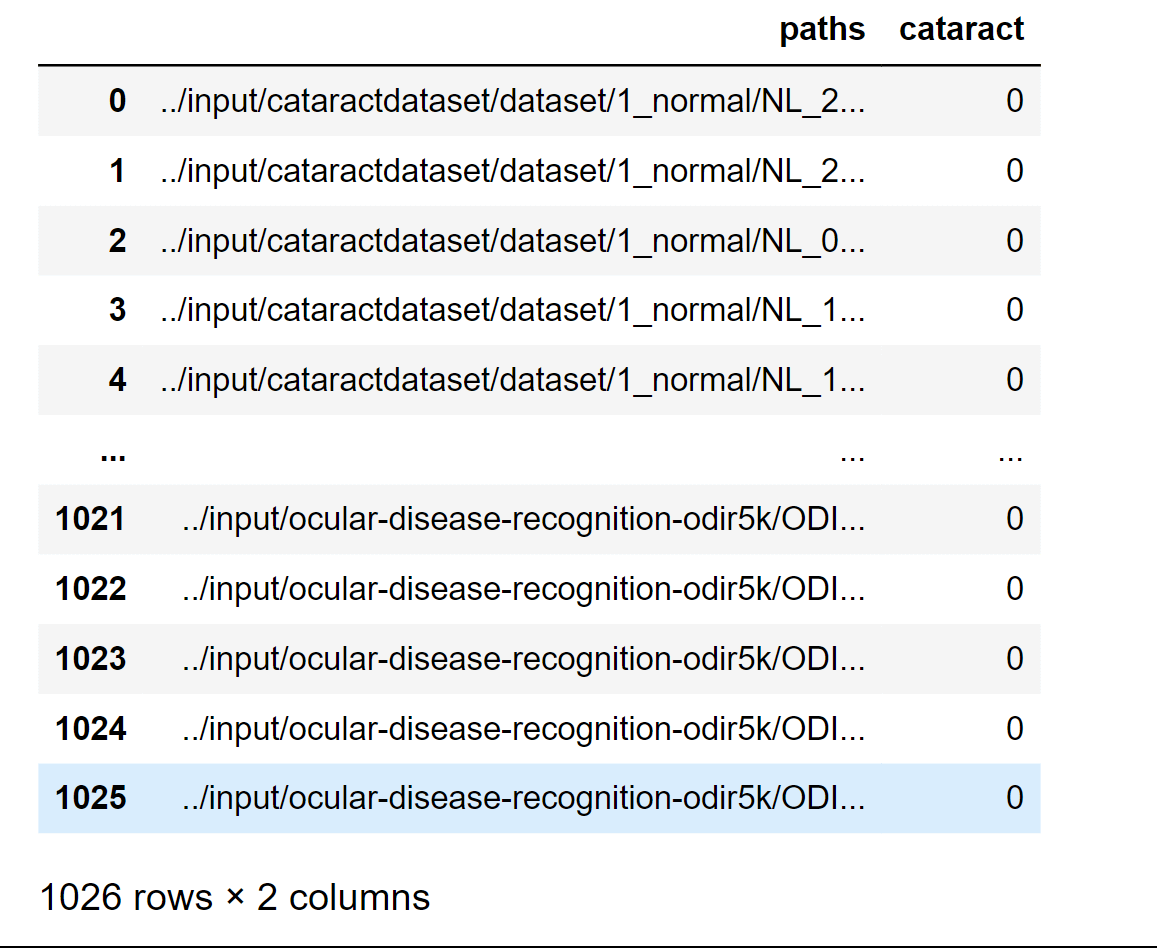
Output: 
Output: 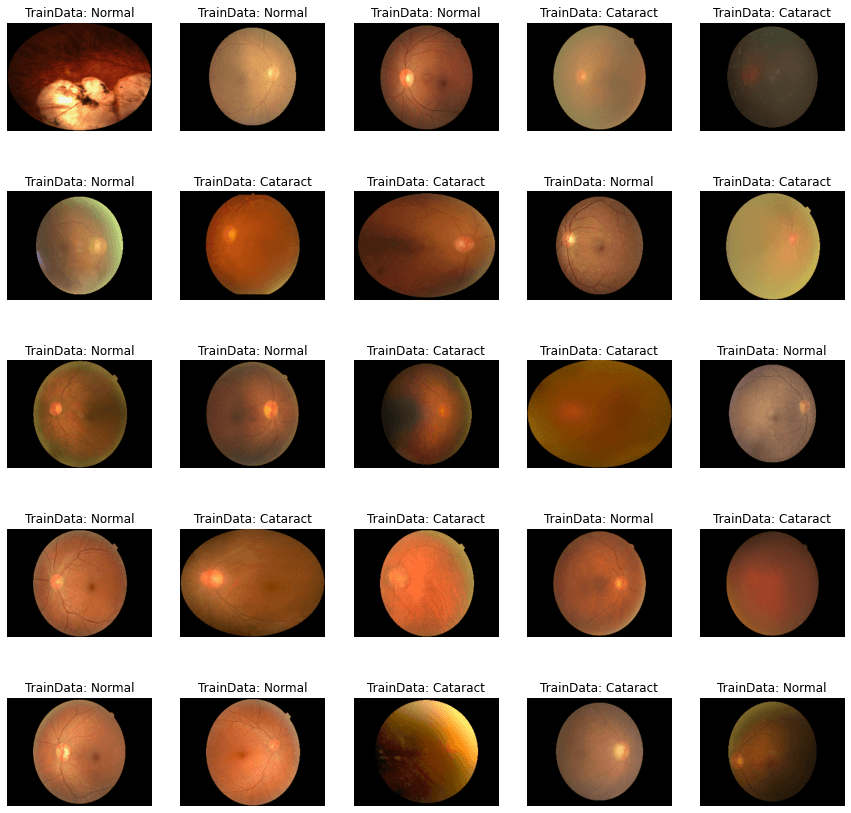
Considering testing, we still go for the 25 sheets for it. Output: 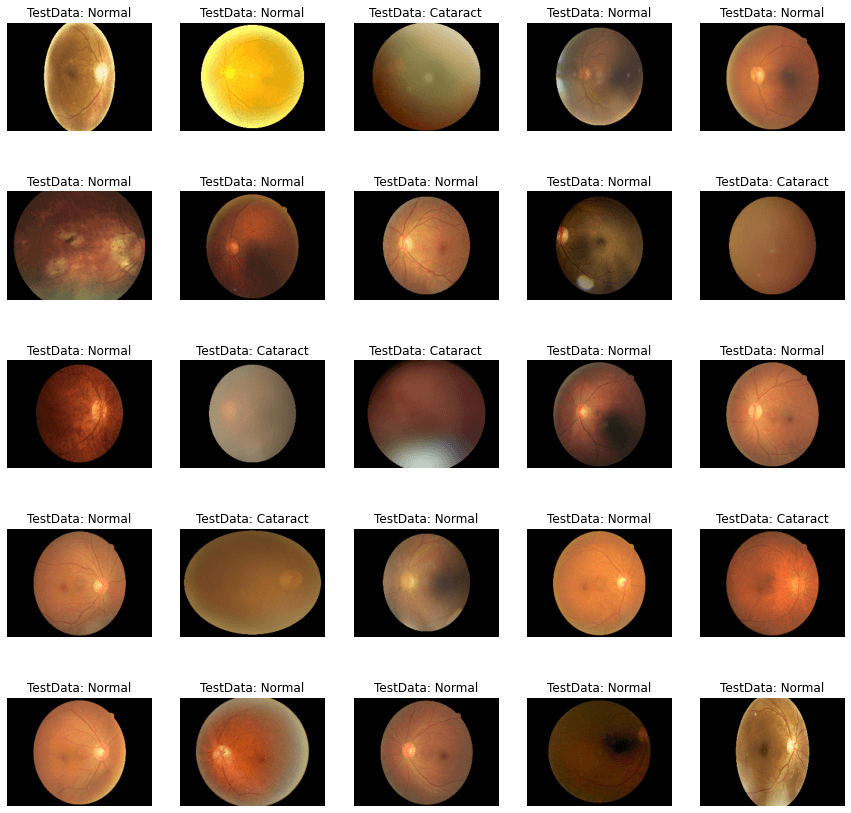
Modeling is the process of using a dataset to train a mathematical or statistical algorithm to find patterns or make predictions. Building a machine learning model with good generalizability to fresh data and effective prediction capabilities is the aim of modeling. Output: 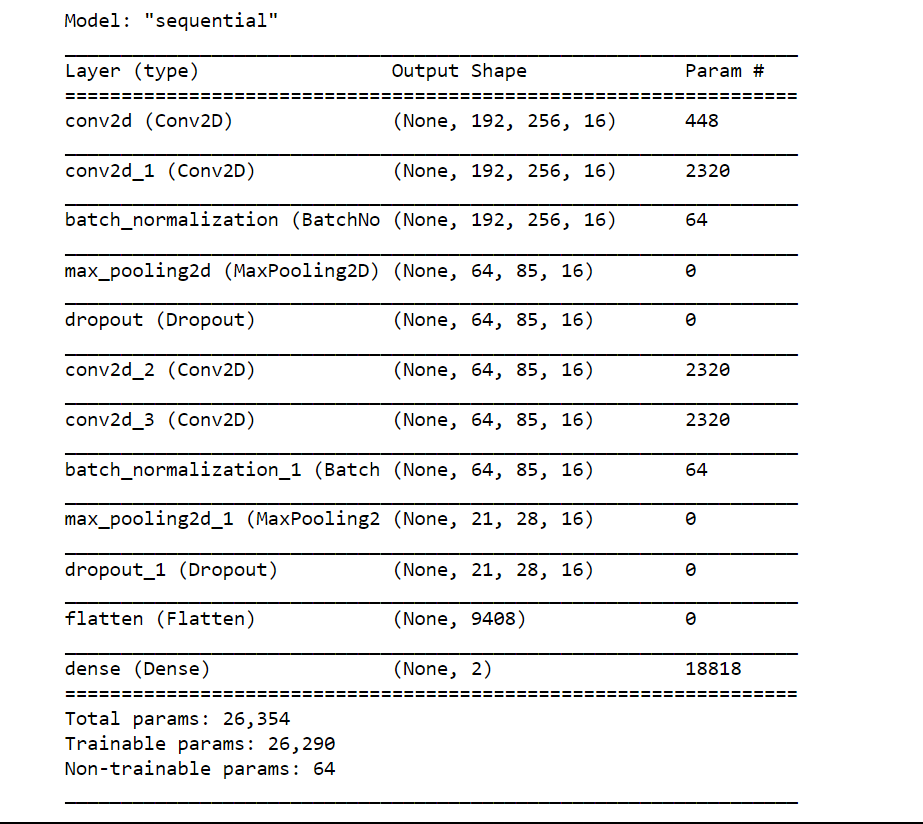
Now we will be creating randomly enhanced picture data from the ImageDataGenerator Object using some image data augmentation. Output: 
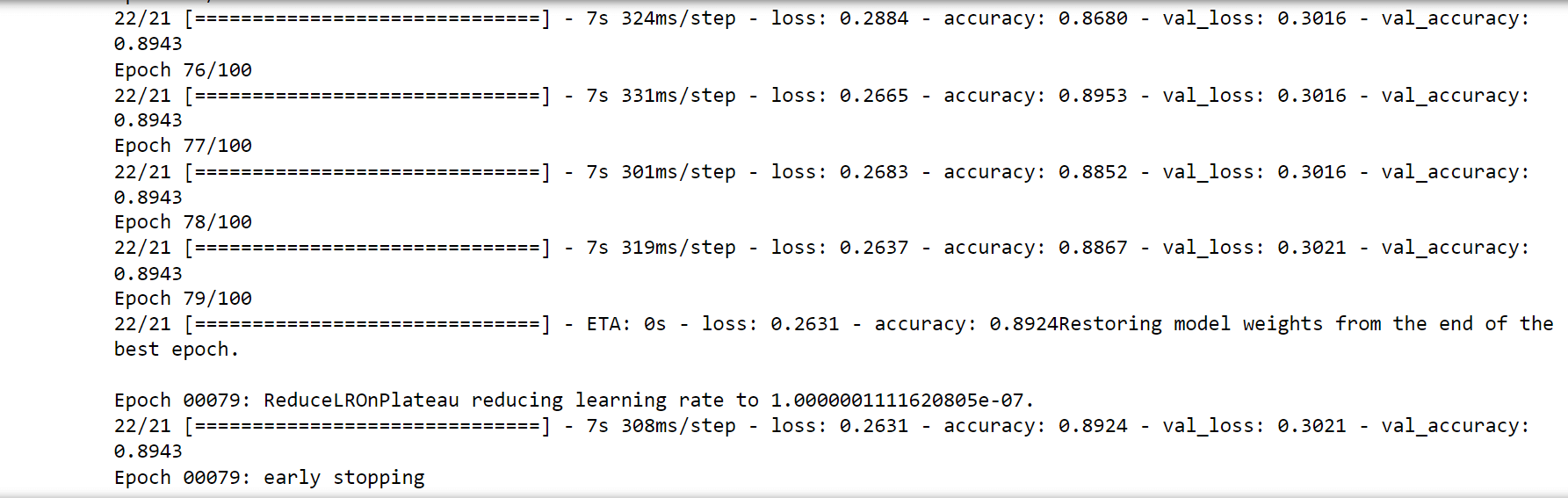
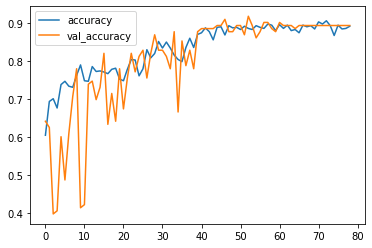
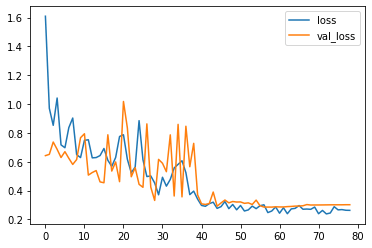
Now we will be evaluating the model. Output: 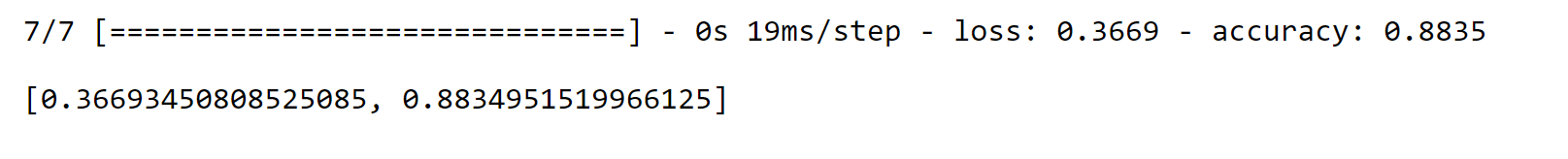
Well, the accuracy of the model is 88%, and the loss is 36%, which seems good. But we will apply a model that has been previously trained on the dataset. Several characteristics and trends in the data have already been identified by this pre-trained model, which might be useful for carrying out specific tasks. Output: 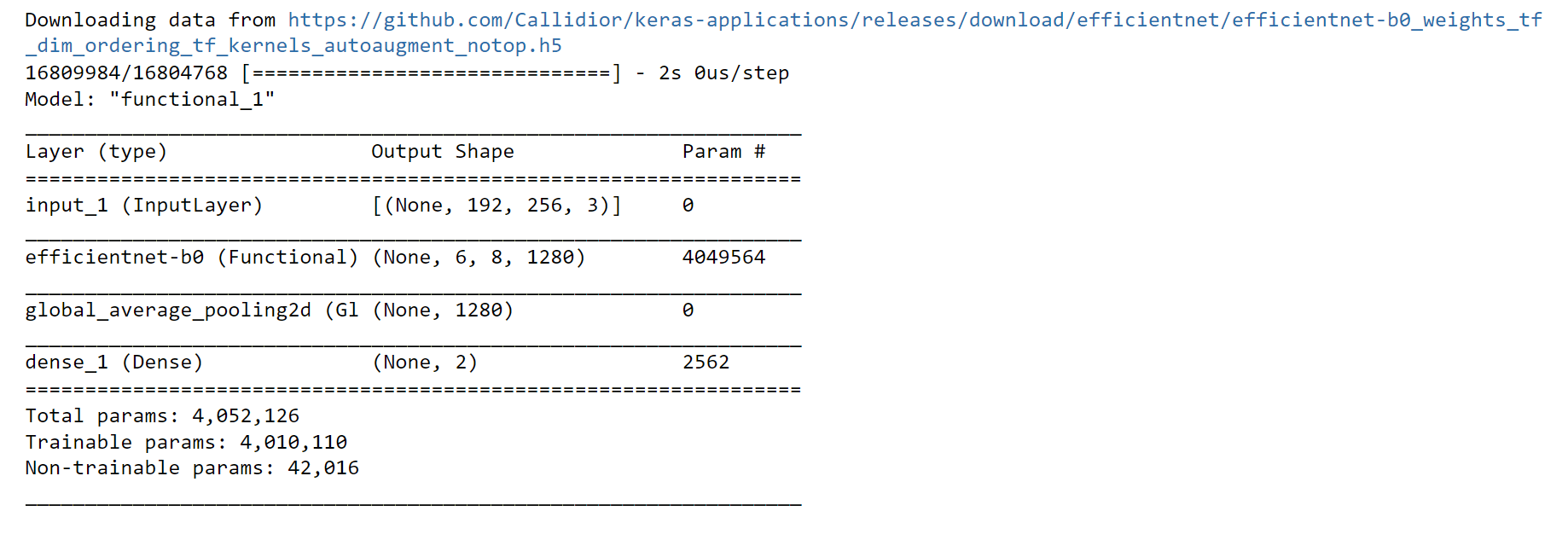
Output: 
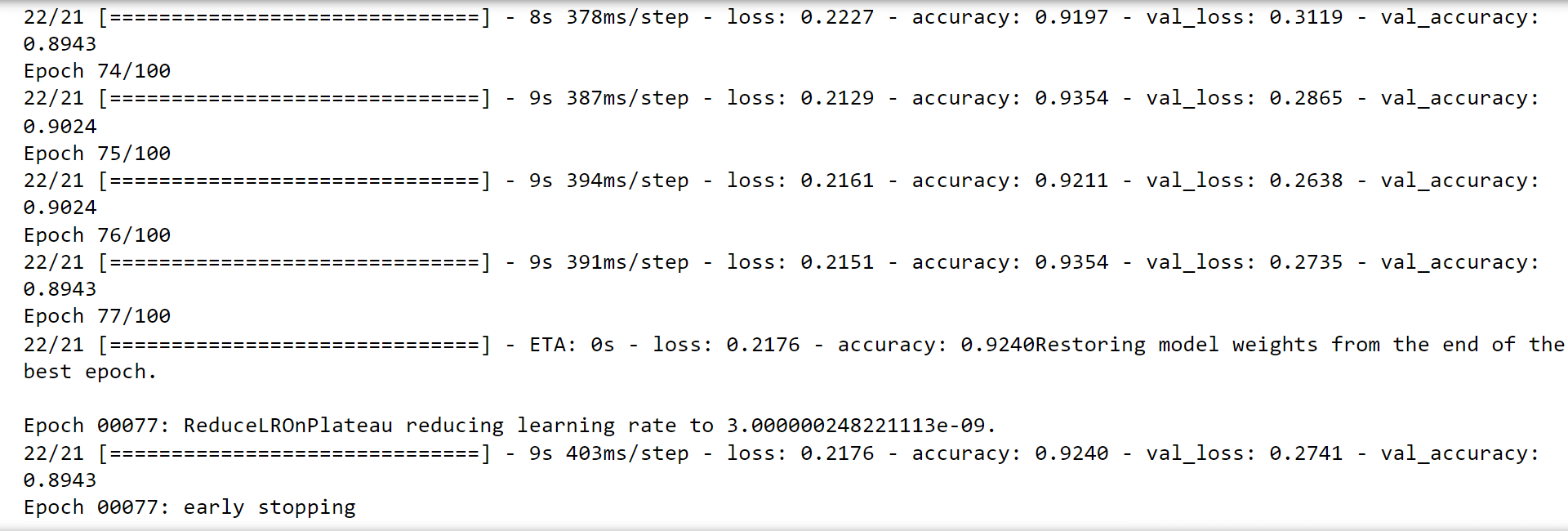
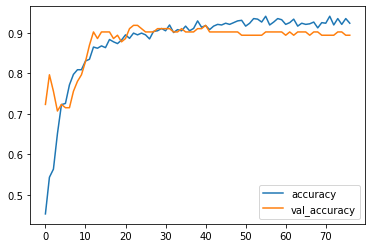
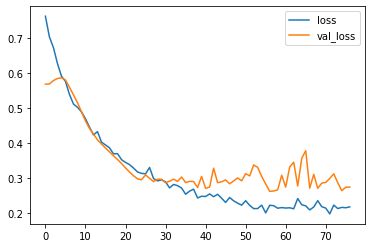
Re-Evaluating the modelOutput: 
Looking at the accuracy of the model while testing it, was 93% and with a loss of 21%, which is quite good. Considering it's an optical-based machine learning model, the accuracy is superb. ConclusionMachine learning-based cataract detection has the potential to enhance early diagnosis and treatment of cataracts, enabling individualized and effective patient care. Although this method has drawbacks and restrictions, continuous research and development are aimed at resolving these problems and enhancing the functionality and usability of machine learning algorithms for cataract detection. The future of cataract detection and treatment is bright with ongoing technological advancements and more researcher-clinician collaboration. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








