| |

How can Tensorflow be used to pre-process the flower trainingComputer vision has undergone a revolution because of machine learning and deep learning, which allow computers to comprehend and interpret visual data. Preprocessing the training dataset is one of the key processes in creating efficient machine-learning models for image categorization. Google's open-source TensorFlow machine learning framework provides strong tools and methods for quickly creating and enhancing picture datasets. In this article, we will investigate how pre-processing a training dataset of flowers using TensorFlow may be employed in the field of picture classification. Understanding Pre-processingPre-processing is the first step in the pipelines for machine learning. It entails improving and converting unprocessed data into a form appropriate for a machine learning model's training. Pre-processing in the context of picture classification frequently includes actions like scaling photos, standardizing pixel values, and using techniques for data augmentation to broaden the training dataset. The Flower Training DatasetLet's use the problem of classifying flowers as our example. We have a dataset of flower photos of various kinds. The objective is to create a model that can correctly group pictures of flowers into the appropriate categories. The Oxford 102 Flower Dataset and Kaggle's Flower Recognition dataset are two possible sources for this dataset. Using TensorFlow for Pre-processingTensorFlow offers a versatile and user-friendly method for carrying out pre-processing operations on picture collections. Here is how to pre-process the flower training dataset using TensorFlow. 1. Import TensorFlow and Required LibrariesTensorFlow must first be imported, along with any other libraries required for data handling and visualization. These may contain numpy and matplotlib libraries. Code:
2. Loading the DatasetThe flower dataset has to be loaded into your TensorFlow environment as the initial step. The photos may be manually loaded and arranged into the proper folders or utilizing tools like TensorFlow Datasets. Code: Explanation:
3. Data Pre-processing1. Data Augmentation Data augmentation is a crucial technique in pre-processing that helps to diversify the training dataset, reducing overfitting and improving the model's generalization ability. TensorFlow's ImageDataGenerator provides various augmentation options, such as rotation, shifting, and flipping, as demonstrated in the code snippet above. Code: Explanation: The ImageDataGenerator is configured with specific augmentation settings:
2. Loading and Resizing Images in the dataset are often of varying sizes and pixel values. Normalization ensures that pixel values are in a standardized range, making the training process more stable. Resizing images to a consistent size is essential for efficient training and better utilization of computational resources. Code: Explanation:
4. NormalizationNeural networks perform better when input data is standardized. Normalize pixel values to a range between 0 and 1. Code: Explanation:
5. Visualizing Pre-processed DataIt's always a good practice to visualize a few pre-processed images to ensure that the data augmentation and resizing processes are working as expected. Code: Explanation:
Output -: 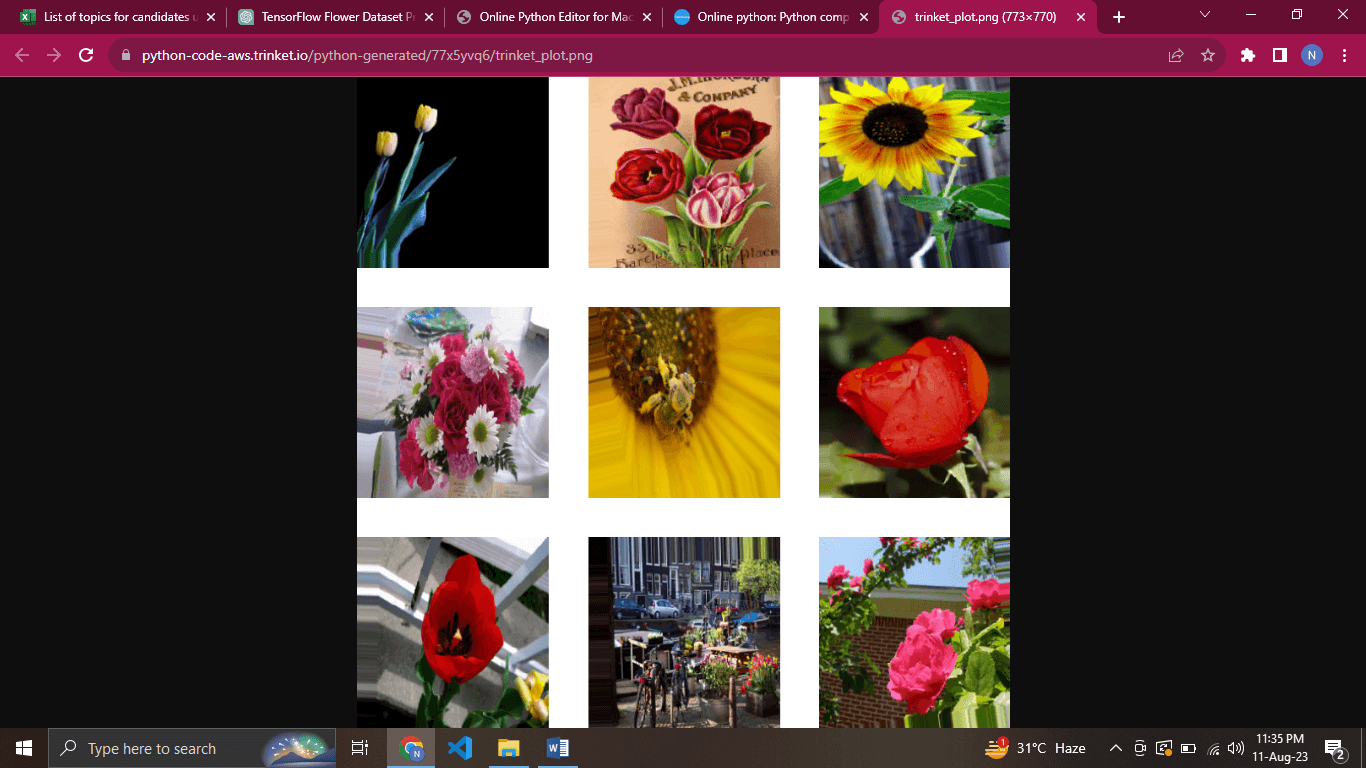
Advantages of TensorFlow:Scalability: TensorFlow's distributed computing capabilities make it suitable for training models on large datasets and across multiple devices or machines. This scalability is crucial when working with resource-intensive tasks. Rich Ecosystem: TensorFlow has a vast and active community that contributes to an ecosystem of libraries, tools, and pre-trained models. This ecosystem can significantly speed up development and experimentation. Visualization: TensorFlow provides tools like TensorBoard for visualizing and monitoring the training process, model architectures, and performance metrics. This aids in debugging and understanding model behavior. Deployment Options: TensorFlow offers various deployment options, including TensorFlow Lite for mobile devices, TensorFlow.js for web browsers, and TensorFlow Serving for production server deployment. This versatility facilitates easy integration of models into different applications. Ease of Experimentation: TensorFlow's high-level APIs, like Keras provide a user-friendly interface for building and training models. This is beneficial for researchers and practitioners who want to quickly prototype and experiment with different architectures. Disadvantages of TensorFlow:Steep Learning Curve: TensorFlow can nevertheless have a challenging learning curve for those unfamiliar with deep learning and machine learning ideas, despite its high-level APIs. The structure itself and the intricacy of neural networks can be intimidating. Verbose Syntax: TensorFlow's low-level operations can sometimes result in verbose code, making it less concise compared to some other frameworks. Version Compatibility: Changes between different versions of TensorFlow can lead to compatibility issues with existing code and models. Migrating between versions might require adjustments to the codebase. Resource Intensive: Training deep learning models can be resource-intensive, especially when using GPUs or TPUs. This might pose challenges for individuals or organizations without access to powerful hardware. Debugging Challenges: Debugging TensorFlow models can be challenging due to the intricate nature of neural networks. Errors might manifest in complex ways, making it difficult to pinpoint the source of the problem. Limited Interpretability: Neural networks, especially deep ones, can be considered "black-box" models, meaning it's often challenging to understand why a model makes specific predictions. This can be a drawback in applications where interpretability is crucial. Competition: While TensorFlow is widely used, there are other powerful frameworks like PyTorch that offer different strengths and advantages. The choice between frameworks might depend on the specific use case and individual preferences. ConclusionTensorFlow provides a comprehensive suite of tools to pre-process image datasets efficiently, making it an essential part of building accurate and robust image classification models. In this article, we've covered how to load, preprocess, and augment a flower training dataset using TensorFlow's ImageDataGenerator. However, pre-processing is not limited to these techniques; depending on your specific dataset and problem, you might need to apply additional transformations. By properly pre-processing your flower training dataset using TensorFlow, you lay the foundation for training a successful image classification model that can accurately identify and classify different flower species. Remember that effective pre-processing enhances the quality of the training data and contributes significantly to the overall performance of your machine learning model. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








