| |

Quandl package in PythonIn the following tutorial, we will understand the Quandl package and its use in the Python programming language with some examples. But before we get started, let us understand what Quandl is? Understanding QuandlQuandl is a platform that offers economic, financial, and alternative datasets to its users. Users can download free data, buy paid data or sell data to Quandl. In the following tutorial, we will understand the method of extracting data with the help of the Python programming language. Understanding the Data Structure of QuandlThe data of Quandl comes in two formats: The first being the Time series and the second being the Tables. Remember that some datasets can be available in both formats. The Time series formatTime series data is referred to the data taken over a period of time. The Time series data are generally displayed with the help of line graphs, where the X-axis signifies dates, and the Y-axis signifies the other numeric observations. The format of the Time series only consists of numerical data, which is indexed by one date field. This statement implies that the data is sorted by dates. This format enables users to retrieve the complete time series or a specific section, also known as a "slice". Most datasets of Quandl are stored in the Time series format since the financial data typically contain dates and observations which perfectly fit the format. The Table FormatTables not only consist of numerical values but various unsorted data types like strings, numbers, dates, and many more. We can also filter them into different fields. What is the Quandl ID code?Each feed of data consists of a short ID. This ID is also known as a Quandl code. For instance,
The Time series data like FRED is composed of a large number of individual time series where each of them has its Quandl code added on to the main Quandl code. For example, US civilian unemployment rate: FRED/UNRATE. On the contrary, the Table data like SF1 consist of single or multiple tables where each of them has its Quandl code. For example, the Quandl code for the Core US Fundamentals table is SHARADAR/SF1. Quandl offers a wide range of tools for Data Analysis which includes API, Python, R, Excel, Ruby, and many more. One can find the complete list at https://data.nasdaq.com/tools/full-list. Understanding the Pros and Cons of QuandlThe advantages or Pros of using Quandl are as follows:
The disadvantages or Cons of using Quandl are as follows:
Is Quandl Free?Quandl provides both free and premium products. The Quandl API is free and grants access to all the free datasets. Quandl users are required to pay in order to access the premium data products of Quandl. Understanding the difference between Free and Premium DatasetsQuandl offers a wide range of free products from different "credible and established" sources like Central banks, organizations, government agencies, and many more. On the contrary, the premium products of Quandl come from data providers like Barchart, AlgoSeek, Brave New Coin, Applied Research, CryptoCompare, and many more. One can find the complete list at https://www.quandl.com/publishers. The premium dataset of Quandl has a regular update period. In contrast, there is no guaranteed update period for the free datasets, and they can generally take anywhere ranging from some hours to weeks, months, or even years (depending on the data itself). The premium data of Quandl is developed and managed by professional providers with decades of experience. This all enhances the improvement in documentation, organization, accuracy, distinctiveness, and the structure of the data. In this case, we can observe the supremacy of the premium data. We can purchase the Premium data on Quandl through the subscriptions. With these subscription plans, we can subscribe only to the specific datasets we require. This statement implies that we only have to pay for the data we need. Also, keep in mind that Quandl does not have any fee for utilizing its platform or open data feeds. Most of the premium datasets come with some free sample data. We can access this free sample data by logging in to the Quandl account. Once we click on any premium data feed of our interest, the website will take us to the home page of the feed, where we will be given some sample data. It requires to be mentioned that every single free data feed consists of a transparent link that leads to its source, which means that we can verify the data and the source it comes from. Understanding the types of Free Data in QuandlQuandl provides the users with a wide variety ranging from Prices & Volume, Fundamentals, Derived Metrics, Sentiments, National Statistics, and many others for free data. The following is a list of some free datasets available on the Quandl platform:
Understanding the types of Paid Data in QuandlQuandl offers the users datasets associated with the Estimates, Corporate, Actions, Alternative Data, Technical Analysis, and many others. The following is a list of some premium datasets available on the Quandl platform:
Creating an account in QuandlHaving an account on the Quandl platform is important because of the following reasons:
Let us now get started with the Quandl account. Remember that the registration is free and does not require credit or debit card information. The following are the steps one must follow to register themselves on Quandl: Step 1: Go to the Quandl website (Link: https://data.nasdaq.com/) and click on the 'Sign Up' button in the top right corner. 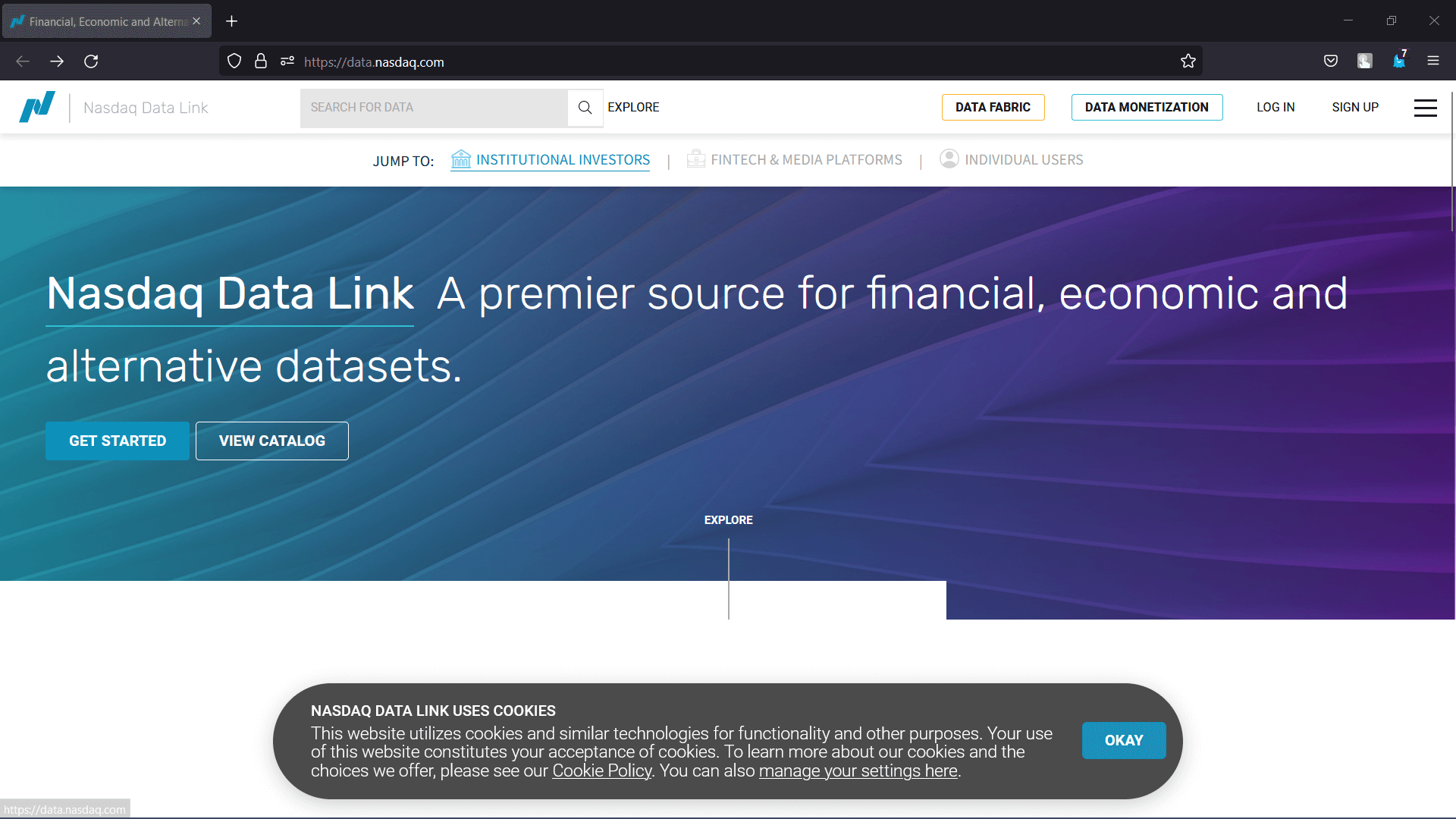
Step 2: A web page will appear for signing up, which requires the user's first and last name along with their purpose of using Quandl or Nasdaq Data Link (Business, Academic or Personal). So, feel free to enter the required details. Once done, click on "Next". 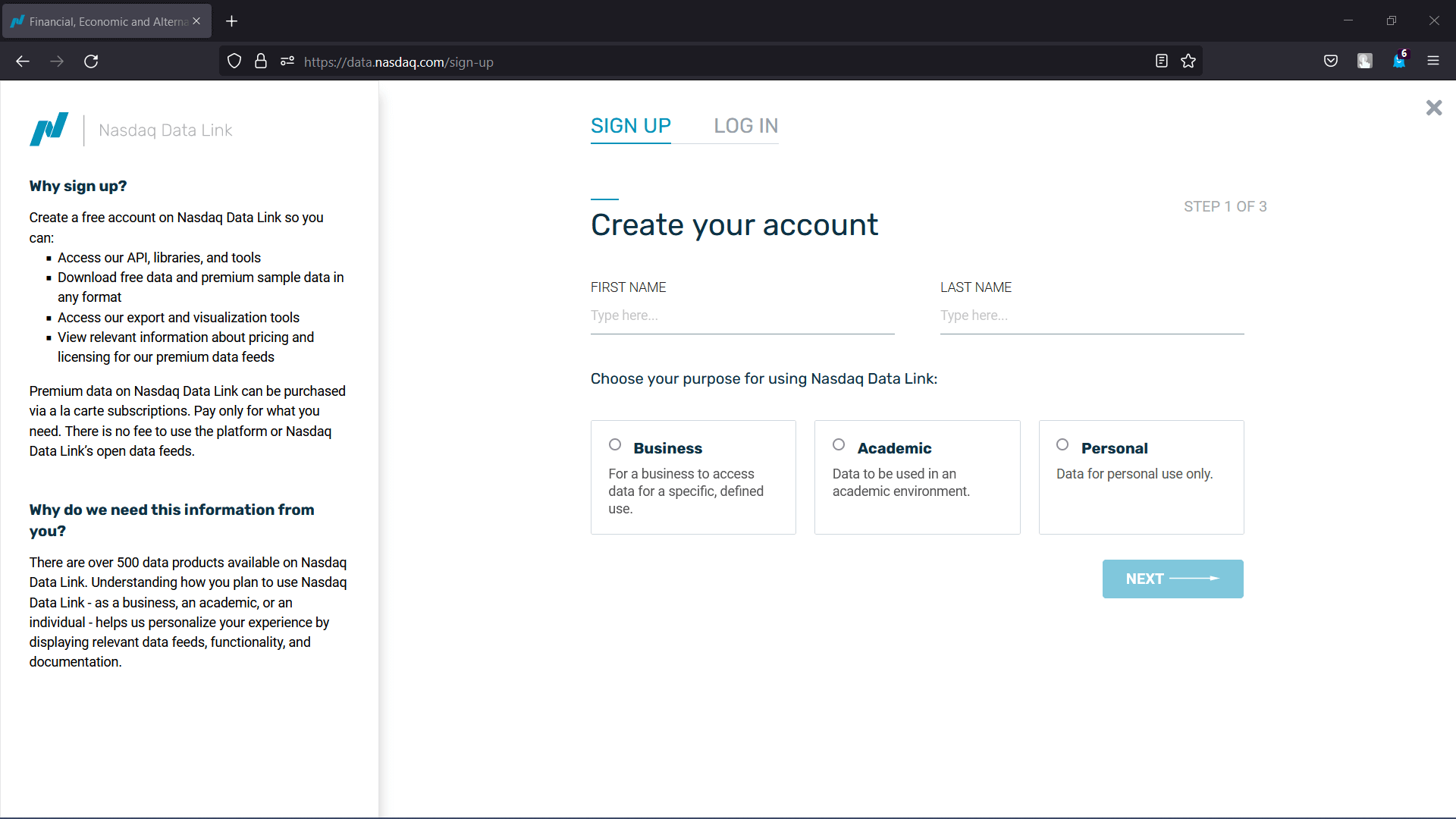
Step 3: Now, another webpage will appear, asking the user to input their email address and country and answer a question on "How will you be using this data?". After filling in the required entries, click on "Next". 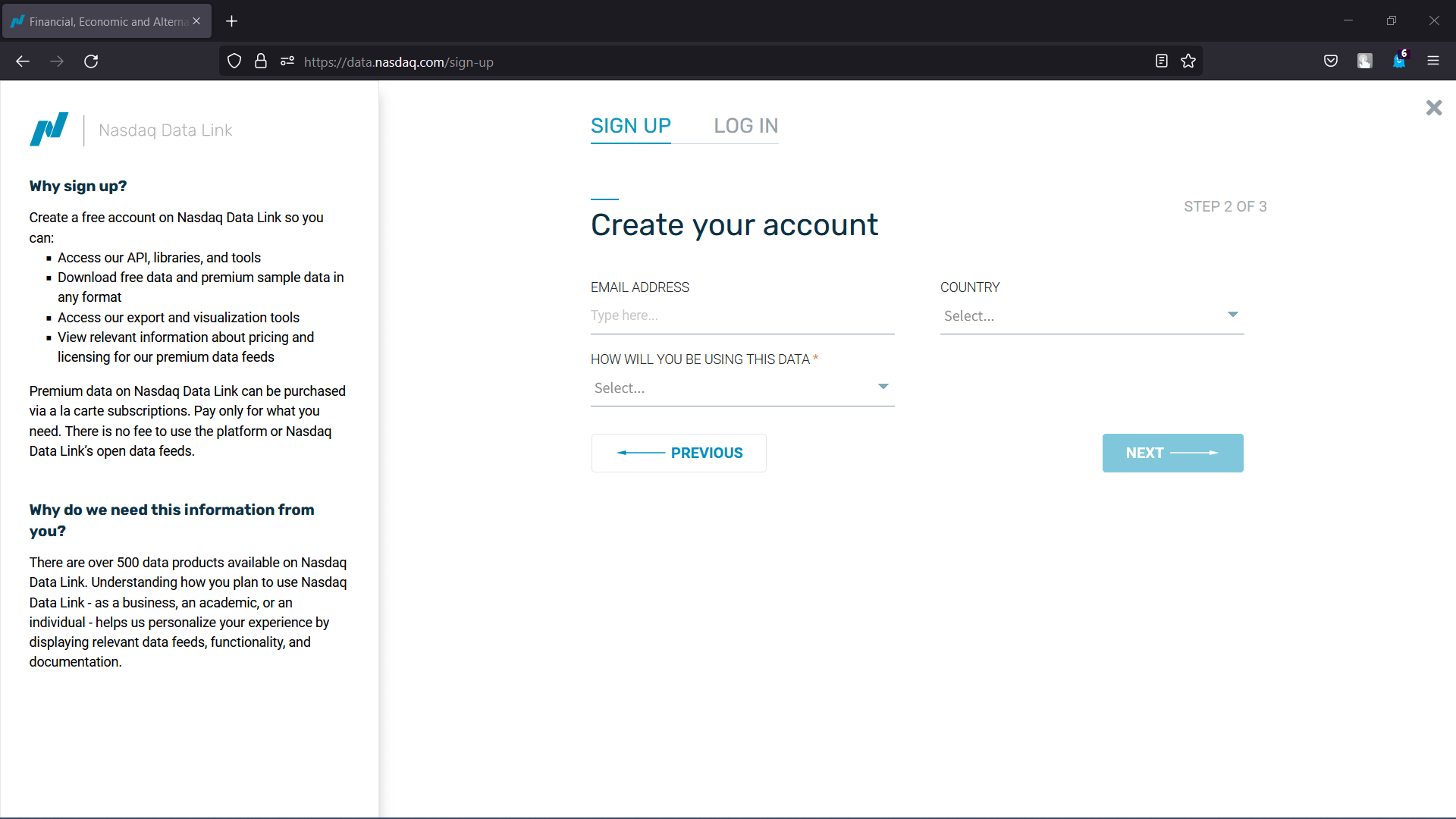
Step 4: The final page of the signing up procedure will appear where the user will be asked to create a password. Once the password is created and checked in terms of service and privacy policy box, click "Create Account". 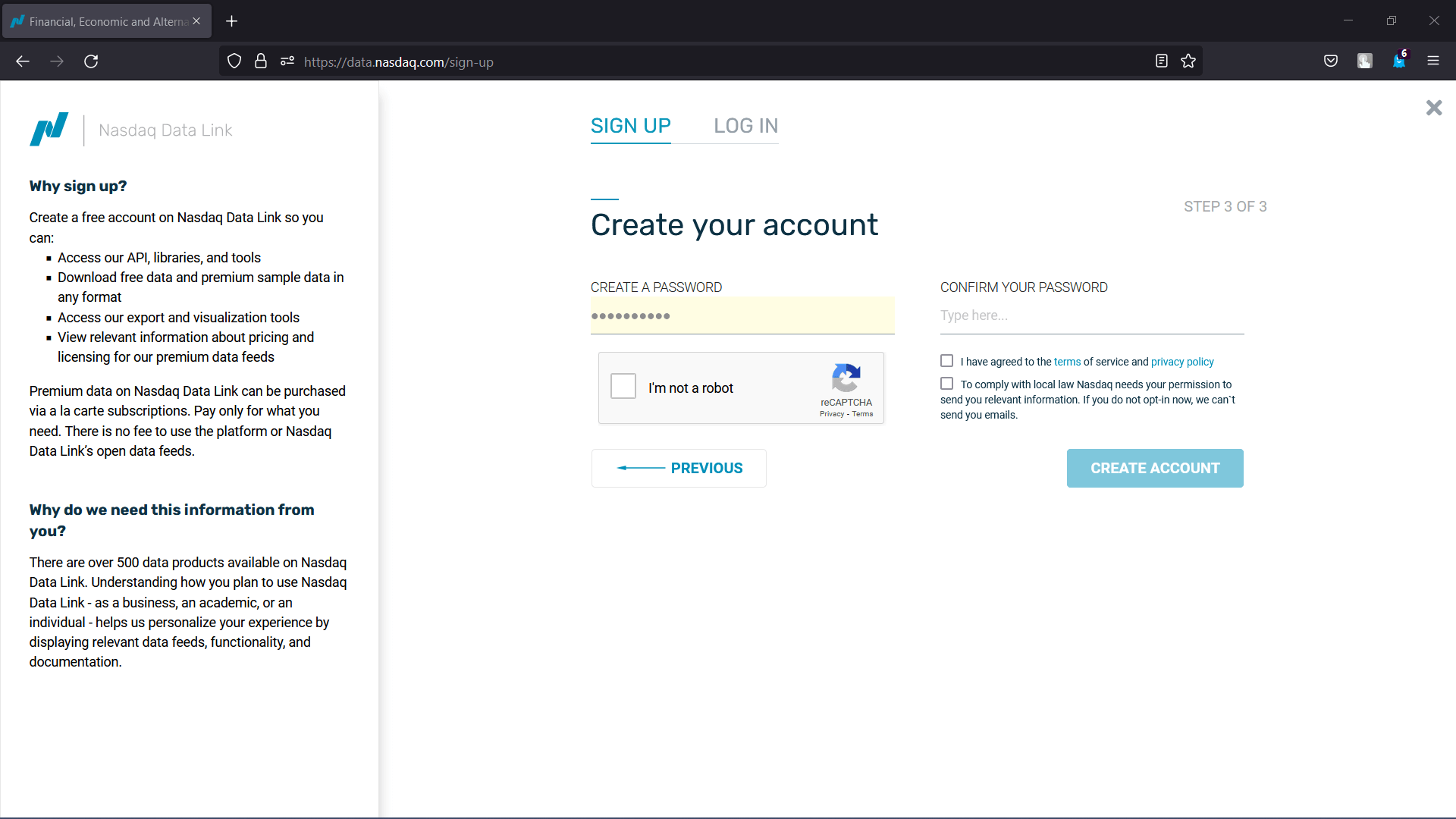
Step 5: Now, a welcome page will appear with the API Key. Make sure to copy this key and verify the email address. 
If anyone pressed "Continue" without copying the API key, it is not an issue. The API key can be found in the Account Details section. 
Now let us understand what an API key is. API key abbreviates for the Application Programming Interface key and is symbolized as a string of code passed by a computer to an application. The application or program then uses the API key to identify the user to a website. The API key is a "secret" authentication token and a unique identifier. We can assume it as the personal secret "password" for collecting data from Quandl. Different Methods to access the Quandl DataWe can access the Quandl Data with the help of Python, Excel, MATLAB, Ruby, R, and many more. In this tutorial, we will be covering the Python method. Extraction of the Quandl Data using PythonThe following section will learn how to extract the Quandl data using the Python programming language. We will use the Visual Studio Code (VS Code) for this section. We will install the Quandl package for Python using the framework known as 'pip'. The 'pip' framework allows programmers to install the packages or modules from the trusted public repositories and manage them. We can use this framework and type the following command in a command prompt (CMD) or terminal: Syntax: Once the package is installed, we can verify it by creating an empty Python program file and writing an import statement as follows: File: verify.py Now, save the above file and execute it using the following command in a terminal: Syntax: If the Python program file does not return any error, the package is installed properly. However, if an exception is raised, try reinstalling the package, and it is also recommended to refer to the official documentation of the package. Let us now understand the use of the Python Quandl package with the help of some examples. Example 1: WTI Crude Oil pricesIn the following example, we need to get the WTI Crude Oil price from the United States Department of Energy. Let us now consider the following snippet of code demonstrating the same: Code: Output:
Value
Date
1986-01-02 25.56
1986-01-03 26.00
1986-01-06 26.53
1986-01-07 25.85
1986-01-08 25.87
... ...
2022-02-02 88.16
2022-02-03 90.17
2022-02-04 92.27
2022-02-07 91.25
2022-02-08 89.32
[9124 rows x 1 columns]
Explanation: We have imported the NumPy, Pandas, and Quandl packages in the above snippet of code. We have then activated the API key using the api_key attribute of the ApiConfig class in the Quandl package. We have then used the get() method of Quandl to extract the data from the database. It is important to know the Quandl code ("ETA/PET_RWTC_D") of each dataset we want to use. One can find these Quandl codes for each dataset under the documentation page of each dataset. For example: https://data.nasdaq.com/data/EIA-us-energy-information-administration-data/documentation. At last, we have printed the data for the user. We can also print this data in the NumPy array. Here is the code illustrating the implementation of the same: Code: Output:
[('1986-01-02T00:00:00.000000000', 25.56)
('1986-01-03T00:00:00.000000000', 26. )
('1986-01-06T00:00:00.000000000', 26.53) ...
('2022-02-04T00:00:00.000000000', 92.27)
('2022-02-07T00:00:00.000000000', 91.25)
('2022-02-08T00:00:00.000000000', 89.32)]
Explanation: In the above snippet of code, we have specified numpy in the returns argument of the quandl.get() method. As a result, the data is printed in the NumPy array format. Example 2: US GDP DataIn the following example, we will download a piece of macroeconomic data with the specific dates and save it as a CSV file. Here is the snippet of code illustrating the same: Code: Output:
Value
Date
2020-01-01 21481.367
2020-04-01 19477.444
2020-07-01 21138.574
2020-10-01 21477.597
2021-01-01 22038.226
2021-04-01 22740.959
2021-07-01 23202.344
2021-10-01 23992.355
Output in CSV file: 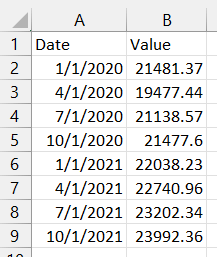
Explanation: In the above snippet of code, we have imported the required packages. We have then activated the API key to access the Quandl data. We then used the quandl.get() method and downloaded the FRED/GDP data and provided the start and end date. We then used the DataFrame() class of the Pandas library to convert this data into the data frame and printed it for the users. At last, we have saved this data frame to a CSV file using the to_csv() method.
Next TopicImplementing Apriori Algorithm in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








