| |

Train and Test datasets in Machine LearningMachine Learning is one of the booming technologies across the world that enables computers/machines to turn a huge amount of data into predictions. However, these predictions highly depend on the quality of the data, and if we are not using the right data for our model, then it will not generate the expected result. In machine learning projects, we generally divide the original dataset into training data and test data. We train our model over a subset of the original dataset, i.e., the training dataset, and then evaluate whether it can generalize well to the new or unseen dataset or test set. Therefore, train and test datasets are the two key concepts of machine learning, where the training dataset is used to fit the model, and the test dataset is used to evaluate the model. In this topic, we are going to discuss train and test datasets along with the difference between both of them. So, let's start with the introduction of the training dataset and test dataset in Machine Learning. What is Training Dataset?The training data is the biggest (in -size) subset of the original dataset, which is used to train or fit the machine learning model. Firstly, the training data is fed to the ML algorithms, which lets them learn how to make predictions for the given task. For example, for training a sentiment analysis model, the training data could be as below:
The training data varies depending on whether we are using Supervised Learning or Unsupervised Learning Algorithms. For Unsupervised learning, the training data contains unlabeled data points, i.e., inputs are not tagged with the corresponding outputs. Models are required to find the patterns from the given training datasets in order to make predictions. On the other hand, for supervised learning, the training data contains labels in order to train the model and make predictions. The type of training data that we provide to the model is highly responsible for the model's accuracy and prediction ability. It means that the better the quality of the training data, the better will be the performance of the model. Training data is approximately more than or equal to 60% of the total data for an ML project. What is Test Dataset?Once we train the model with the training dataset, it's time to test the model with the test dataset. This dataset evaluates the performance of the model and ensures that the model can generalize well with the new or unseen dataset. The test dataset is another subset of original data, which is independent of the training dataset. However, it has some similar types of features and class probability distribution and uses it as a benchmark for model evaluation once the model training is completed. Test data is a well-organized dataset that contains data for each type of scenario for a given problem that the model would be facing when used in the real world. Usually, the test dataset is approximately 20-25% of the total original data for an ML project. At this stage, we can also check and compare the testing accuracy with the training accuracy, which means how accurate our model is with the test dataset against the training dataset. If the accuracy of the model on training data is greater than that on testing data, then the model is said to have overfitting. The testing data should:
Need of Splitting dataset into Train and Test setSplitting the dataset into train and test sets is one of the important parts of data pre-processing, as by doing so, we can improve the performance of our model and hence give better predictability. We can understand it as if we train our model with a training set and then test it with a completely different test dataset, and then our model will not be able to understand the correlations between the features. 
Therefore, if we train and test the model with two different datasets, then it will decrease the performance of the model. Hence it is important to split a dataset into two parts, i.e., train and test set. In this way, we can easily evaluate the performance of our model. Such as, if it performs well with the training data, but does not perform well with the test dataset, then it is estimated that the model may be overfitted. For splitting the dataset, we can use the train_test_split function of scikit-learn. The bellow line of code can be used to split dataset: Explanation: In the first line of the above code, we have imported the train_test_split function from the sklearn library. In the second line, we have used four variables, which are
Overfitting and Underfitting issuesOverfitting and underfitting are the most common problems that occur in the Machine Learning model. A model can be said as overfitted when it performs quite well with the training dataset but does not generalize well with the new or unseen dataset. The issue of overfitting occurs when the model tries to cover all the data points and hence starts caching noises present in the data. Due to this, it can't generalize well to the new dataset. Because of these issues, the accuracy and efficiency of the model degrade. Generally, the complex model has a high chance of overfitting. There are various ways by which we can avoid overfitting in the model, such as Using the Cross-Validation method, early stopping the training, or by regularization, etc. On the other hand, the model is said to be under-fitted when it is not able to capture the underlying trend of the data. It means the model shows poor performance even with the training dataset. In most cases, underfitting issues occur when the model is not perfectly suitable for the problem that we are trying to solve. To avoid the overfitting issue, we can either increase the training time of the model or increase the number of features in the dataset. Training data vs. Testing Data
How do training and testing data work in Machine Learning?Machine Learning algorithms enable the machines to make predictions and solve problems on the basis of past observations or experiences. These experiences or observations an algorithm can take from the training data, which is fed to it. Further, one of the great things about ML algorithms is that they can learn and improve over time on their own, as they are trained with the relevant training data. Once the model is trained enough with the relevant training data, it is tested with the test data. We can understand the whole process of training and testing in three steps, which are as follows:
The above process is explained using a flowchart given below: 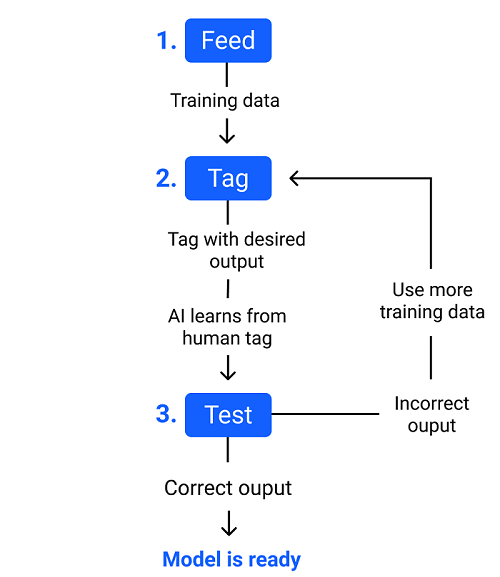
Traits of Quality training dataAs the ability to the prediction of an ML model highly depends on how it has been trained, therefore it is important to train the model with quality data. Further, ML works on the concept of "Garbage In, Garbage Out." It means that whatever type of data we will input into our model, it will make the predictions accordingly. For a quality training data, the below points should be considered: 1. Relevant The very first quality of training data should be relevant to the problem that you are going to solve. It means that whatever data you are using should be relevant to the current problem. For example, if you are building a model to analyze social media data, then data should be taken from different social sites such as Twitter, Facebook, Instagram, etc. 2. Uniform: There should always be uniformity among the features of a dataset. It means all data for a particular problem should be taken from the same source with the same attributes. 3. Consistency: In the dataset, the similar attributes must always correspond to the similar label in order to ensure uniformity in the dataset. 4. Comprehensive: The training data must be large enough to represent sufficient features that you need to train the model in a better way. With a comprehensive dataset, the model will be able to learn all the edge cases. ConclusionGood training data is the backbone of machine learning. It is crucial to understand the importance of good training data in Machine Learning, as it ensures that you have data with the right quality and quantity to train your model. The main difference between training data and testing data is that training data is the subset of original data that is used to train the machine learning model, whereas testing data is used to check the accuracy of the model.
Next TopicHow to Start with Machine Learning
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








