| |

Dask PythonIn the modern world of machine learning and data science, it is surprisingly easy to reach distinctive Python Tools. These Packages include scikit-learn, NumPy, or Pandas that do not scale appropriately with the data in memory usage or processing time. It is an expected point to move to a distributed computing tool (traditionally, Apache Spark). However, it can imply that to retool the workflow for a whole new system, navigate between the familiar ecosystem of Python and a different Java Virtual Machine (JVM) world, and significantly complicate the development workflow. The Dask library is used to join the distributed computing power with the flexibility of Python development for data science, with seamless integration to standard data tools of Python. Understanding Distributed ComputingLet us consider a scenario: We have a dataset, perhaps a group of text files that is very large in order to fit into the machine's memory. We can utilize the file streaming in Python and another generator tooling for iterating through the dataset without loading them into the memory. However, another problem will raise because the program is still working on the single thread that eventually limits the speed even after the memory management. Therefore, Python provides a safety feature known as the Global Interpreter Look (in other words, most developers use CPython) to write parallel code in Python, but it can be a bit tricky. Thus, there are few good choices of solutions available. Such solutions involve using the lower-level tools outside the GIL (such as NumPy performing multithreaded heavy lifting in compiled code other than Python) or utilizing multiple processes/ threads from within Python code packages such as multiprocessing or joblib. However, it becomes difficult to try parallelization in order to speed up the code and as a result, even when the process is done correctly, in less readable code that needs the developers to entirely re-architect the process but can have the limited resources on the system. For actually large-scale difficulties like the above, the distributed computing can be considered as a prevailing key. The work is distributed to multiple independent worker machines in a distributed system instead of merely trying to work in multiple threads on a single device. These autonomous worker machines handle chunks of the dataset on its processors and in its disk space or memory. These worker machines communicate with each other only or a central schedule through relatively simple messaging instead of sharing disk space and memory like in multithreaded code. Distributed Computing systems also let the developers scale the code on pretty large datasets for running in parallel on any number of workers in exchange for the complexity of the design to set up the centralized scheduler and keep workers entirely separate from each of them. Let us understand what Dask is and how it works. Understanding DaskDask is a free and open-source library developed and designed in coordination with other community projects such as Pandas, NumPy, and scikit-learn. It is a parallel computing library that distributes more extensive computations and breaks them down into more minor calculations via the task workers and task scheduler. Dask library provides distributed parallel and multi-core execution on datasets more enormous than the size of the memory. Dask provides different utilities through its Low-level Schedulers and High-level Collections.
The use cases of Dask offer several sample workflows where Dask can be considered as a perfect fit. Types of Dask SchedulersThere are mainly two types of schedulers that Dask offers: Single Machine Scheduler and Distributed Scheduler.
It is recommended to utilize the Distributed Scheduler for most cases as it provides an accommodating and interactive dashboard consisting of multiples tables and plots with live information. By default, it is available at port 8787 while initializing the cluster. Before we get into the installation part, let us understand Dask Cluster. Understanding Dask ClusterA Cluster is a distributed or parallel processing system containing a set of interconnected stand-alone computers that supportively function together as a single, integrated computing resource. A node in the cluster can be considered a single or multiprocessor system, like Personal Computer (PC), workstation, or even SMP. 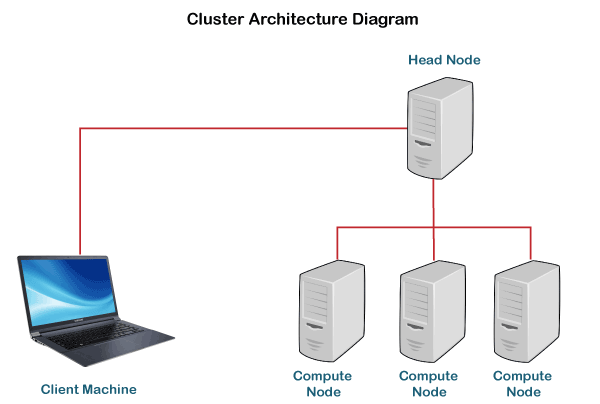
There are various architecture forms available in the world of clusters in order to decide how we can divide the work exactly amongst the computers. Let us understand how the organization of Clusters is done in Dask. The Dask networks have consisted of three segments:
The client would send the request to the schedule describing the kind of code for computation. Once the request is received, the Scheduler divides the work among the workers in order to fulfill the request, and at last, the workers complete the calculation work. 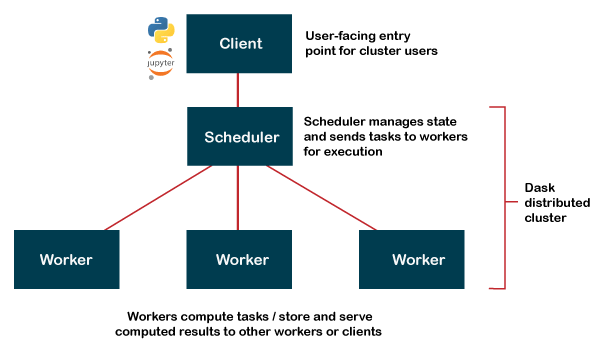
As we can observe, Dask divides these extensive data calculations into multiple minor computations. It is also worth noticing that Dask is deployable too on various technologies based on the cluster, such as:
How to Install Dask PythonWe can either use Anaconda or pip in order to install Dask. The syntax for the installation of Dask through Anaconda is as follows: OR We can simply use the following command in the terminal or command prompt to install Dask through pip: Once we have installed the Dask library successfully, let us understand the Dask Interface. Understanding Dask InterfaceDask offers different user interfaces. These interfaces contain a different set of parallel algorithms for distributed computing. Some of the significant user interfaces are stated below for the practitioners of data science searching to scale NumPy, Pandas, and scikit-learn.
Dask Arrays Arrays in Dask offer a larger-than-memory, parallel, and n-dimensional array with the help of the blocked algorithms. In other terms, it is distributed form of NumPy Arrays. Here is an image that will help us understand how a Dask array looks like: 
As we can observe, multiple numbers of NumPy Arrays are organized into grids in order to form a Dask Array. When we create a Dask Array, we can stipulate the size of the chuck, which defines the size of the NumPy Arrays. For example, if we have ten values in an array and have provided the chunk size as five, it will return two NumPy Arrays with five values each. Dask Arrays provide some of the significant features described below:
Here are some simple cases to create Arrays using Dask. Example 1: Creating a random array with the help of Dask Array Output: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15] ((5, 5, 5, 1),) Explanation: In the above program, we have imported the array module from the dask library and used the arange() method to create an array of 16 values and defined the chunk size to be 5, respectively. We have then used the compute() method to print the array. We have also checked the size of each chunk using the chunks function. As a result, we have the resultant array, and we can also observe that the array is distributed in four chunks, where the first, second, and third blocks contain five value each, and the fourth one has only one value. Example 2: Converting NumPy Array into Dask Array Output: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14] Explanation: In the above example, we have imported the NumPy library and the array module of the dask library. We have then created a NumPy array of 15 values as first_array using the arange() method. We have then converted the first_array into the Dask Array as second_array using the from_array() method by defining the chunks as 5, respectively. We have then used the compute() function to print the Array. Moreover, Dask Array supports most of the functions of the NumPy Array. For example, we can use mean(), sum(), and a lot more. Example 3: Calculating the sum of the first 100 numbers Output: 4950 Explanation: In the above example, we have imported the NumPy library and the array module of the Dask library and created a NumPy array ranging from 1 to 100 using the arange function. We have then converted the NumPy Array into Dask Array and print the sum of the Dask Array values using the sum() function. As a result, we have the total sum of the first 100 numbers. We have discussed a basic introduction of Dask Python, but there are few important concepts that are yet to be discussed. The rest of the tutorial will be covered in the second part.
Next TopicMode in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








