| |

Network Intrusion Detection System Using Machine Learning
Due to the rapid growth of the internet and communication technologies, the domain of network security has emerged as a central area of investigation. This encompasses the application of resources such as firewalls, antivirus software, and intrusion detection systems (IDS) to safeguard the security of networks and their resources within the digital expanse. Within this array of resources, network-based intrusion detection systems (NIDS) hold a critical position, as they continuously monitor network traffic to detect any potentially harmful or questionable actions. The notion of IDS was initially introduced by Jim Anderson in 1980, paving the way for the development of various IDS products to cater to the requirements of network security. Nonetheless, the rapid advancement of technologies has brought about the expansion of networks and the management of vast volumes of data and applications, posing a challenge to secure network nodes and data. Current IDSs have exhibited limitations in recognizing novel attacks and reducing false alarms, which has given rise to a demand for effective and precise NIDS solutions. To meet the demands of a robust IDS, researchers have ventured into the realm of artificial intelligence, specifically machine learning and deep learning techniques. These methods have gained prominence in network security, largely due to the availability of robust graphics processing units (GPUs). ML-based IDS relies on feature engineering to glean insights from network traffic, while DL-based IDS leverages its intricate architecture to autonomously learn intricate patterns from raw data. In the past decade, researchers have proposed solutions based on ML and DL to boost the efficiency of the Network Intrusion Detection System in detecting malicious attacks. However, the escalating network traffic and mounting security threats pose challenges for NIDS to effectively pinpoint intrusions. Application of Network Intrusion Detection System Using Machine LearningUsing Network Intrusion Detection Systems with Machine Learning has a big impact in many areas. These systems, powered by ML, help keep computer networks safe by spotting and stopping possible dangers. This makes sure that networks and important information stay secure. Here are some important ways NIDS using ML can be useful:
Challenges of Network Intrusion Detection System Using Machine LearningNetwork Intrusion Detection Systems (NIDS) using Machine Learning (ML) has a lot of applications and benefits, although it comes with its fair share of challenges that need careful consideration. These challenges include:
About the DatasetThe audit dataset provided comprises a diverse range of intrusions that were simulated within a military network environment. This environment was designed to replicate the conditions of a typical US Air Force LAN, capturing raw TCP/IP dump data. This involved emulating a real network setting and subjecting it to various attack simulations. In this context, a "connection" denotes a sequence of TCP packets occurring between specific time intervals, where data travels between a source and a target IP address following a defined protocol. Each of these connections is classified as either "normal" or as an "attack," with each attack being associated with a particular attack type. Every connection record encompasses approximately 100 bytes of data. For every TCP/IP connection, a set of 41 quantitative and qualitative features is derived from both normal and attack data. These features include 3 qualitative and 38 quantitative attributes. The class variable in the dataset consists of two categories:
Now we will try to predict the Intrusion on the given dataset using various machine learning algorithms. We will also look at their accuracy and try to determine which is better for Intrusion Detection.
Output: 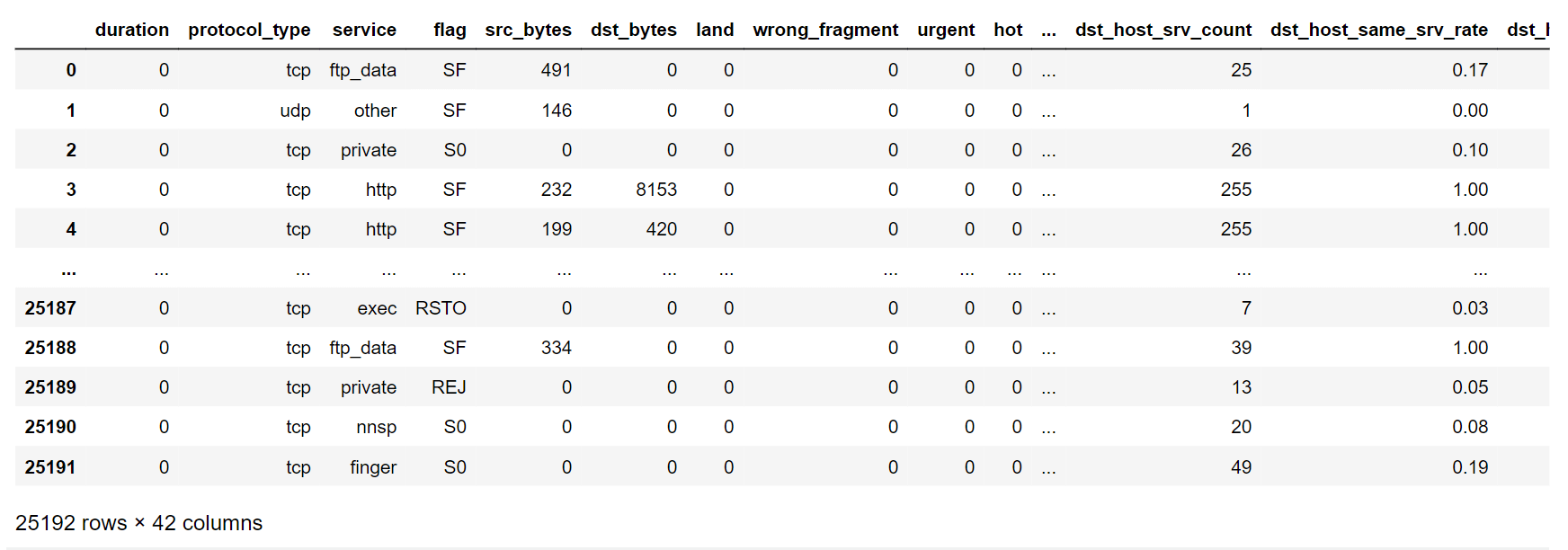
Exploratory Data Analysis (EDA) is a fundamental approach to analyzing data that includes methodically investigating and graphically representing datasets to extract valuable observations and trends. This process encompasses activities such as data profiling, summarizing, and visually representing information in order to grasp the spread, correlations, and features of the data. EDA seeks to pinpoint potential unusual data points, areas where data is absent, and irregularities. It also evaluates the reliability and appropriateness of the data for more advanced analysis or constructing models. Output: 
We have 42 columns and 25192 rows in our dataset. Output: 
Output: 
Output: 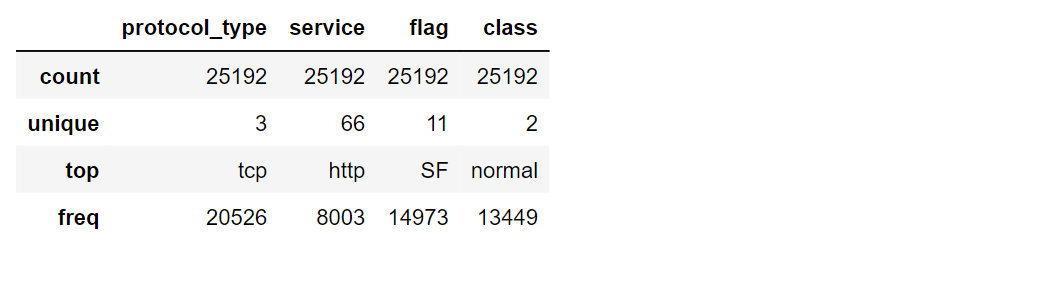
Missing DataThere isn't a single missing value to be found in our dataset. It is one of the remarkable things as it accounts for robust and reliable analyses. Duplicate RowsOutput: 
Again, we don't have any duplicate rows. OutliersOutliers refer to data points that exhibit considerable deviation from the general pattern or trend of the remaining dataset. These data values are notably distant from the larger cluster of other values within a dataset. These outliers have the ability to influence data analysis or model outcomes, often by introducing disturbances or irregularities that do not reflect the usual characteristics of the data. Output: 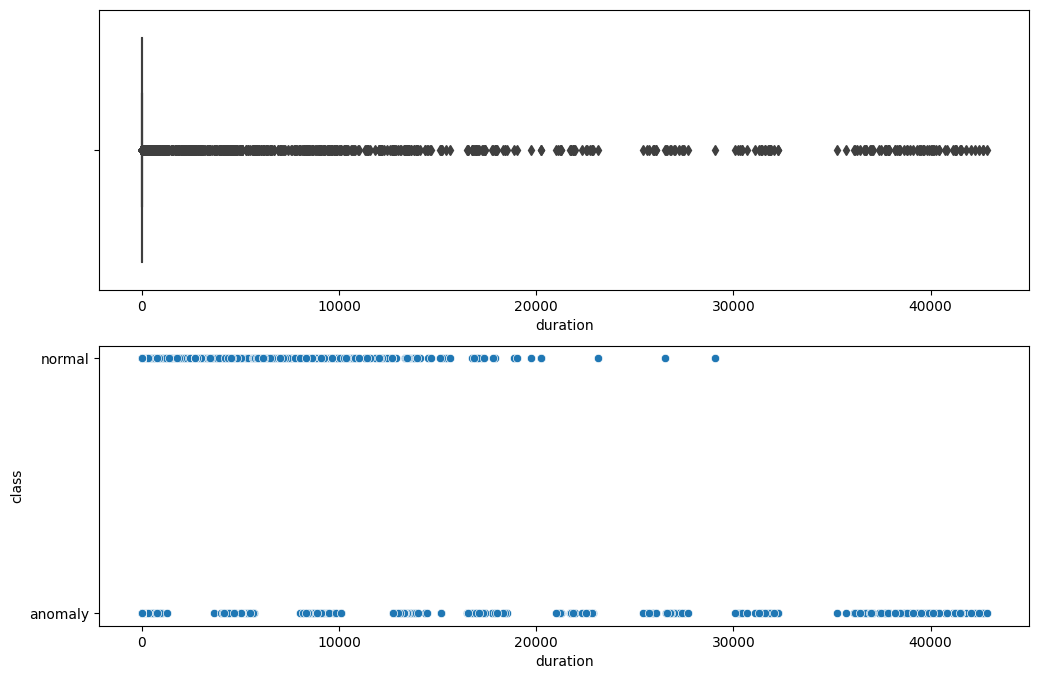
We don't have any outliers throughout the dataset. CorrelationOutput: 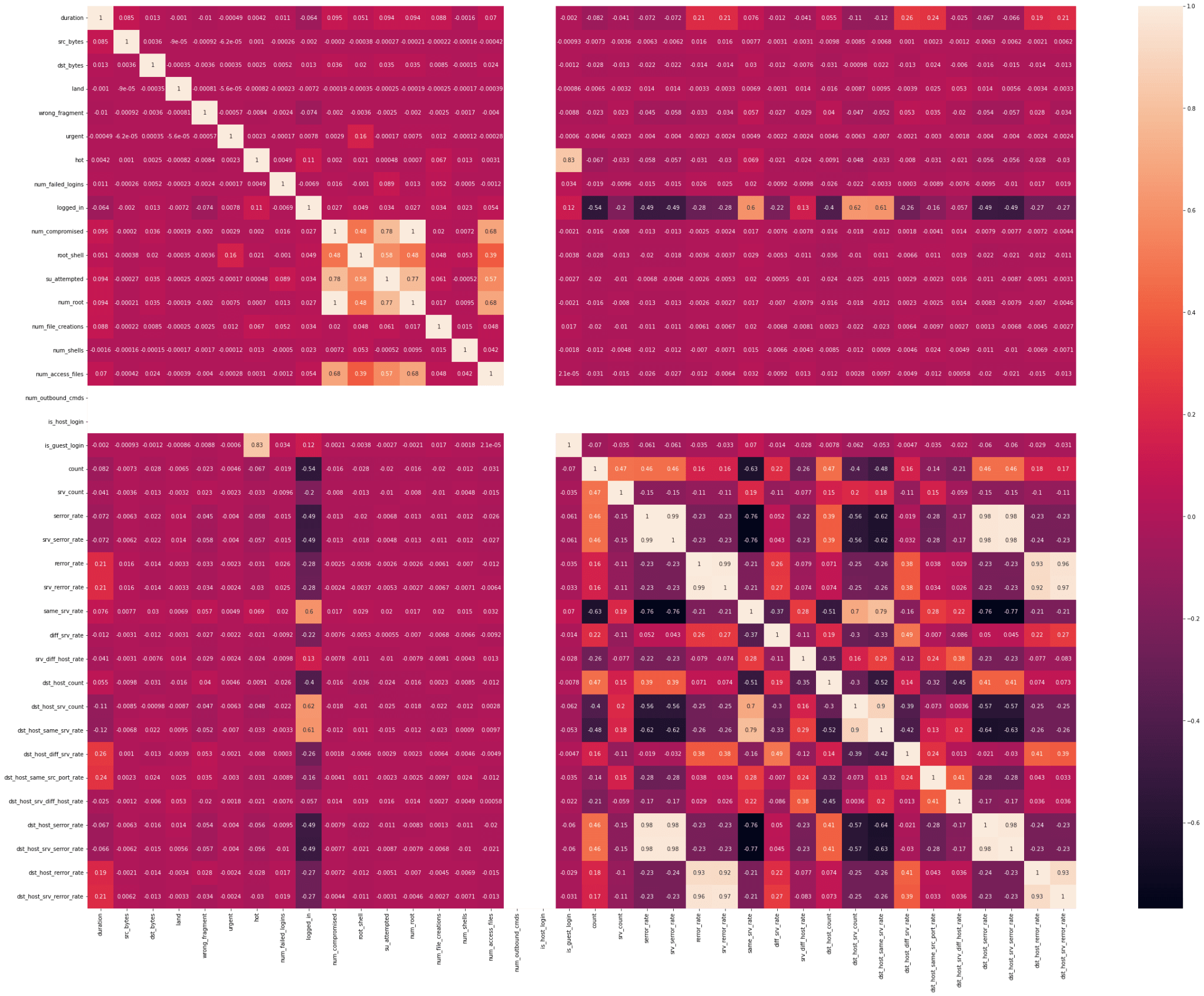
Output: 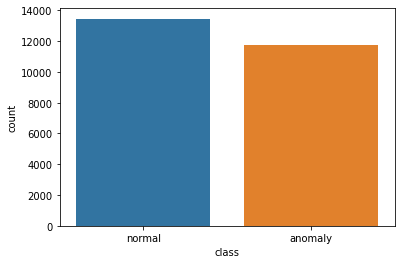
Label EncodingLabel encoding is a technique used when getting data ready for analysis. It changes categories, like types of things, into numbers. Each category gets its own number. This helps computer programs, like those used in machine learning, understand and work with the data, especially when they need numbers to do their calculations. Output: 
Feature selection involves picking out the most meaningful and crucial attributes or factors from a dataset to use in a model or analysis. This streamlines the data, making it less complicated, and enhances the model's effectiveness. By pinpointing the correct features, we can concentrate on the most influential details, which leads to better accuracy and efficiency in our analysis or predictions. We will try to pick the most meaningful attributes, as you already know that we have 42 columns in our dataset at first. Having a large number of attributes decreases the efficiency of the model. Output: 
Above are the relevant features that will be suitable for our models.
Next, we will proceed to train the following model and assess its score on both the Training and Testing datasets:
1. KNN (K Nearest Neighbors) Output: 
Output: 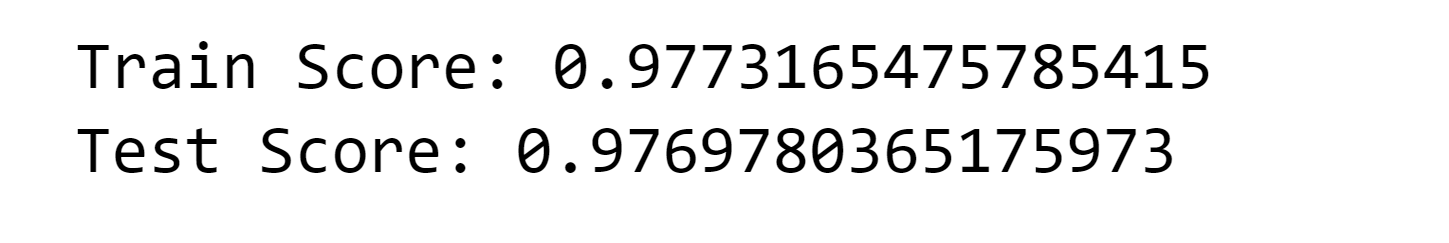
2. Logistic Regression Output: 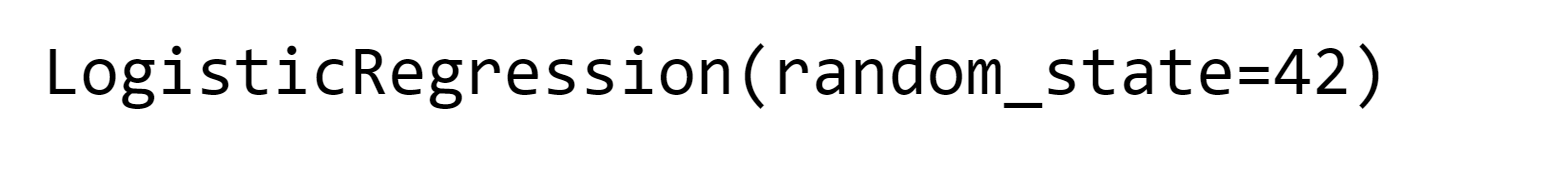
Output: 
3. Decision Tree Classifier Output: 
Output: 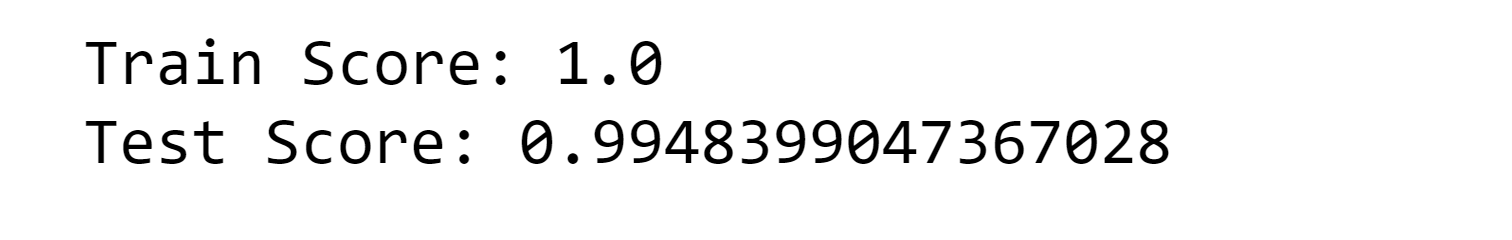
Output: 
Output: 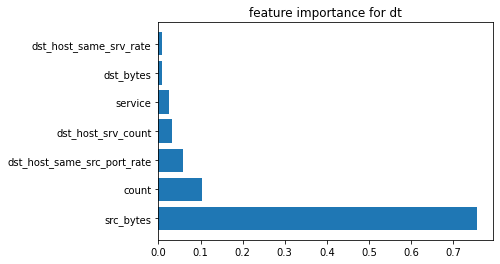
4. Random Forest Classifier Output: 
Output: 
Output: 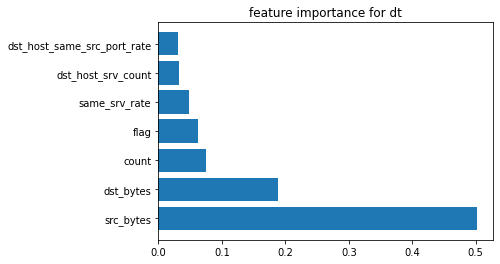
5. SKLearn Gradient Boosting Output: 
Output: 
6. XGBoost Output: 
Output: 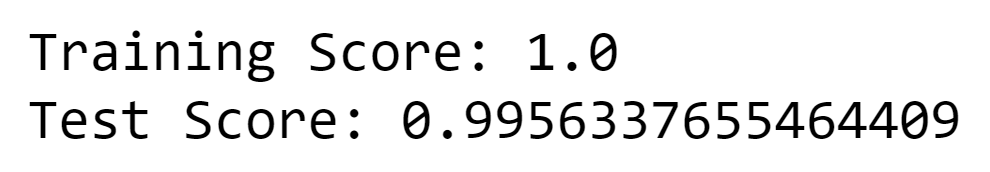
7. Light Gradient Boosting Output: 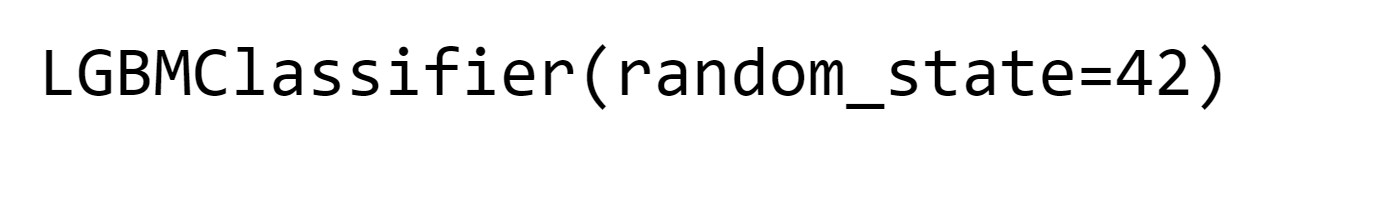
Output: 
8. ADAboost Output: 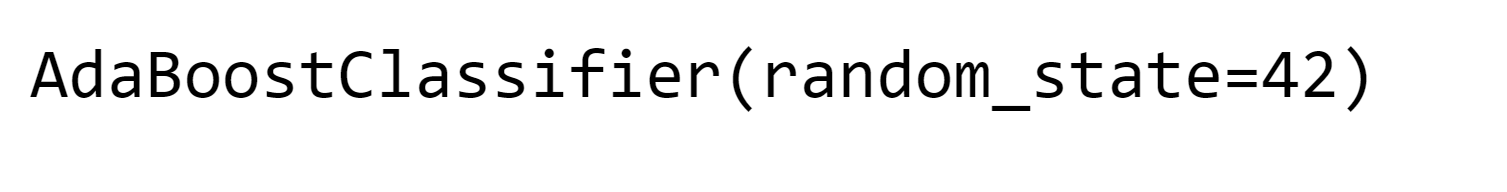
Output: 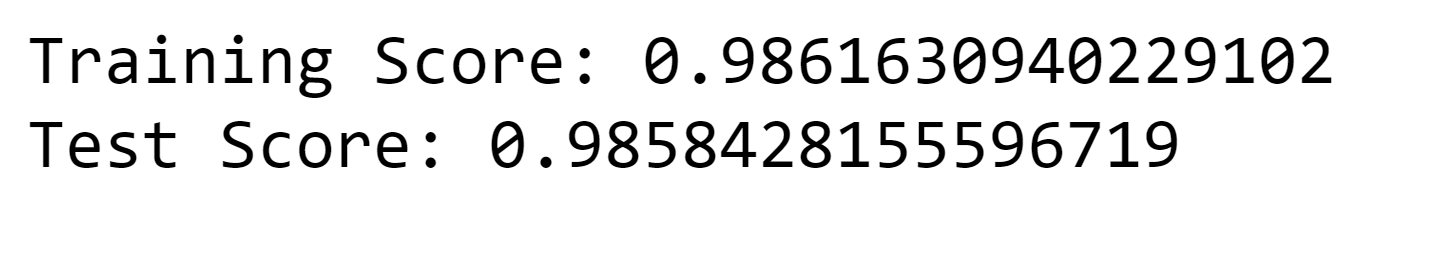
9. Catboost Output: 
Output: 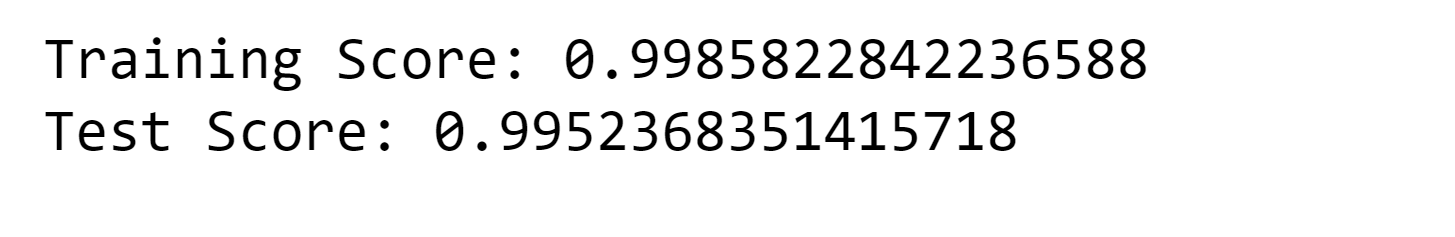
10. Naive Bayes Output: 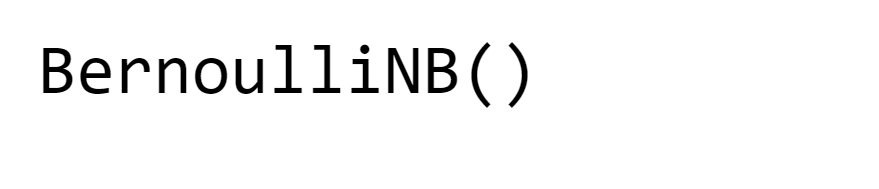
Output: 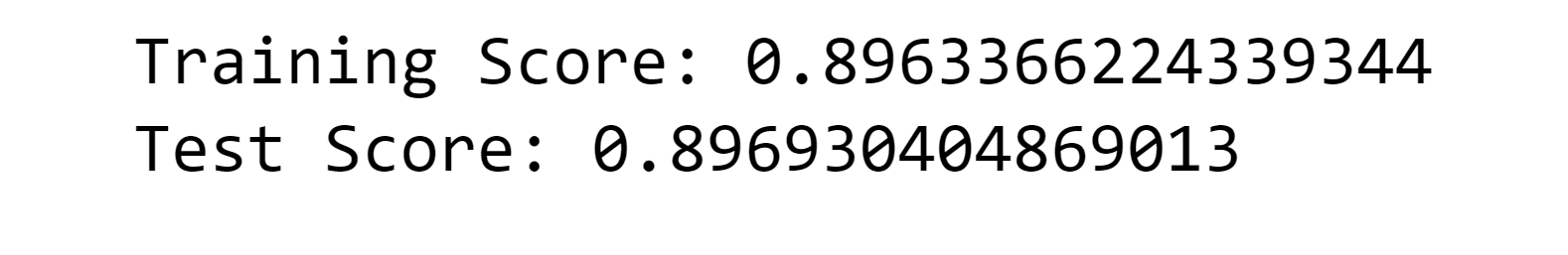
11. Voting Model Output: 
Output: 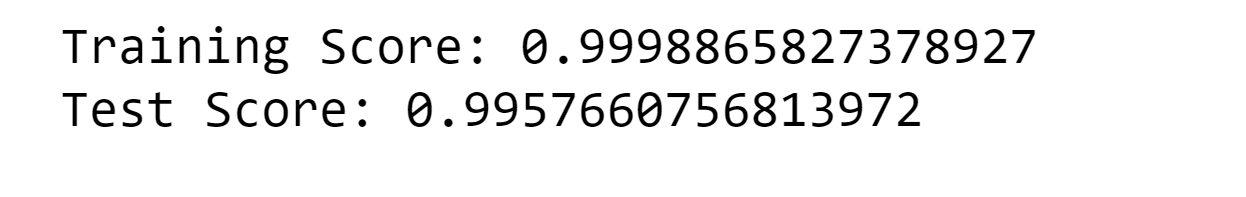
12. SVM Output: 
Output: 
Output: 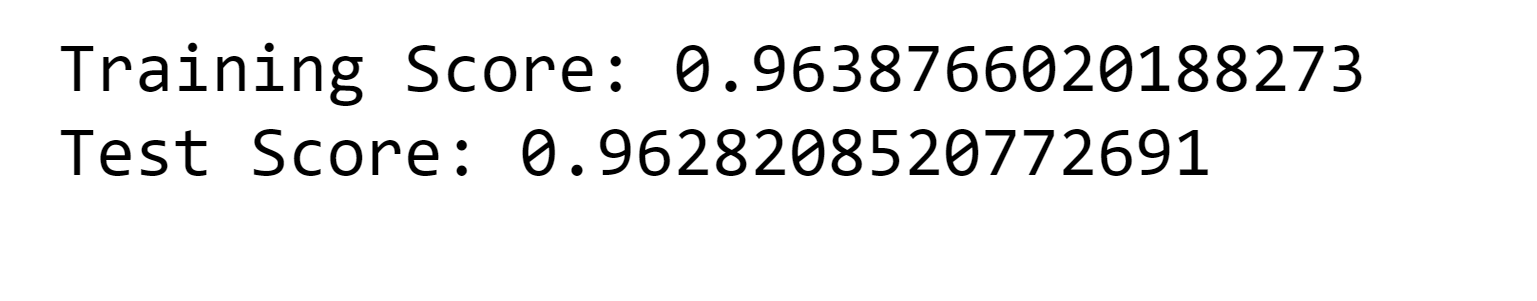
Model SelectionNow we will look at all the model scores of the models that we used, and select the model Output: 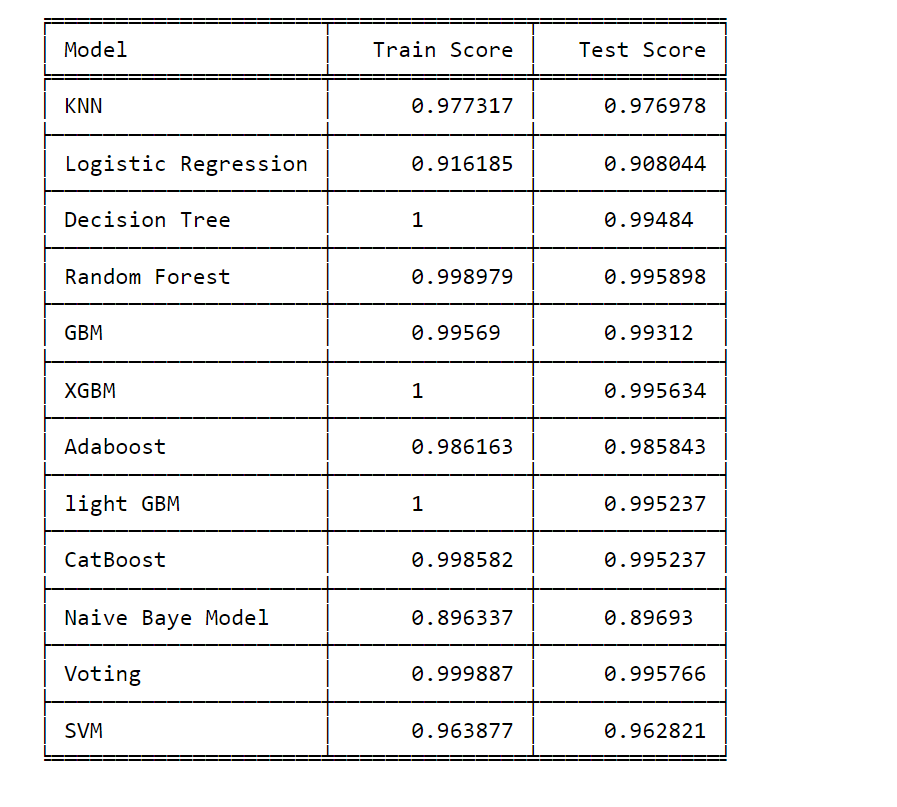
As we see, almost all the models have a high accuracy. So as per intuition, we can choose the model for further practice. It is recommended to use Ensemble methods like Random Forest, Gradient Boosting, and Voting to use ensemble techniques that combine multiple models for improved performance. They can often handle complex relationships in data effectively. If you want an easier interpretability model, then Decision Trees are easy to interpret and visualize, which might be beneficial for understanding the intrusion detection process. Logistic Regression and Naive Bayes are also relatively interpretable models. Over the High Dimension Data, we can use SVM. Future Aspects of Network Intrusion Detection System Using Machine LearningThe future of Network Intrusion Detection Systems (NIDS) paired with Machine Learning holds great promise. As NIDS models advance, they will become more adaptable in detecting emerging threats and attacks. The concept of transfer learning will speed up the sharing of knowledge, making detection even better. The ability to identify unusual activities (anomalies) will become more precise, even when they're subtle. Quick analysis in real-time will help respond faster to threats. By bringing together different types of data, a more complete picture of potential dangers will be possible. Making sure the models' decisions are clear (model interpretability) will be a priority. The collective wisdom of defense systems will work together to counter threats. Using AI, responses to incidents will be automated. Detailed analysis will provide a more nuanced understanding of threats. Concerns about privacy will be addressed using methods that protect sensitive information. Ongoing learning and the integration of advanced computing (like quantum computing) will make NIDS even stronger. In summary, NIDS powered by Machine Learning will evolve using new methods, teamwork, and automation to improve cybersecurity. ConclusionNetwork Intrusion Detection Systems using Machine Learning represent a paradigm shift in cybersecurity. As threats become more advanced, NIDS must evolve to match their sophistication. Machine Learning equips NIDS with the adaptability, accuracy, and real-time capabilities necessary to effectively combat modern cyber threats. While challenges persist, the future holds the promise of even more advanced techniques and collaborative approaches to ensure the security of our digital landscapes. With NIDS leveraging Machine Learning, organizations can confidently navigate the complex and ever-changing landscape of cybersecurity.
Next TopicTitanic- Machine Learning From Disaster
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








