| |

Customer Segmentation Using Machine Learning
Customer segmentation is the process of dividing a customer base into groups of individuals that are similar in certain ways relevant to marketing, such as age, gender, interests, and spending habits. It enables companies to target specific groups with tailored promotions, products, or services that are most likely to resonate with them. Machine learning has become a popular tool for automating the process of customer segmentation, providing a more efficient and effective way to identify patterns and relationships within customer data. There are several different methods for using machine learning to perform customer segmentation, including:-
Advantages of Machine Learning for Customer Segmentation
We are now going to execute an unsupervised data clustering on the customer records from a grocery store's database. Importing LibrariesLoading DataOutput: 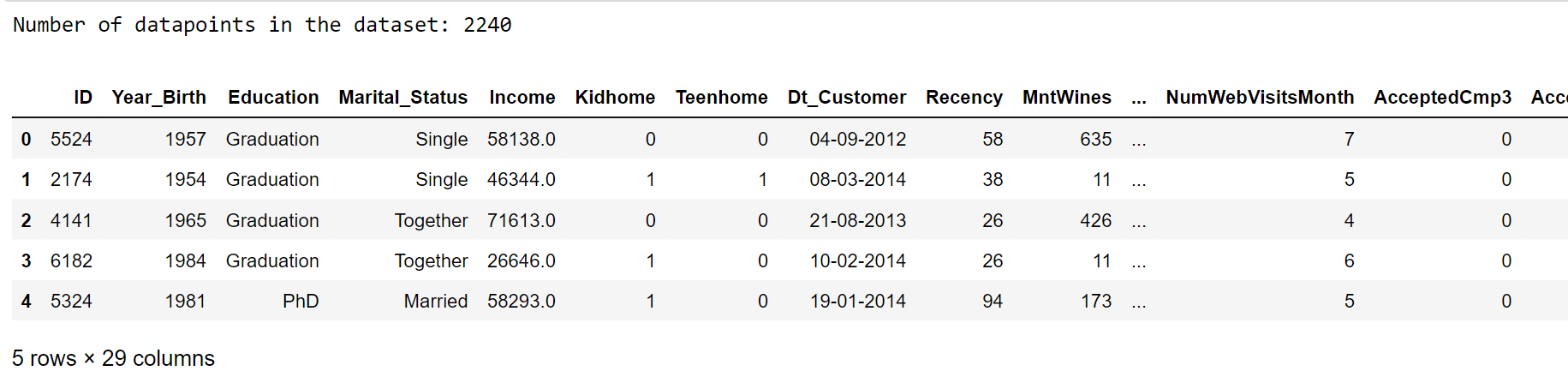
Data CleaningIn this, we will do the following task:
To gain a complete understanding of the procedures, we are going to clean the dataset. Let's examine the information included in the data. Output: 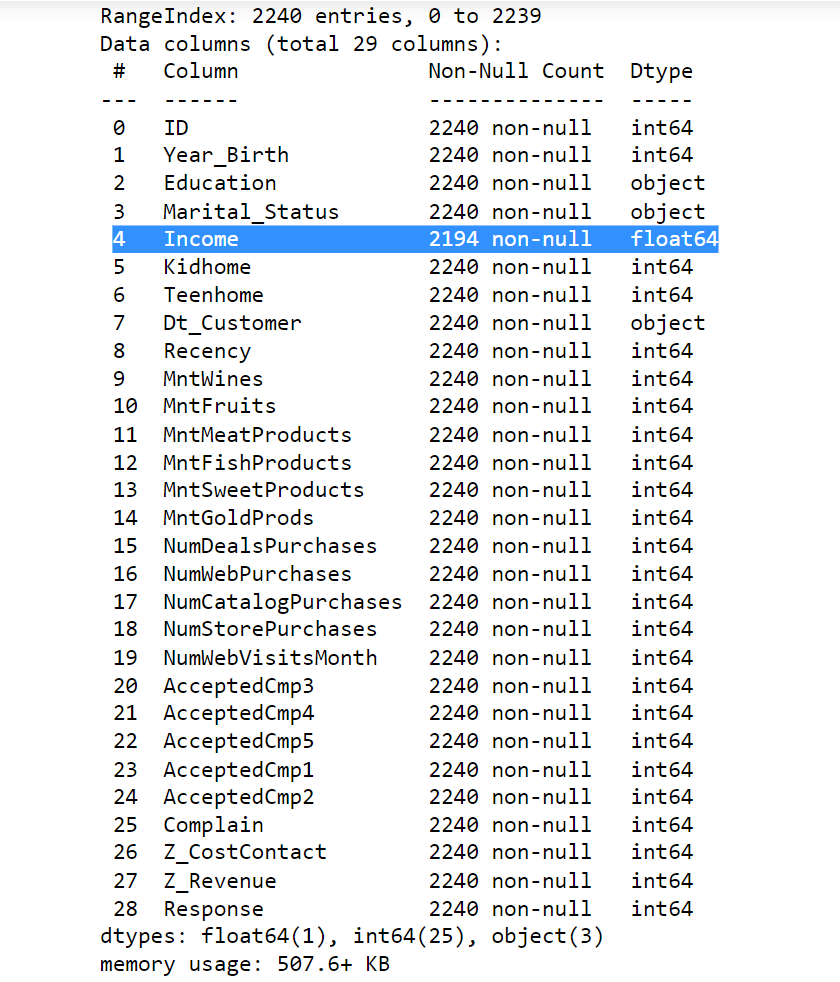
We may deduce and note the following from the output described above:
We will start by removing the rows with the missing income values for the missing values. Output: 
The next stage is to build a feature out of "Dt Customer" that shows how long a customer has been a registered user of the company's database. But to keep things straightforward, we are using this value in relation to the most recent client in the record. Therefore, we must compare the most recent and earliest recorded dates in order to obtain the values. Output: 
Output: 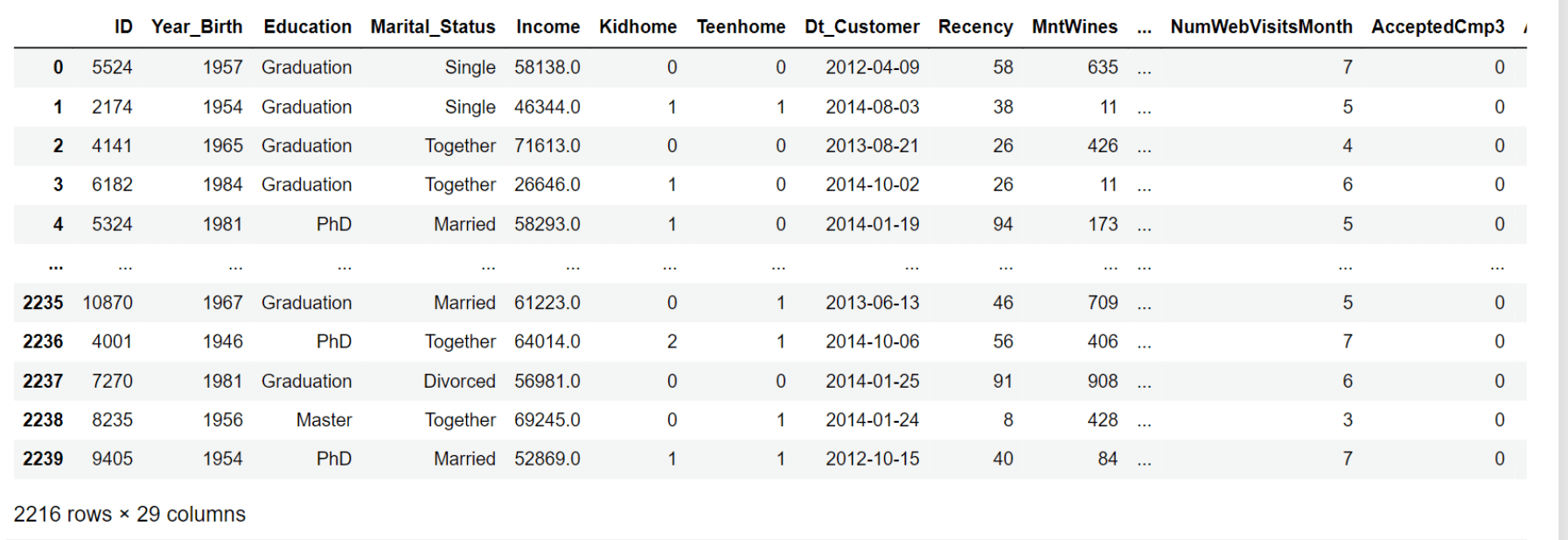
Making a feature ("Customer For How Much Time") that counts the days consumers have been shopping there compared to the date that was last recorded. To further understand the data, we will now investigate the distinctive values in the category characteristics. Output: 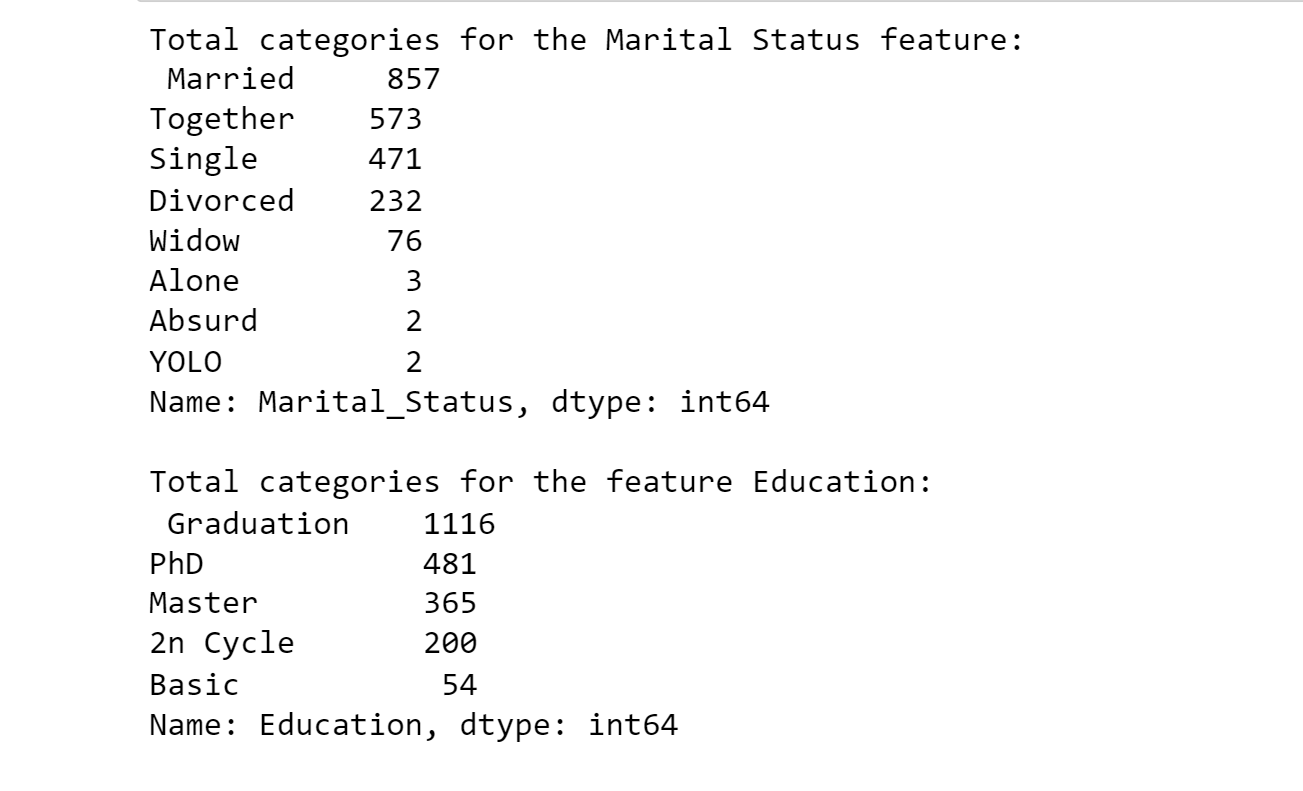
We will carry out the following procedures to engineer some new features in the next section:
Let's have a look at the statistics for the data now that we have some additional features. Output: 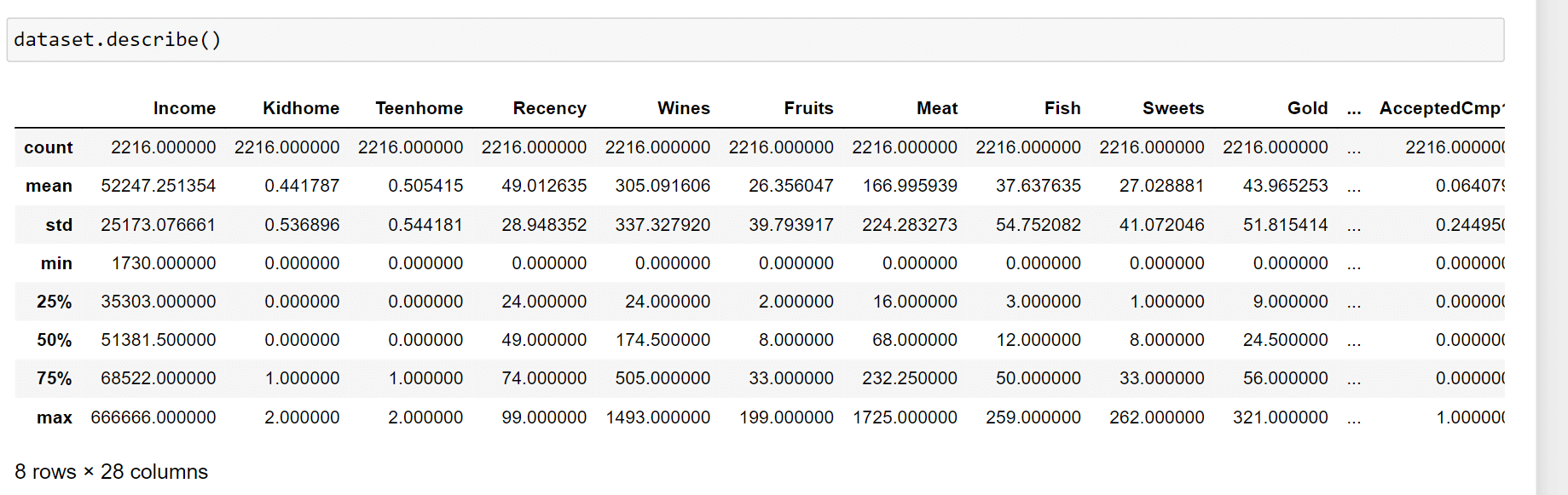
The statistics above demonstrate some variations in mean income and age as well as maximum income and age. Please take note that the maximum age is 128 years, as the data is outdated, and we computed the maximum age to be today (i.e. 2021). We need to look at the facts from a wider perspective. We will plot a few of the chosen characteristics. Output: Relational Script of a Few Selected Features: A subset of data <Figure size 800x550 with 0 Axes> 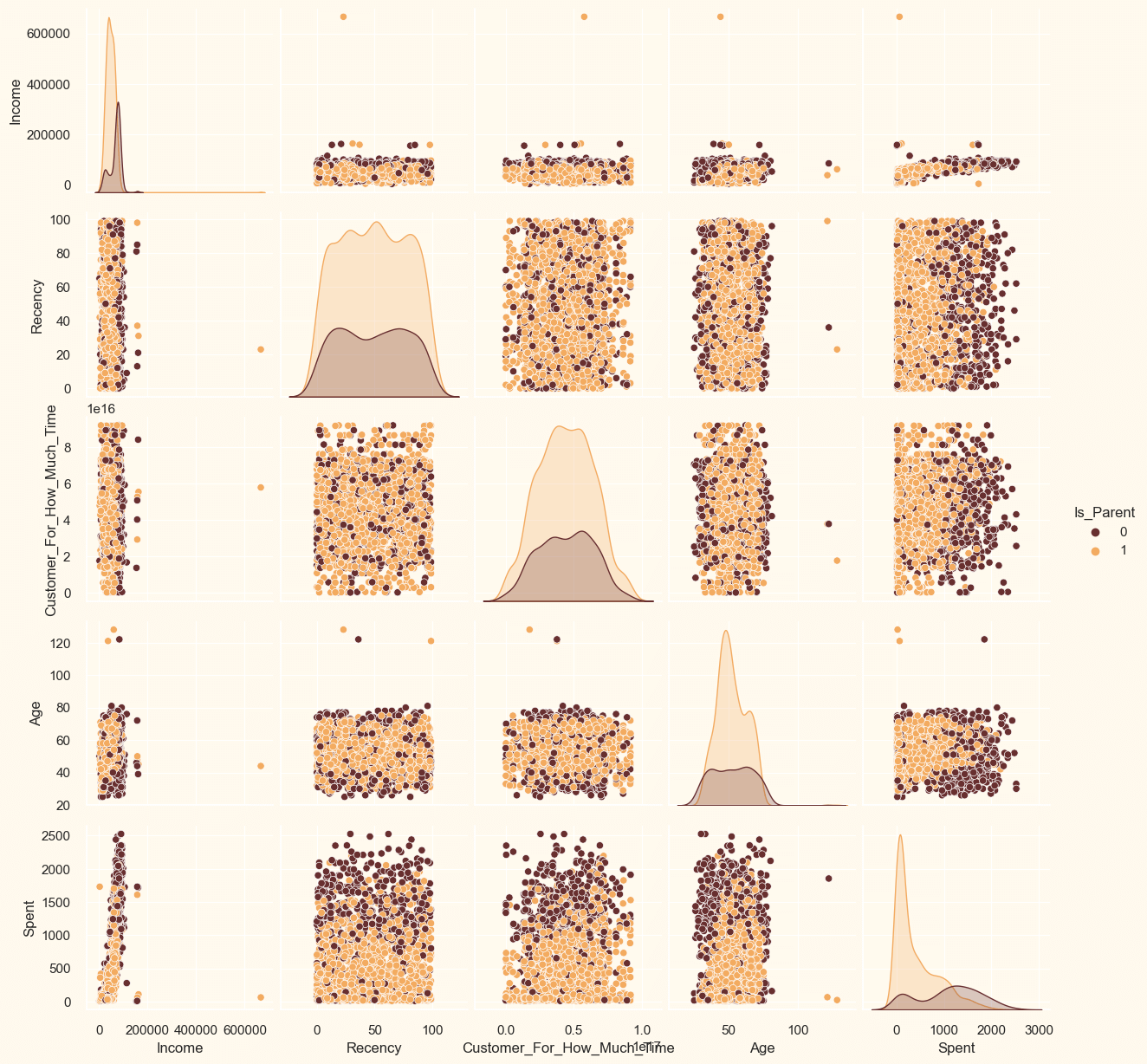
Clearly, the Income and Age characteristics contain a few anomalies. The data's outliers will be eliminated. Output: 
Let's now examine the relationships between the characteristics. (At this stage, leaving out the classified characteristics) Output: <AxesSubplot: > 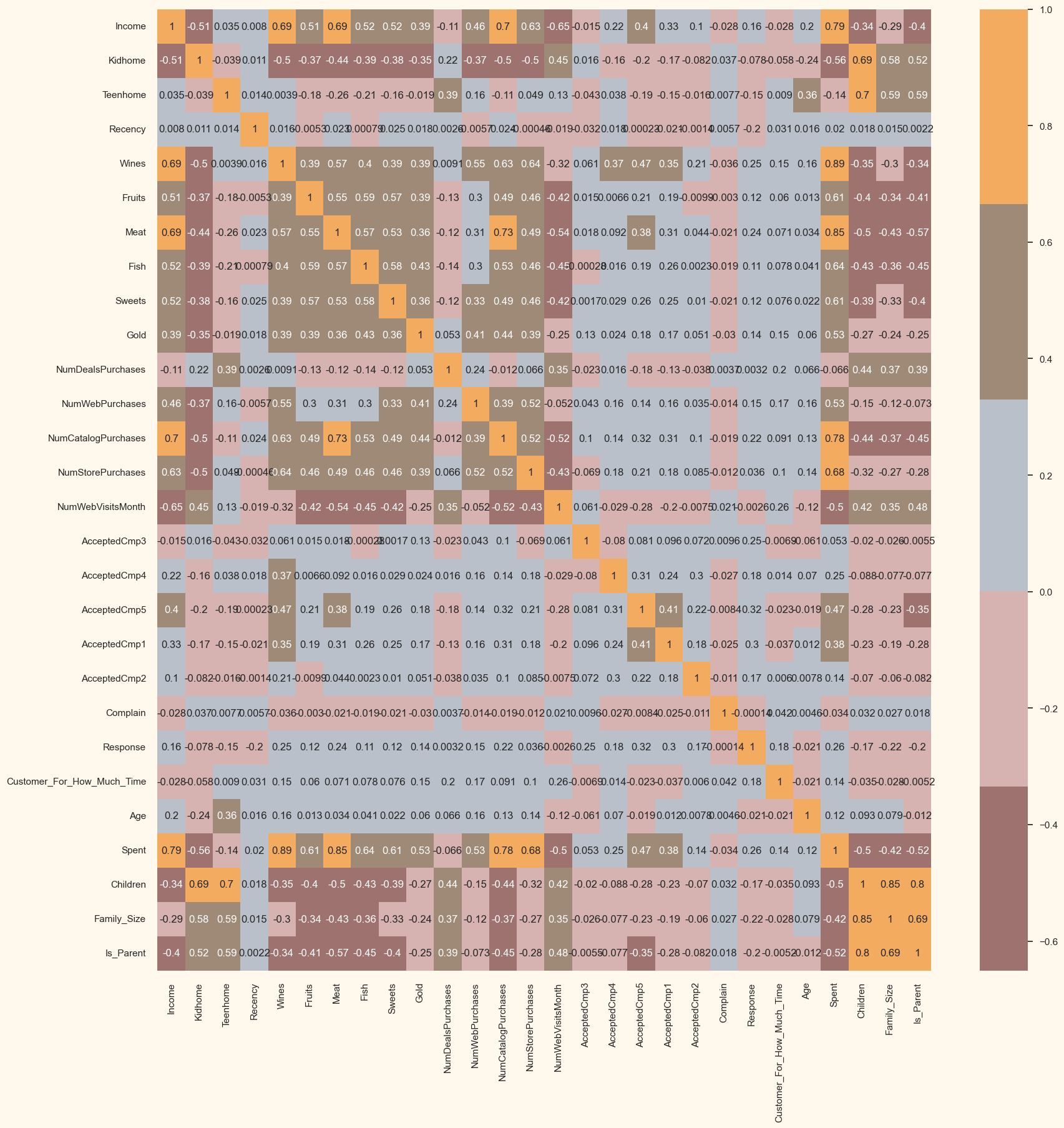
The new features are present, and the data is rather clean. We'll carry on to the following phase. Specifically, preparing the data. Data PreprocessingWe will preprocess the data in this part in order to do clustering procedures. The data is preprocessed using the procedures below:
Output: 
Output: 
Output: 
Output: 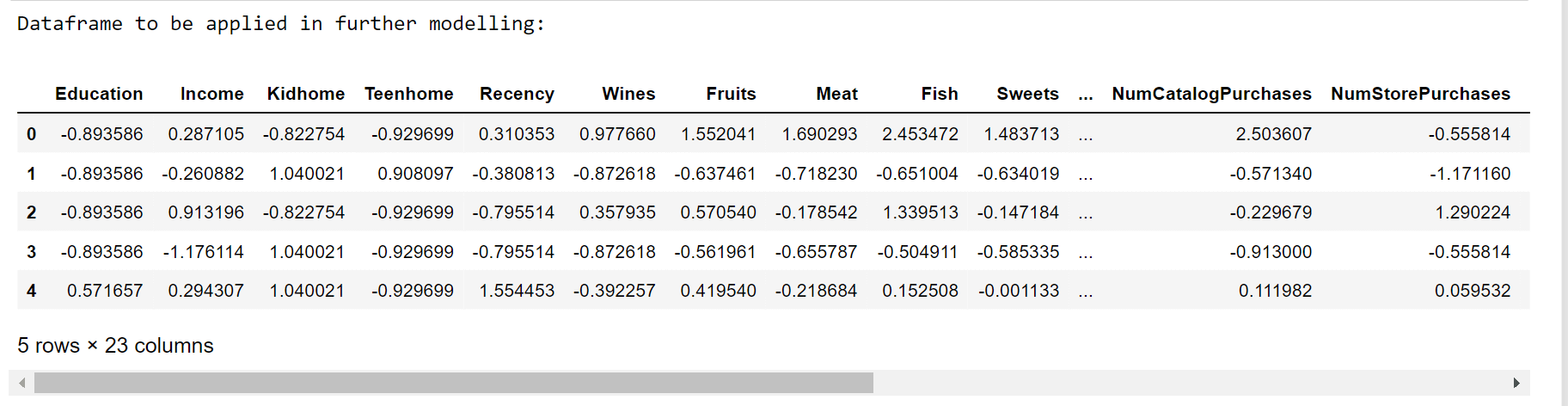
Dimensionality ReductionDimensionality reduction is a technique used in machine learning and data science to reduce the number of features or dimensions in a dataset, while retaining as much information as possible. The goal is to simplify the data while preserving its structure and relationships between variables. Principal Component Analysis (PCA) is a statistical technique that is used to analyze the structure of complex data sets, such as high-dimensional data sets. It is used to identify patterns in the data, which can then be used to reduce the dimensionality of the data, making it easier to visualize and interpret. The following actions in this section:
Output: 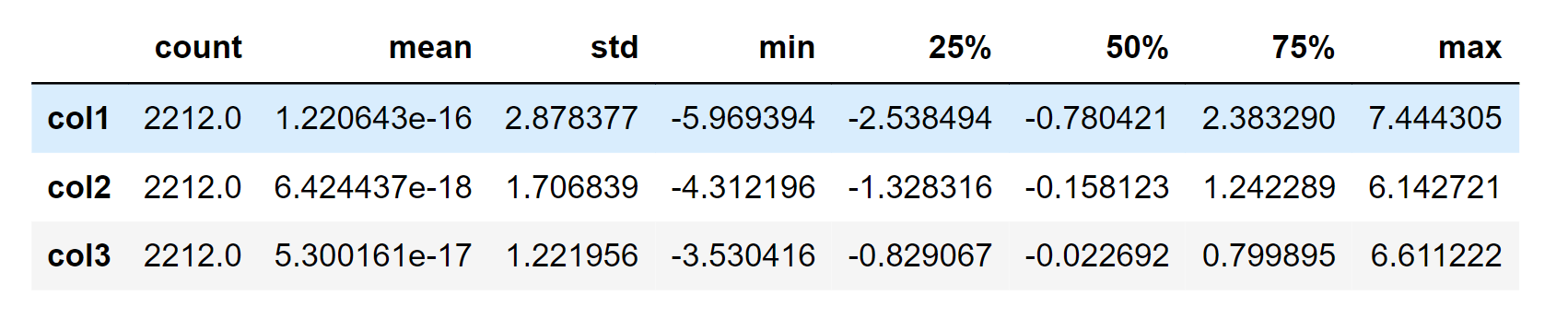
Output: 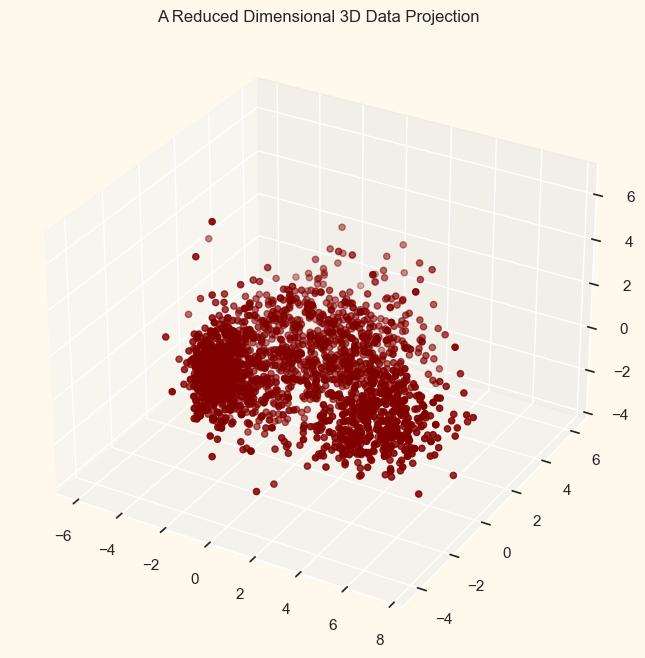
ClusteringAgglomerative Clustering will now be used to achieve the Clustering. A hierarchical clustering technique is agglomerative Clustering. Up until the appropriate number of clusters is reached, samples are merged. The steps in the Clustering:
Output: 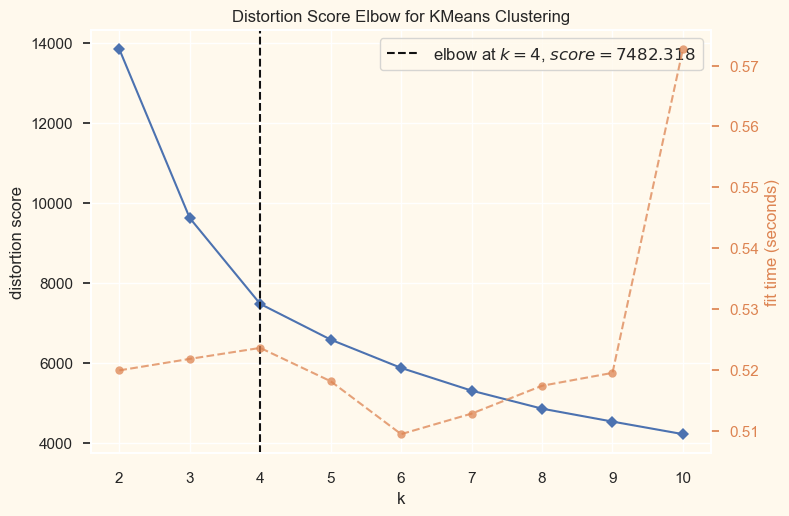
<AxesSubplot: title={'center': 'Distortion Score Elbow for KMeans Clustering'}, xlabel='k', ylabel='distortion score'> According to the cell above, four clusters will be the best choice for this set of data. To obtain the final clusters, we will then fit the agglomerative clustering model. Let's look at the clusters' 3-D distribution to investigate the clusters that were produced. Output: 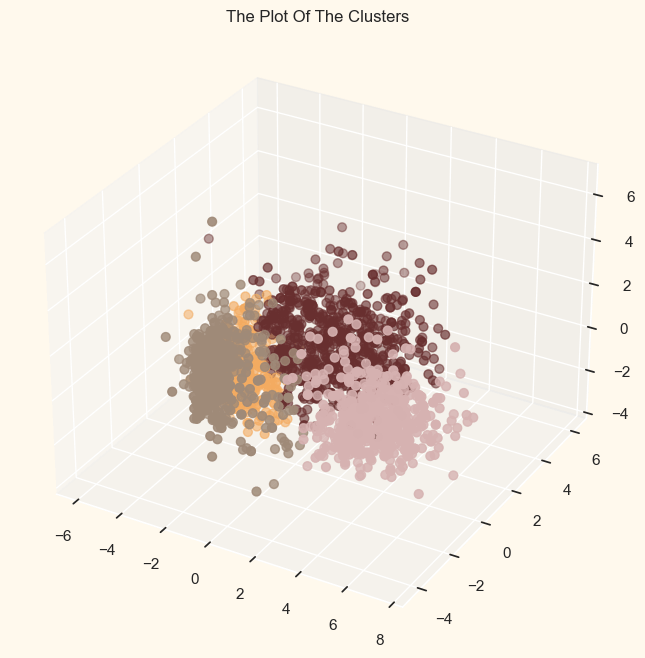
Evaluation ModelsSince this Clustering was done without supervision, our model cannot be evaluated or scored since it lacks a tagged feature. This section's goal is to examine the patterns in the clusters that have developed and ascertain their nature. In order to do that, we will use exploratory data analysis to look at the data in the context of clusters and make judgements. Output: 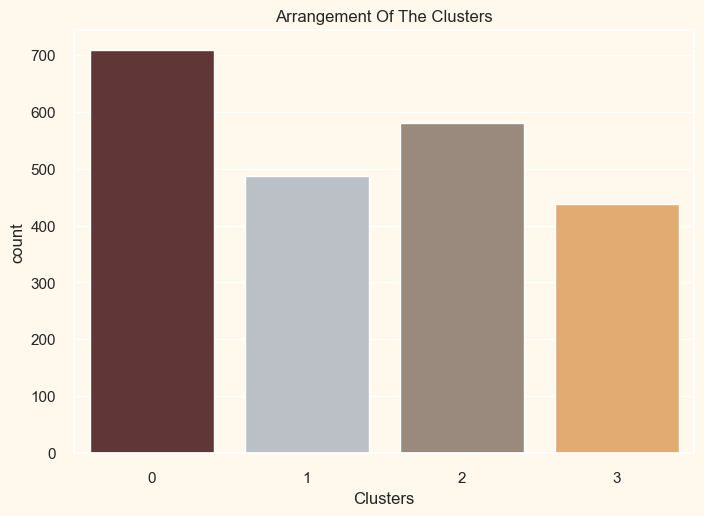
The clusters seem to be fairly distributed. Output: 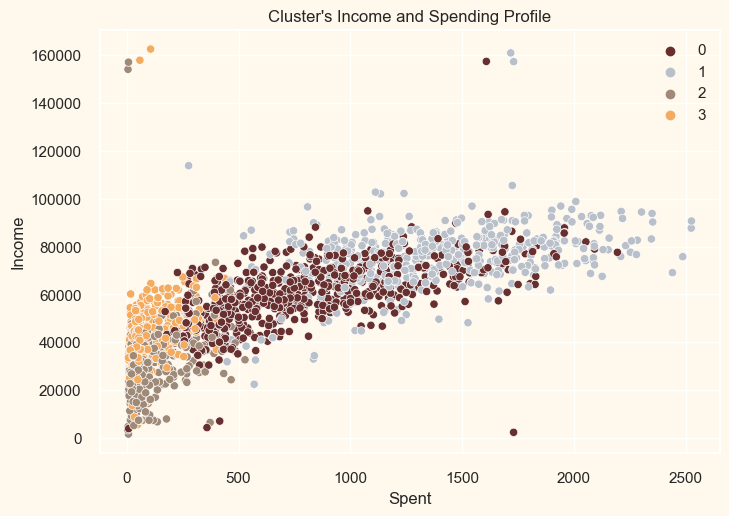
The cluster pattern is shown in the income vs expenditure figure.
The specific distribution of clusters according to the different goods in the data will be the subject of our next examination. The following: Wines, Fruits, Meat, Fish, Sweets, and Gold. Output: 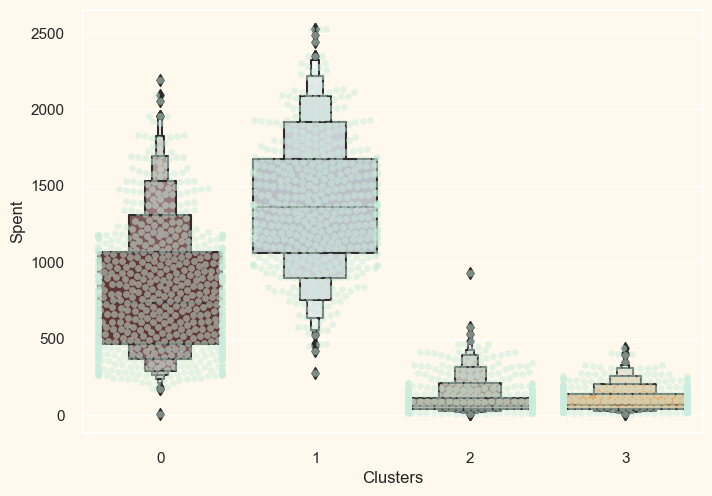
It is evident from the plot above that cluster 1 is our largest group of clients, closely followed by cluster 0. We may investigate the focused marketing methods each cluster is investing in. Next, let's look at how our past campaigns performed. Output: 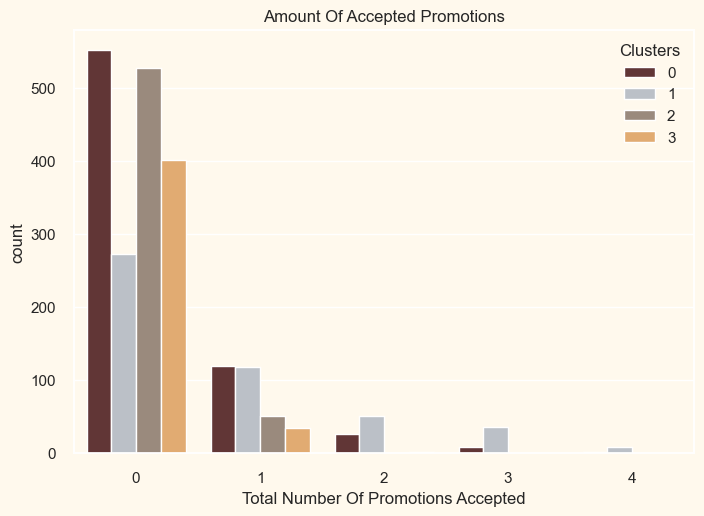
The campaigns have not yet received a large reaction. generally very few participants. Furthermore, no one portion can include all five of them. Perhaps more well designed and targeted promotions are needed to increase sales. Output: 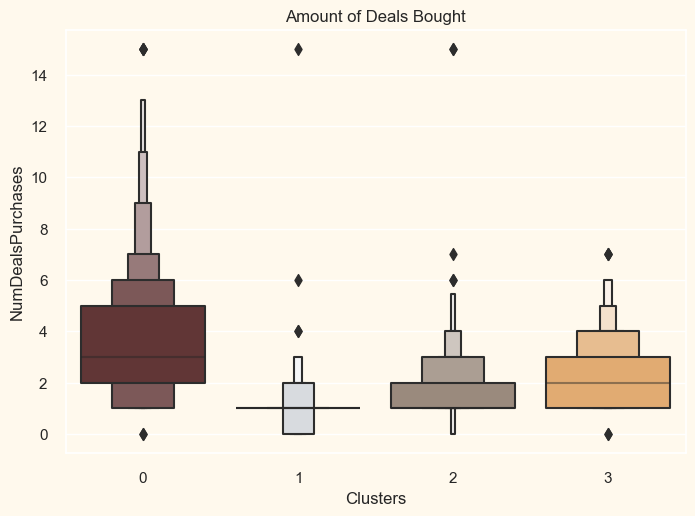
Campaigns failed, but the transactions were successful. The greatest results came from clusters 0 and 3. Cluster 1, one of our top clients, isn't very interested in the agreements, though. Nothing appears to powerfully draw cluster 2 in. Output: <Figure size 800x550 with 0 Axes> 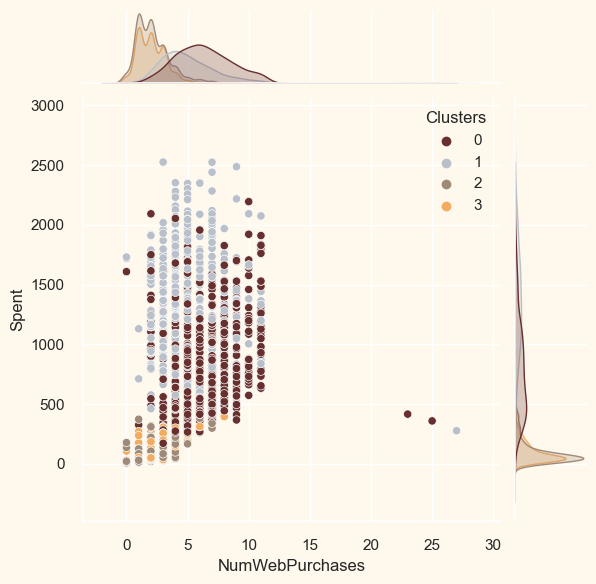
<Figure size 800x550 with 0 Axes> 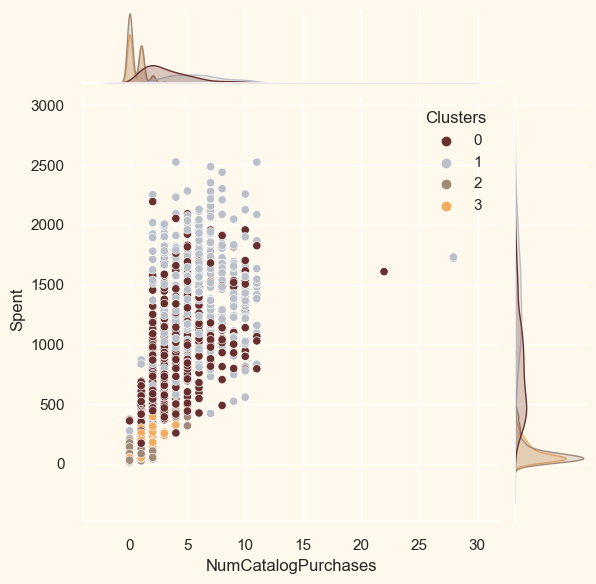
<Figure size 800x550 with 0 Axes> 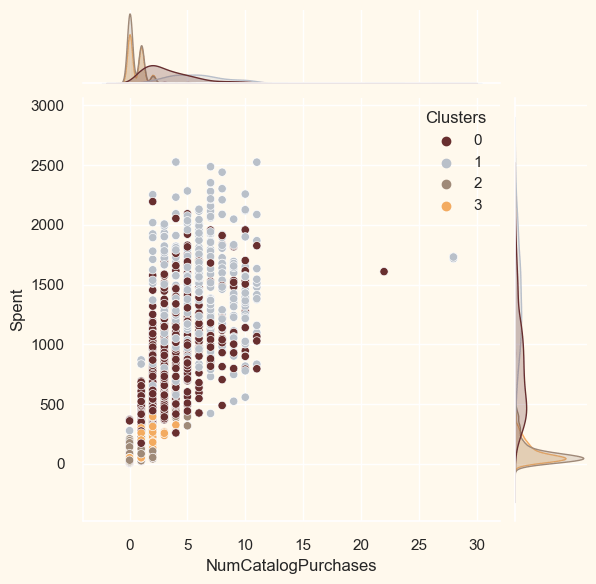
<Figure size 800x550 with 0 Axes> 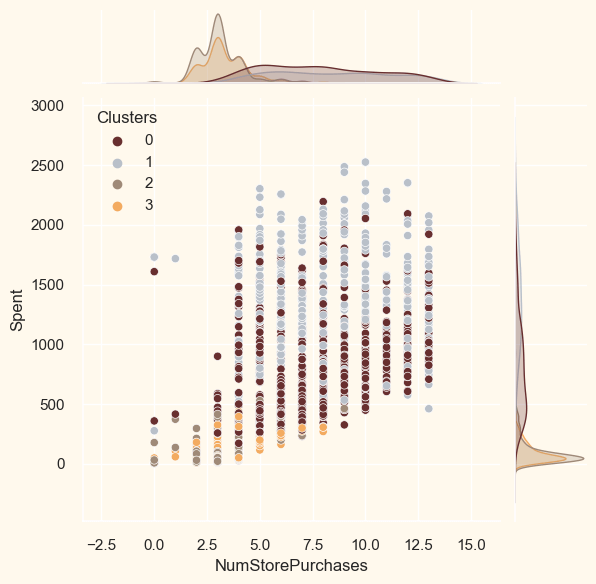
<Figure size 800x550 with 0 Axes> 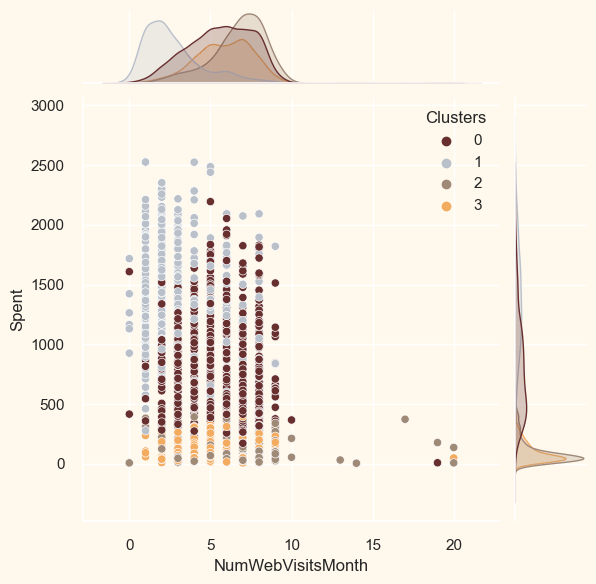
ProfilingNow that the clusters have been created and their purchasing patterns have been examined. Let's take a look at each individual in these clusters. In order to determine who is our star client and who requires further attention from the retail store's marketing staff, we will be profiling the clusters that have been developed. To make the decision that, in light of the cluster the client is in, we will be graphing some of the aspects that are indicative of their personal characteristics. We shall get to the conclusions based on the results. Output: <Figure size 800x550 with 0 Axes> 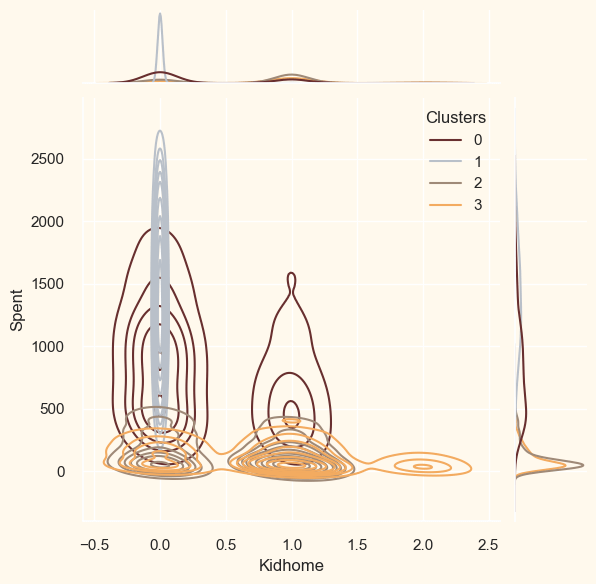
<Figure size 800x550 with 0 Axes> 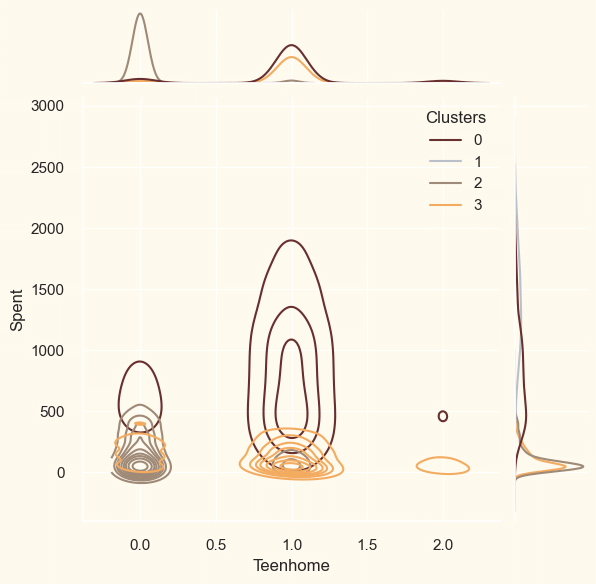
<Figure size 800x550 with 0 Axes> 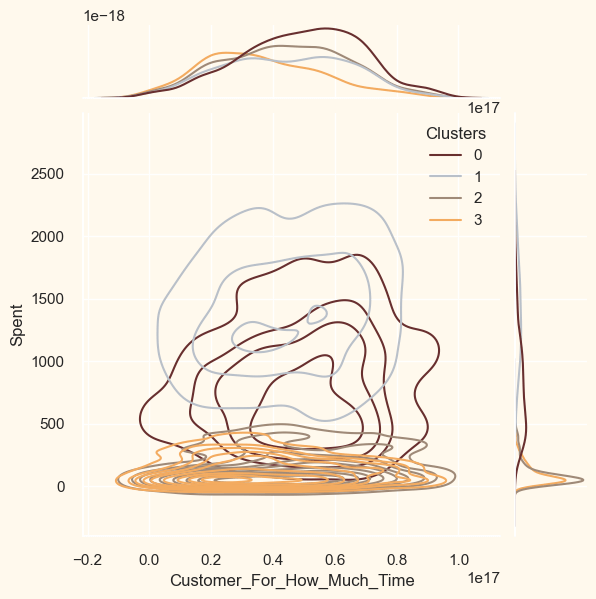
<Figure size 800x550 with 0 Axes> 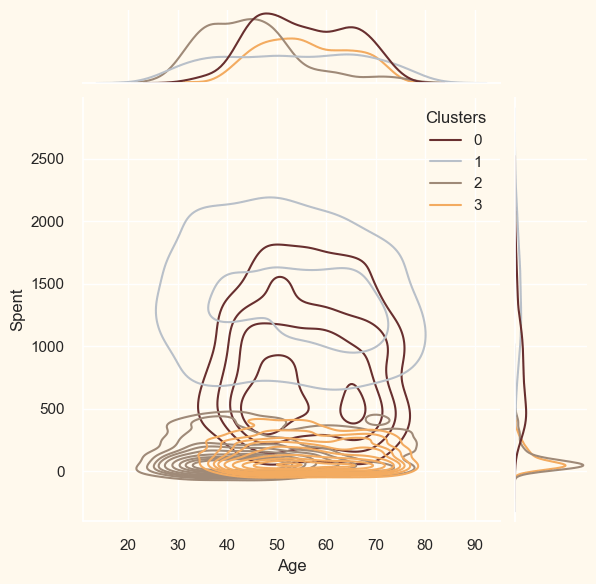
<Figure size 800x550 with 0 Axes> 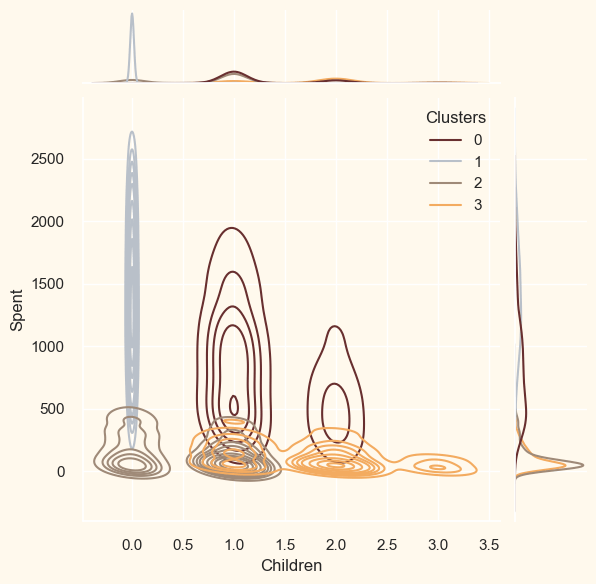
<Figure size 800x550 with 0 Axes> 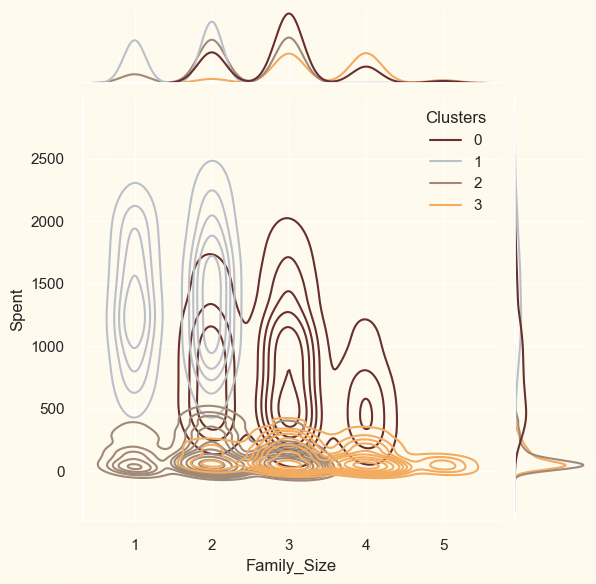
<Figure size 800x550 with 0 Axes> 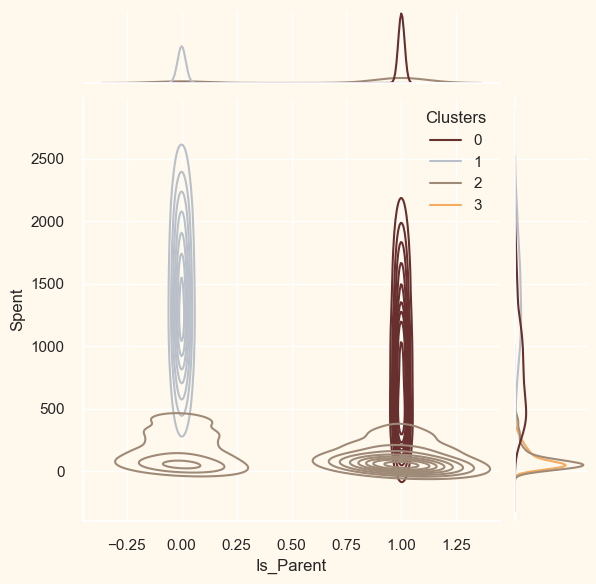
<Figure size 800x550 with 0 Axes> 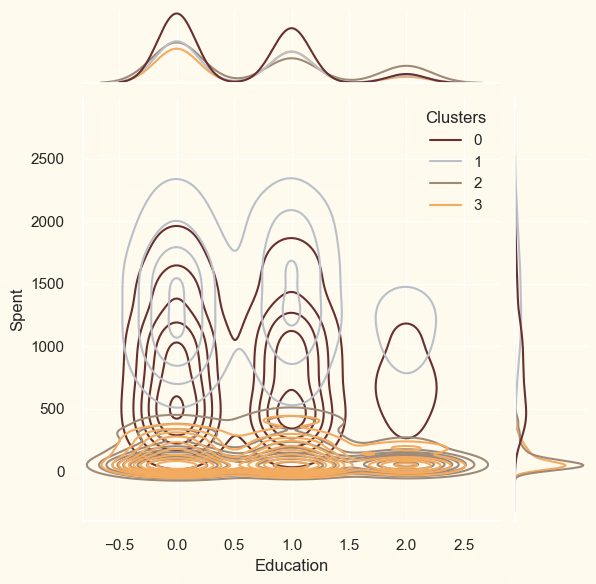
<Figure size 800x550 with 0 Axes> 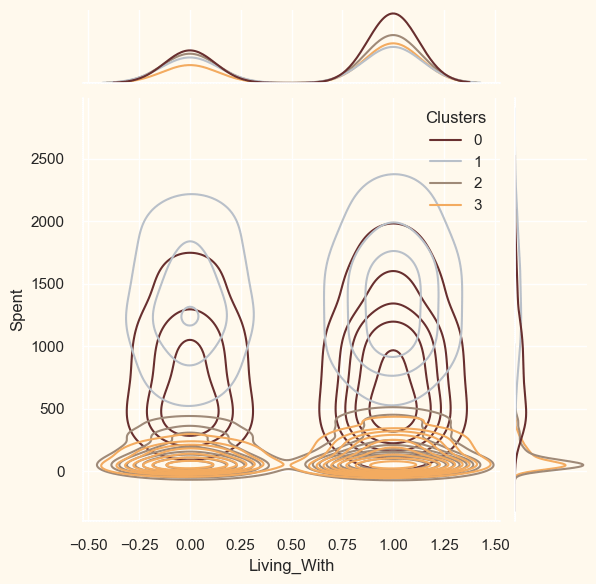
Cluster Number 0:
Cluster Number 1 :
Cluster Number 2:
Cluster Number 3:
Unsupervised Clustering was done. Dimensionality reduction and agglomerative Clustering were both used. We developed four clusters and utilized them to profile clients in clusters based on their family configurations, income levels, and spending habits. This may be applied to creating better marketing plans. In conclusion, customer segmentation is a critical aspect of marketing strategy, and machine learning has become an increasingly popular tool for automating the process. By using machine learning algorithms to process vast amounts of customer data, companies can quickly identify new trends and patterns, target specific customer segments with tailored promotions, and make more informed marketing decisions. With its ability to process data in real time, eliminate the need for manual analysis, and continuously improve over time, machine learning is a powerful tool for customer segmentation. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








