| |

What is Backward Elimination?Backward elimination is a feature selection technique while building a machine learning model. It is used to remove those features that do not have a significant effect on the dependent variable or prediction of output. There are various ways to build a model in Machine Learning, which are:
Above are the possible methods for building the model in Machine learning, but we will only use here the Backward Elimination process as it is the fastest method. Steps of Backward EliminationBelow are some main steps which are used to apply backward elimination process: Step-1: Firstly, We need to select a significance level to stay in the model. (SL=0.05) Step-2: Fit the complete model with all possible predictors/independent variables. Step-3: Choose the predictor which has the highest P-value, such that.
Step-4: Remove that predictor. Step-5: Rebuild and fit the model with the remaining variables. Need for Backward Elimination: An optimal Multiple Linear Regression model:In the previous chapter, we discussed and successfully created our Multiple Linear Regression model, where we took 4 independent variables (R&D spend, Administration spend, Marketing spend, and state (dummy variables)) and one dependent variable (Profit). But that model is not optimal, as we have included all the independent variables and do not know which independent model is most affecting and which one is the least affecting for the prediction. Unnecessary features increase the complexity of the model. Hence it is good to have only the most significant features and keep our model simple to get the better result. So, in order to optimize the performance of the model, we will use the Backward Elimination method. This process is used to optimize the performance of the MLR model as it will only include the most affecting feature and remove the least affecting feature. Let's start to apply it to our MLR model. Steps for Backward Elimination method:We will use the same model which we build in the previous chapter of MLR. Below is the complete code for it: From the above code, we got training and test set result as: Train Score: 0.9501847627493607 Test Score: 0.9347068473282446 The difference between both scores is 0.0154. Note: On the basis of this score, we will estimate the effect of features on our model after using the Backward elimination process.Step: 1- Preparation of Backward Elimination:
Here we have used axis =1, as we wanted to add a column. For adding a row, we can use axis =0. Output: By executing the above line of code, a new column will be added into our matrix of features, which will have all values equal to 1. We can check it by clicking on the x dataset under the variable explorer option. 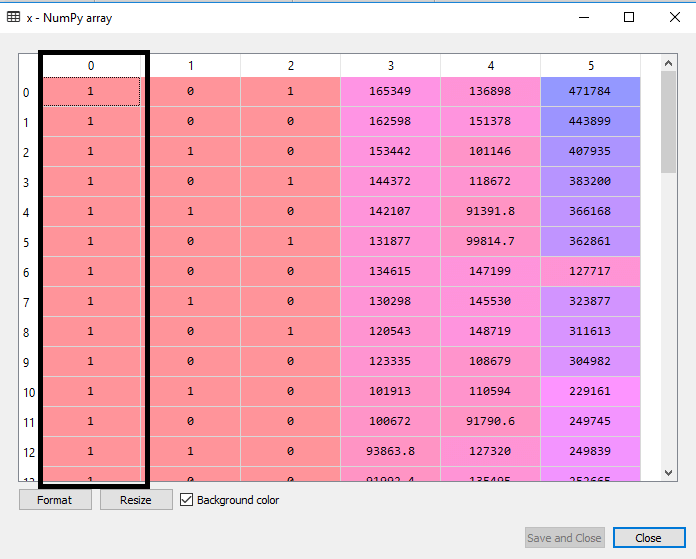
As we can see in the above output image, the first column is added successfully, which corresponds to the constant term of the MLR equation. Step: 2:
Output: By executing the above lines of code, we will get a summary table. Consider the below image: 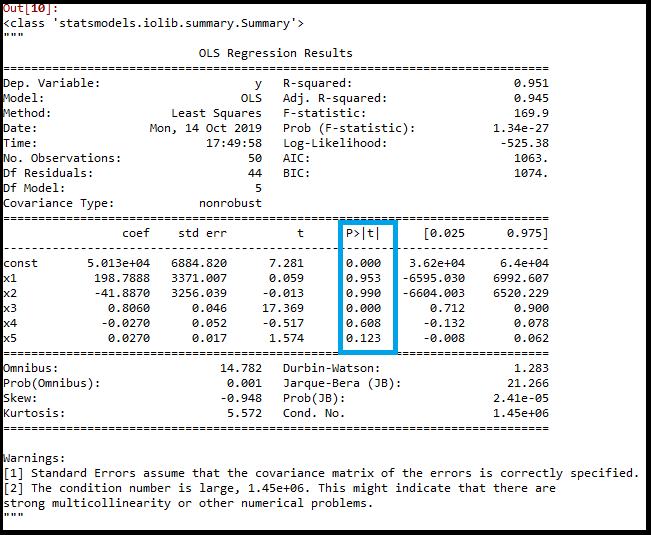
In the above image, we can clearly see the p-values of all the variables. Here x1, x2 are dummy variables, x3 is R&D spend, x4 is Administration spend, and x5 is Marketing spend. From the table, we will choose the highest p-value, which is for x1=0.953 Now, we have the highest p-value which is greater than the SL value, so will remove the x1 variable (dummy variable) from the table and will refit the model. Below is the code for it: Output: 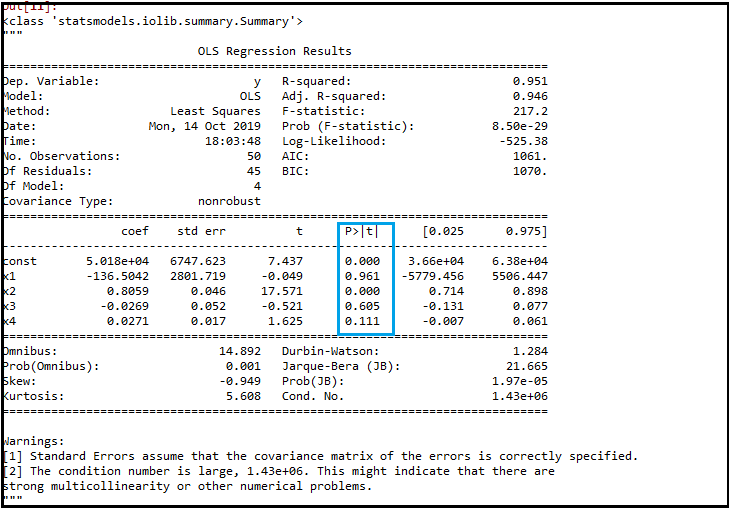
As we can see in the output image, now five variables remain. In these variables, the highest p-value is 0.961. So we will remove it in the next iteration.
Output: 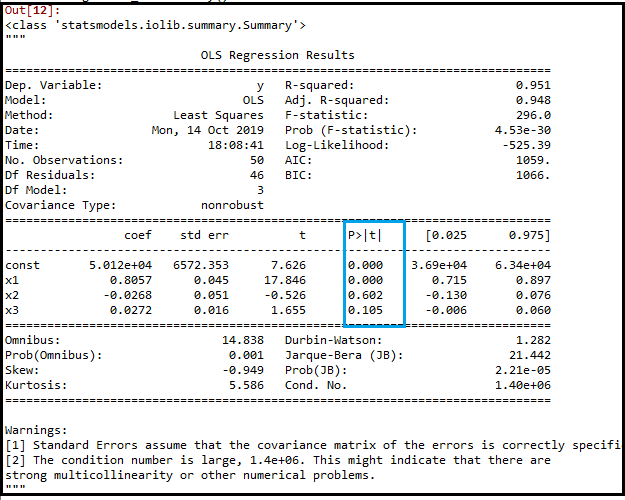
In the above output image, we can see the dummy variable(x2) has been removed. And the next highest value is .602, which is still greater than .5, so we need to remove it.
Output: 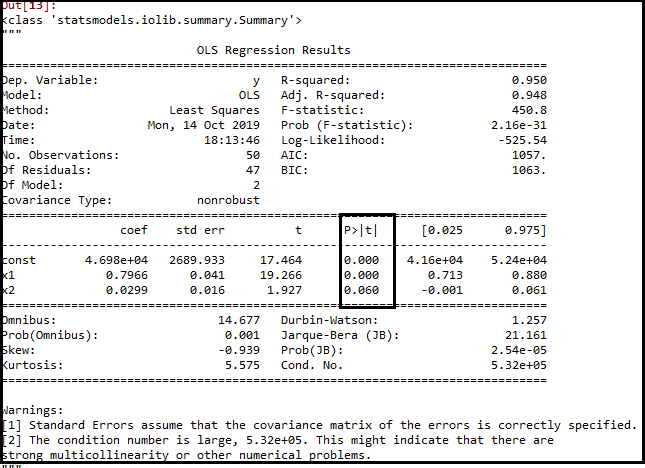
As we can see in the above output image, the variable (Admin spend) has been removed. But still, there is one variable left, which is marketing spend as it has a high p-value (0.60). So we need to remove it.
Output: 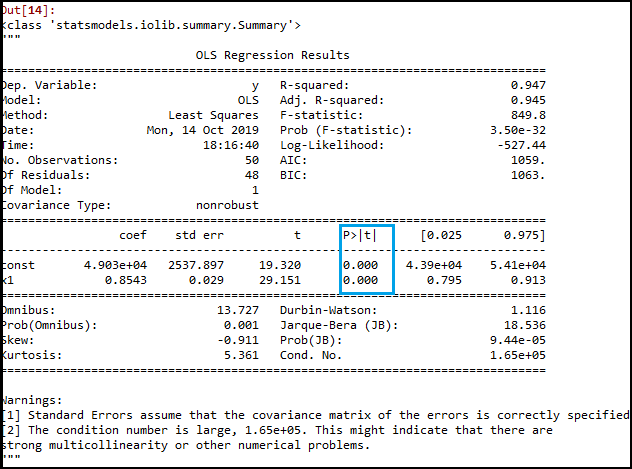
As we can see in the above output image, only two variables are left. So only the R&D independent variable is a significant variable for the prediction. So we can now predict efficiently using this variable. Estimating the performance:In the previous topic, we have calculated the train and test score of the model when we have used all the features variables. Now we will check the score with only one feature variable (R&D spend). Our dataset now looks like: 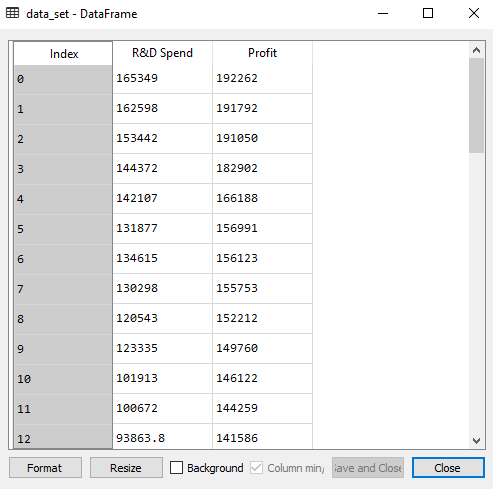
Below is the code for Building Multiple Linear Regression model by only using R&D spend: Output: After executing the above code, we will get the Training and test scores as: Train Score: 0.9449589778363044 Test Score: 0.9464587607787219 As we can see, the training score is 94% accurate, and the test score is also 94% accurate. The difference between both scores is .00149. This score is very much close to the previous score, i.e., 0.0154, where we have included all the variables. We got this result by using one independent variable (R&D spend) only instead of four variables. Hence, now, our model is simple and accurate.
Next TopicMachine Learning Polynomial Regression
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








