| |

Dask Python (Part 2)In the previous tutorial, we have understood the concept of Distributed Computing and Introduction to Dask. We have also understood what Dask Cluster is and how to install Dask in addition to the introduction to the Dask Interface. Dask InterfaceAs we have already discussed, Dask Interfaces have a variety of parallel algorithm set for distributed computation. Few essential user interfaces are being used by Data Science Practitioners to scale NumPy, Pandas, and scikit-learn:
We have already covered Dask Array in the previous tutorial; let us head straight into Dask DataFrames. Dask DataFramesWe have observed that it requires grouping multiple NumPy Arrays in order to form a Dask Array. Similarly, a Dask DataFrame contains numerous smaller Pandas DataFrames. A large DataFrame of Pandas separates row-wise in order to form multiple smaller DataFrames. These Smaller DataFrames are available on a Single System or Multiple Systems (Hence, allowing us to store Datasets that are larger compared with the memory). Every computation of the Dask DataFrames parallelizes the functions on the prevailing Pandas DataFrames. Here is an image is shown below representing the Dask DataFrame Structure: 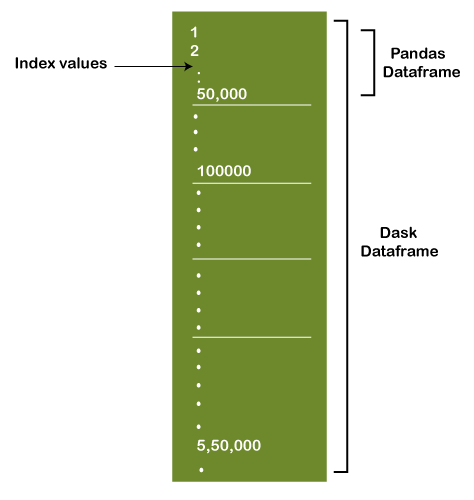
The Dask DataFrames also provides Application Programming Interfaces (APIs) that are pretty identical to Pandas DataFrames offers. Now, let us consider some examples performing the essential functions with Dask DataFrames. Example 1: Reading a CSV file Reading the file with the help of Pandas Output:
Sno Date Time State/UnionTerritory ConfirmedIndianNational ConfirmedForeignNational Cured Deaths Confirmed
0 1 30/01/20 6:00 PM Kerala 1 0 0 0 1
1 2 31/01/20 6:00 PM Kerala 1 0 0 0 1
2 3 01/02/20 6:00 PM Kerala 2 0 0 0 2
3 4 02/02/20 6:00 PM Kerala 3 0 0 0 3
4 5 03/02/20 6:00 PM Kerala 3 0 0 0 3
... ... ... ... ... ... ... ... ... ...
9286 9287 09/12/20 8:00 AM Telengana - - 266120 1480 275261
9287 9288 09/12/20 8:00 AM Tripura - - 32169 373 32945
9288 9289 09/12/20 8:00 AM Uttarakhand - - 72435 1307 79141
9289 9290 09/12/20 8:00 AM Uttar Pradesh - - 528832 7967 558173
9290 9291 09/12/20 8:00 AM West Bengal - - 475425 8820 507995
[9291 rows x 9 columns]
Reading the file with the help of Pandas Output: Sno Date Time State/UnionTerritory ConfirmedIndianNational ConfirmedForeignNational Cured Deaths Confirmed 0 1 30/01/20 6:00 PM Kerala 1 0 0 0 1 1 2 31/01/20 6:00 PM Kerala 1 0 0 0 1 2 3 01/02/20 6:00 PM Kerala 2 0 0 0 2 3 4 02/02/20 6:00 PM Kerala 3 0 0 0 3 4 5 03/02/20 6:00 PM Kerala 3 0 0 0 3 ... ... ... ... ... ... ... ... ... ... 9286 9287 09/12/20 8:00 AM Telengana - - 266120 1480 275261 9287 9288 09/12/20 8:00 AM Tripura - - 32169 373 32945 9288 9289 09/12/20 8:00 AM Uttarakhand - - 72435 1307 79141 9289 9290 09/12/20 8:00 AM Uttar Pradesh - - 528832 7967 558173 9290 9291 09/12/20 8:00 AM West Bengal - - 475425 8820 507995 [9291 rows x 9 columns] Explanation: In the above example, we have created two different programs. In the first program, we have imported the pandas library and use the read_csv() function to read the CSV file. In contrast, we have imported the dataframe module of the dask library and use the read_csv() function to read the CSV file. The result of both the programs will be the same but differ in the processing time. Dask DataFrames deliver faster speed to execute the function when compared with Pandas. The same can be noticeable once practically used. Example 2: Finding the value count for a specific column Output: Kerala 315 Delhi 283 Rajasthan 282 Haryana 281 Uttar Pradesh 281 Tamil Nadu 278 Ladakh 278 Jammu and Kashmir 276 Karnataka 276 Punjab 275 Maharashtra 275 Andhra Pradesh 273 Uttarakhand 270 Odisha 269 West Bengal 267 Puducherry 267 Chhattisgarh 266 Gujarat 265 Chandigarh 265 Madhya Pradesh 264 Himachal Pradesh 264 Bihar 263 Manipur 261 Mizoram 260 Andaman and Nicobar Islands 259 Goa 259 Assam 253 Jharkhand 253 Arunachal Pradesh 251 Tripura 247 Meghalaya 240 Telengana 236 Nagaland 207 Sikkim 200 Dadra and Nagar Haveli and Daman and Diu 181 Cases being reassigned to states 60 Telangana 45 Dadar Nagar Haveli 37 Unassigned 3 Telangana*** 1 Maharashtra*** 1 Telengana*** 1 Chandigarh*** 1 Daman & Diu 1 Punjab*** 1 Name: State, dtype: int64 Explanation: In the above example, we have imported the dataframe module of the dask library and use the read_csv() function in order to read the content from the CSV file. We have then used the name of the column "States" followed by the value_counts() method to count the total numbers of each value present in that specific column. As a result, we got all the state's names present in that column with the total number of their occurrences. Example 3: Using the groupby function on the Dask dataframe Output: State Andaman and Nicobar Islands 4647 Andhra Pradesh 860368 Arunachal Pradesh 15690 Assam 209447 Bihar 232563 Cases being reassigned to states 0 Chandigarh 16981 Chandigarh*** 14381 Chhattisgarh 227158 Dadar Nagar Haveli 2 Dadra and Nagar Haveli and Daman and Diu 3330 Daman & Diu 0 Delhi 565039 Goa 46924 Gujarat 203111 Haryana 232108 Himachal Pradesh 37871 Jammu and Kashmir 107282 Jharkhand 107898 Karnataka 858370 Kerala 582351 Ladakh 8056 Madhya Pradesh 200664 Maharashtra 1737080 Maharashtra*** 1581373 Manipur 23166 Meghalaya 11686 Mizoram 3772 Nagaland 10781 Odisha 316970 Puducherry 36308 Punjab 145093 Punjab*** 130406 Rajasthan 260773 Sikkim 4735 Tamil Nadu 770378 Telangana 41332 Telangana*** 40334 Telengana 266120 Telengana*** 42909 Tripura 32169 Unassigned 0 Uttar Pradesh 528832 Uttarakhand 72435 West Bengal 475425 Name: Cured, dtype: int64 Explanation: In the above program, we have again imported the dataframe module of the dask library and used the read_csv in order to read from the specified CSV file. Then, we have used the groupby function and max() function of the dask dataframe to find the max number of cured people from each state. Now, let us understand another Dask Interface that is Dask Machine Learning. Dask Machine LearningDask Machine Learning offers algorithms for scalable machine learning in Python, which is compatible with scikit-learn. Let us begin with understanding the way of handling the computations using scikit-learn and then have a closer look into how Dask performs these functions in a different way. 
A user can execute parallel computing with the help of scikit-learn (on a solitary system) by placing the parameter njobs = -1. Scikit-learn utilizes Joblib in order to execute these parallel computations. Joblib is a Python library that offers support for parallelization. When we call the fit() function, based on the tasks to be executed (whether it is a hyperparameter search or fitting a model), Joblib distributes the task across the cores available. 
However, we can scale the parallel computation perform with the help of the scikit-learn library to multiple machines. Whereas, Dask performs well on a solitary system as well as can easily be scaled up to a cluster of systems. Dask provides a central task scheduler and a group of workers. The scheduler assigns the tasks to each worker. Then these workers are assigned a number of cores on which they can execute computations. The workers deliver two functions:
Let us consider an example demonstrating the way of conversation between a scheduler and workers (This example has been provided by a developer of Dask, namely Matthew Rocklin): The Central Task Scheduler sends the work in the form of python functions to the workers to execute either on the same system or on a cluster one.
The above example should provide us a clear demonstration about the working of Dask. Now let us understand the models of machine learning and Dask-search CV. Machine Learning ModelsDask Machine Learning (also known as Dask-ML) offers scalable machine learning in Python. But before we get started, let us follow the Dask-ML installation steps given below: Installation using conda Installation using pip Let us move onto understanding Parallelizing Scikit-Learn directly and reimplementing Algorithms using Dask Array. 1. Parallelizing Scikit-Learn Directly As we have already discussed, Scikit-Learn (also known as sklearn) offers parallel computing (on a single CPU) with the help of Joblib. We can directly utilize Dask in order to parallelize more than one sklearn estimators by inserting a few lines of code (without even making any modifications to the current code). The primary step is to import client from the distributed module of the dask library. This command will generate a local schedule and worker on the system. The next step is to instantiate the joblib of the dask in the backend. We have to import the parallel_backend from the joblib of the sklearn library as shown in the following syntax: 2. Reimplementing Algorithms using the Dask Array Dask-ML reimplements simple Machine Learning Algorithms in order to use NumPy Arrays. NumPy arrays are replaced by the Dask using the Dask Arrays in order to achieve Scalable Algorithms. This replacement helps to implement:
A. Linear model example B. Pre-processing example C. Clustering example Dask-Search CVHyperparameter tuning is considered a significant step in building a model and can critically alter the implementation of the model. Models of Machine Learning have various hyperparameters, and it is tough to understand which parameter would perform better in a specific situation. Executing this task manually is considerably tiresome work. However, the Scikit-Learn library offers Gridsearch in order to simplify the task for hyperparameter tuning. The user must provide the parameters, and Gridsearch will offer the best combination of these parameters. Let us consider an example where we need to pick a random forest technique in order to fit the dataset. The model has three significant tunable parameters - First Parameter, Second Parameter, and Third Parameter, respectively. Now, let us set the values for these parameters below: First Parameter - Bootstrap = True Second Parameter - max_depth - [8, 9] Third Parameter - n_estimators : [50, 100 , 200] 1. sklearn Gridsearch: For every parameter combination, Scikit-learn Gridsearch will execute the tasks, sometimes ending up iterating a single task multiple time. A graph is shown below, demonstrating that this is not exactly the most effective method: 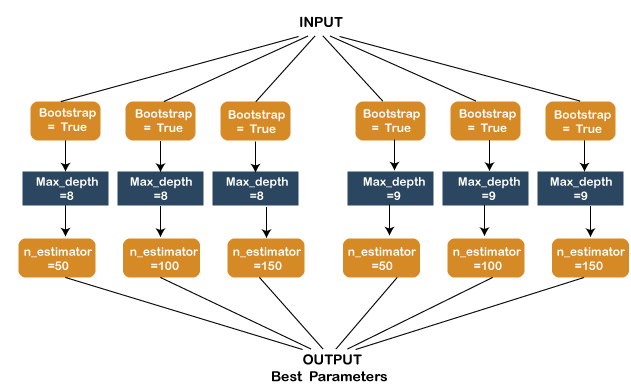
2. Dask-Search CV: In contrast to Gridsearch's CV of sklearn, Dask offers a library known as Dask-Search CV. Dask-Search CV merges the steps in order to reduce repetitions. We can install the Dask-search using the step shown below: Installing Dask-Search CV using conda Installing Dask-Search CV using pip Here is the graph shown below that demonstrates the working of Dask-Search CV: 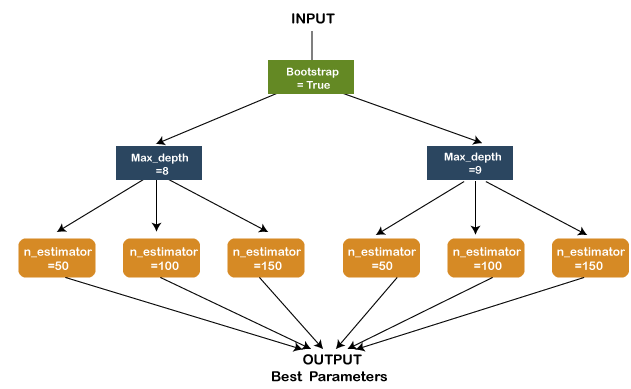
Difference between Spark and DaskHere is a key difference between Spark and Dask:
Next TopicMenu-Driven Programs in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








