| |

How to get datasets for Machine LearningThe field of ML depends vigorously on datasets for preparing models and making precise predictions. Datasets assume a vital part in the progress of AIML projects and are fundamental for turning into a gifted information researcher. In this article, we will investigate the various sorts of datasets utilized in AI and give a definite aid on where to track down them. What is a dataset?A dataset is a collection of data in which data is arranged in some order. A dataset can contain any data from a series of an array to a database table. Below table shows an example of the dataset:
A tabular dataset can be understood as a database table or matrix, where each column corresponds to a particular variable, and each row corresponds to the fields of the dataset. The most supported file type for a tabular dataset is "Comma Separated File," or CSV. But to store a "tree-like data," we can use the JSON file more efficiently. Types of data in datasets
Note: A real-world dataset is of huge size, which is difficult to manage and process at the initial level. Therefore, to practice machine learning algorithms, we can use any dummy dataset.Types of datasetsMachine learning incorporates different domains, each requiring explicit sorts of datasets. A few normal sorts of datasets utilized in machine learning include: Image Datasets:Image datasets contain an assortment of images and are normally utilized in computer vision tasks such as image classification, object detection, and image segmentation. Examples :
Text Datasets:Text datasets comprise textual information, like articles, books, or virtual entertainment posts. These datasets are utilized in NLP techniques like sentiment analysis, text classification, and machine translation. Examples :
Time Series Datasets:Time series datasets include information focuses gathered after some time. They are generally utilized in determining, abnormality location, and pattern examination. Examples :
Tabular Datasets:Tabular datasets are organized information coordinated in tables or calculation sheets. They contain lines addressing examples or tests and segments addressing highlights or qualities. Tabular datasets are utilized for undertakings like relapse and arrangement. The dataset given before in the article is an illustration of a tabular dataset. Need of Dataset
Data Pre-processing:Data pre-processing is a fundamental stage in preparing datasets for machine learning. It includes changing raw data into a configuration reasonable for model training. Normal pre-processing procedures incorporate data cleaning to eliminate irregularities or blunders, standardization to scale data inside a particular reach, highlight scaling to guarantee highlights have comparative ranges, and taking care of missing qualities through ascription or evacuation. During the development of the ML project, the developers completely rely on the datasets. In building ML applications, datasets are divided into two parts:
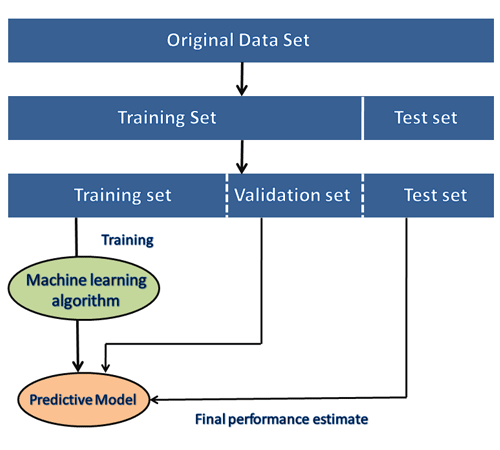
Note: The datasets are of large size, so to download these datasets, you must have fast internet on your computer.Training Dataset and Test Dataset:In machine learning, datasets are ordinarily partitioned into two sections: the training dataset and the test dataset. The training dataset is utilized to prepare the machine learning model, while the test dataset is utilized to assess the model's exhibition. This division surveys the model's capacity, to sum up to inconspicuous data. It is fundamental to guarantee that the datasets are representative of the issue space and appropriately split to stay away from inclination or overfitting. Popular sources for Machine Learning datasetsBelow is the list of datasets which are freely available for the public to work on it: 1. Kaggle Datasets
Kaggle is one of the best sources for providing datasets for Data Scientists and Machine Learners. It allows users to find, download, and publish datasets in an easy way. It also provides the opportunity to work with other machine learning engineers and solve difficult Data Science related tasks. Kaggle provides a high-quality dataset in different formats that we can easily find and download. The link for the Kaggle dataset is https://www.kaggle.com/datasets. 2. UCI Machine Learning RepositoryThe UCI Machine Learning Repository is an important asset that has been broadly utilized by scientists and specialists beginning around 1987. It contains a huge collection of datasets sorted by machine learning tasks such as regression, classification, and clustering. Remarkable datasets in the storehouse incorporate the Iris dataset, Vehicle Assessment dataset, and Poker Hand dataset. 
The link for the UCI machine learning repository is https://archive.ics.uci.edu/ml/index.php. 3. Datasets via AWS
We can search, download, access, and share the datasets that are publicly available via AWS resources. These datasets can be accessed through AWS resources but provided and maintained by different government organizations, researches, businesses, or individuals. Anyone can analyze and build various services using shared data via AWS resources. The shared dataset on cloud helps users to spend more time on data analysis rather than on acquisitions of data. This source provides the various types of datasets with examples and ways to use the dataset. It also provides the search box using which we can search for the required dataset. Anyone can add any dataset or example to the Registry of Open Data on AWS. The link for the resource is https://registry.opendata.aws/. 4. Google's Dataset Search EngineGoogle's Dataset Web index helps scientists find and access important datasets from different sources across the web. It files datasets from areas like sociologies, science, and environmental science. Specialists can utilize catchphrases to find datasets, channel results in light of explicit standards, and access the datasets straightforwardly from the source. 
The link for the Google dataset search engine is https://toolbox.google.com/datasetsearch. 5. Microsoft DatasetsThe Microsoft has launched the "Microsoft Research Open data" repository with the collection of free datasets in various areas such as natural language processing, computer vision, and domain-specific sciences. It gives admittance to assorted and arranged datasets that can be significant for machine learning projects. 
The link to download or use the dataset from this resource is https://msropendata.com/. 6. Awesome Public Dataset Collection
Awesome public dataset collection provides high-quality datasets that are arranged in a well-organized manner within a list according to topics such as Agriculture, Biology, Climate, Complex networks, etc. Most of the datasets are available free, but some may not, so it is better to check the license before downloading the dataset. The link to download the dataset from Awesome public dataset collection is https://github.com/awesomedata/awesome-public-datasets. 7. Government DatasetsThere are different sources to get government-related data. Various countries publish government data for public use collected by them from different departments. The goal of providing these datasets is to increase transparency of government work among the people and to use the data in an innovative approach. Below are some links of government datasets:
8. Computer Vision Datasets
Visual data provides multiple numbers of the great dataset that are specific to computer visions such as Image Classification, Video classification, Image Segmentation, etc. Therefore, if you want to build a project on deep learning or image processing, then you can refer to this source. The link for downloading the dataset from this source is https://www.visualdata.io/. 9. Scikit-learn datasetScikit-learn, a well-known machine learning library in Python, gives a few underlying datasets to practice and trial and error. These datasets are open through the sci-kit-learn Programming interface and can be utilized for learning different machine-learning calculations. Scikit-learn offers both toy datasets, which are little and improved, and genuine world datasets with greater intricacy. Instances of sci-kit-learn datasets incorporate the Iris dataset, the Boston Lodging dataset, and the Wine dataset. 
The link to download datasets from this source is https://scikit-learn.org/stable/datasets/index.html. Data Ethics and Privacy:Data ethics and privacy are basic contemplations in machine learning projects. It is fundamental to guarantee that data is gathered and utilized morally, regarding privacy freedoms and observing pertinent regulations and guidelines. Data experts ought to go to lengths to safeguard data privacy, get appropriate assent, and handle delicate data mindfully. Assets, for example, moral rules and privacy structures can give direction on keeping up with moral practices in data assortment and use. Conclusion:In conclusion, datasets structure the groundwork of effective machine-learning projects. Understanding the various kinds of datasets, the significance of data pre-processing, and the job of training and testing datasets are key stages towards building powerful models. By utilizing well-known sources, for example, Kaggle, UCI Machine Learning Repository, AWS, Google's Dataset Search, Microsoft Datasets, and government datasets, data researchers and specialists can get to an extensive variety of datasets for their machine learning projects. It is fundamental to consider data ethics and privacy all through the whole data lifecycle to guarantee mindful and moral utilization of data. With the right datasets and moral practices, machine learning models can accomplish exact predictions and drive significant bits of knowledge.
Next TopicData Preprocessing
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








