| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Manipulating PDF using PythonIn the previous tutorial, we have discussed various operations that we can perform on a PDF file using different packages and modules of the Python programming language. We have learned the working of different Python libraries which can be used to manipulate PDF files. Moreover, we have understood the extraction of text, images, tables, and URLs using Python. The following tutorial will cover some of the other operations to manipulate a PDF file, including creating a PDF file, adding texts, images, and tables on a PDF file, and a lot more. So, let's get started. Creating a PDF file using PythonPython offers a feature where the programmers could also create a PDF file from the code directly. We can insert texts, images, tables, and forms from Python code directly onto a PDF file. In order to accomplish the same, the Python programming language offers a library known as reportlab. But before we start working with the library, it is necessary for us to install it. Installing the reportlab libraryWe can install the reportlab library using the following command with the pip installer: Syntax: Now, let us begin with the implementation section; we can perform the following: Example: Explanation: In the above snippet of code, we have imported the required functions from their respective modules. We have then created a PDF file called newfile.pdf. Within the Canvas() function, we have set the size of the PDF page to a LETTER size which is a predefined size provided by the reportlab library. We have then saved the created PDF file using the save() function. Adding Text on a PDF using PythonWe can easily add a PDF file with the help of the reportlab library. Let us consider the following example to understand the same: Example: Output: 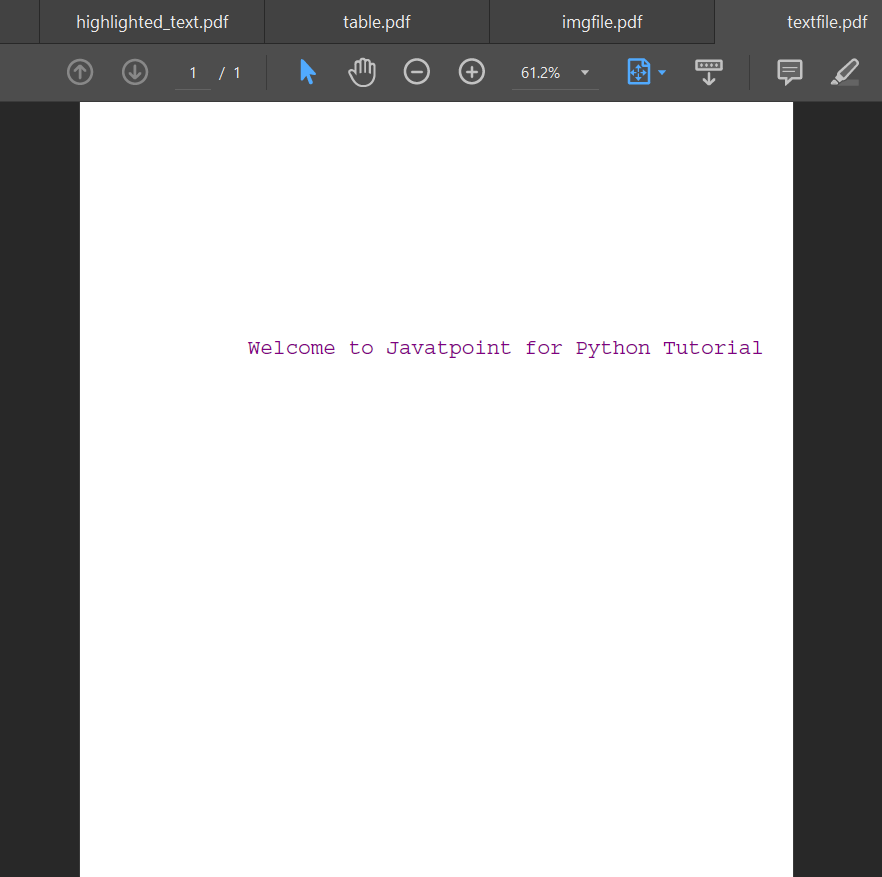
Explanation: In the above snippet of code, we have again imported the functions from their respective modules. We have then created a PDF file named textfile.py. We are setting up the fonts and font sizes since we are about to write some text on the PDF file. We have set the PDF size to LETTER, fonts to Courier, and the font size to 18 with the help of predefined functions of reportlab. We have then chosen the purple color for the text with the help of setFillColor function. After this, we have written some text on the PDF file specifying the position of text on the PDF page. At last, we have saved the created PDF file using the save() function. Hence, we have successfully created a PDF file. Adding Image on a PDF using PythonWe can utilize the Python reportlab library in order to insert images on a PDF file as well. Insertion of images can be tedious work as compared to the insertion of texts on a PDF file. Images have their unique sizes and so do PDF files. Thus, managing the size and finding the optimal location for images can be a tedious job. Let us consider the following example to understand the addition of images on a PDF file: Example: Output: 
Explanation: In the above snippet of code, we have imported the required functions. We have then used the Canvas() function to create a new PDF file. We have then used the drawInlineImage() function in order to insert an image to the created PDF file. We have specified the location of the image in the directory along with the position of the image, i.e., (100, 450) to be set on the PDF file. The reportlab library considers the bottom left position of the PDF file as (0, 0) accordingly and manages the position of the image in a similar way. The letter size PDF has the dimension of 612x792, and (100, 450) will be the location of the image on the PDF file. Adding Tables on a PDF using PythonWe can also add tables to the PDF file using the reportlab library. Let us consider the following example to understand the addition of tables on a PDF file. Example: Output: 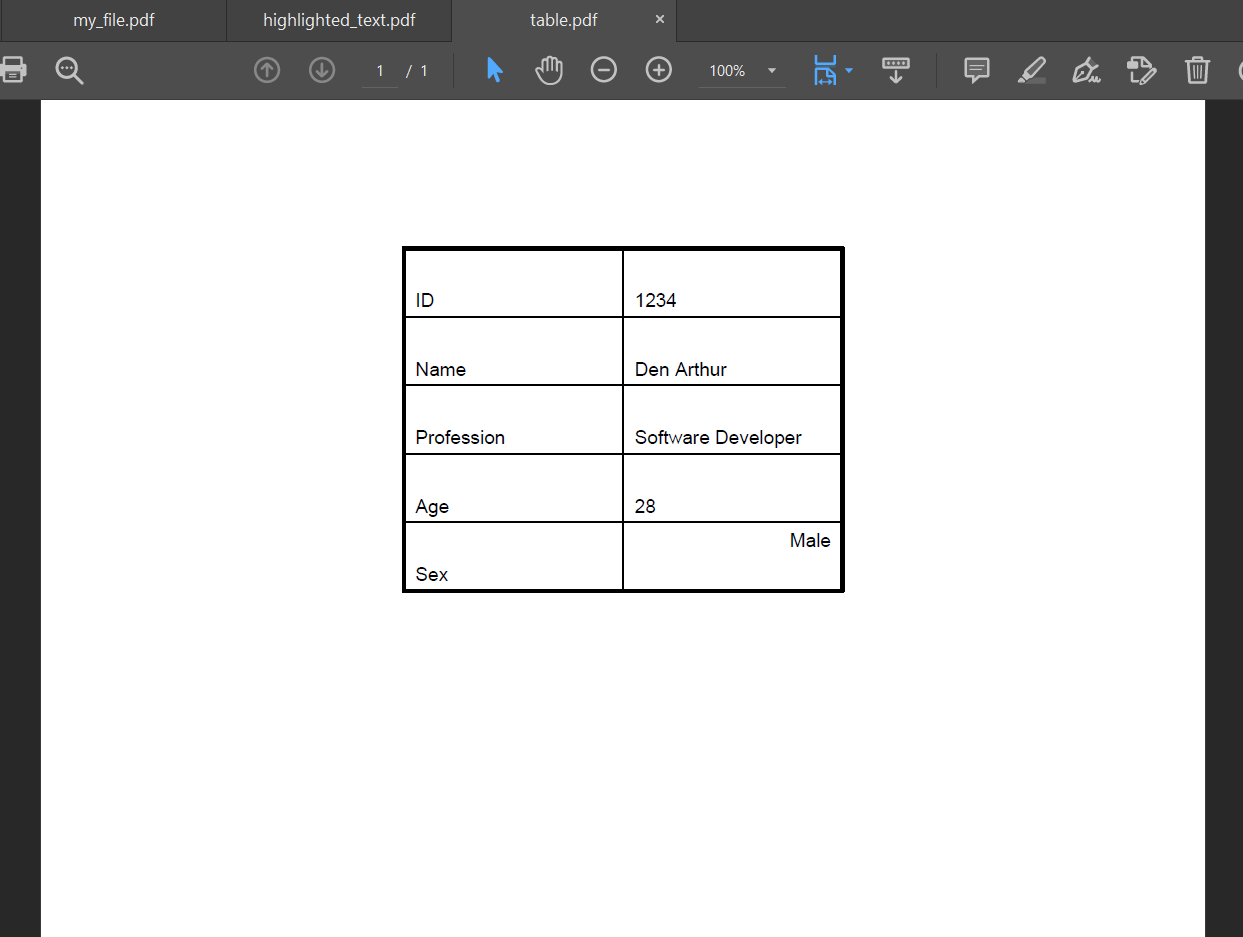
Explanation: In the above snippet of code, we have created a new PDF file with letter size. The data to be stored on the table is provided on the list "my_data". Here, the list's shape is 5x2. There are five rows and two columns. Thus, this is the table that will be formed on the PDF file. After that, we defined the table's margin, the grid lines, their sizes, and formations. We have also used the setStyle function. One can also refer to the official documentation of the reportlab library for creating a table. If these grid lines were not defined, there would be just the detail on the PDF in an arranged order; however, without being separated by grid lines or borders. Highlighting text on a PDF using PythonPython also offers us the feature order to highlight the text contents on a PDF file known as "fitz". Fitz is the simplest library that we can use to perform text highlighting on a PDF file. As we have already discussed the installation procedure for the fitz library, let's move directly on to the implementations of the fitz library in order to highlight the texts on a PDF. Example: Output: 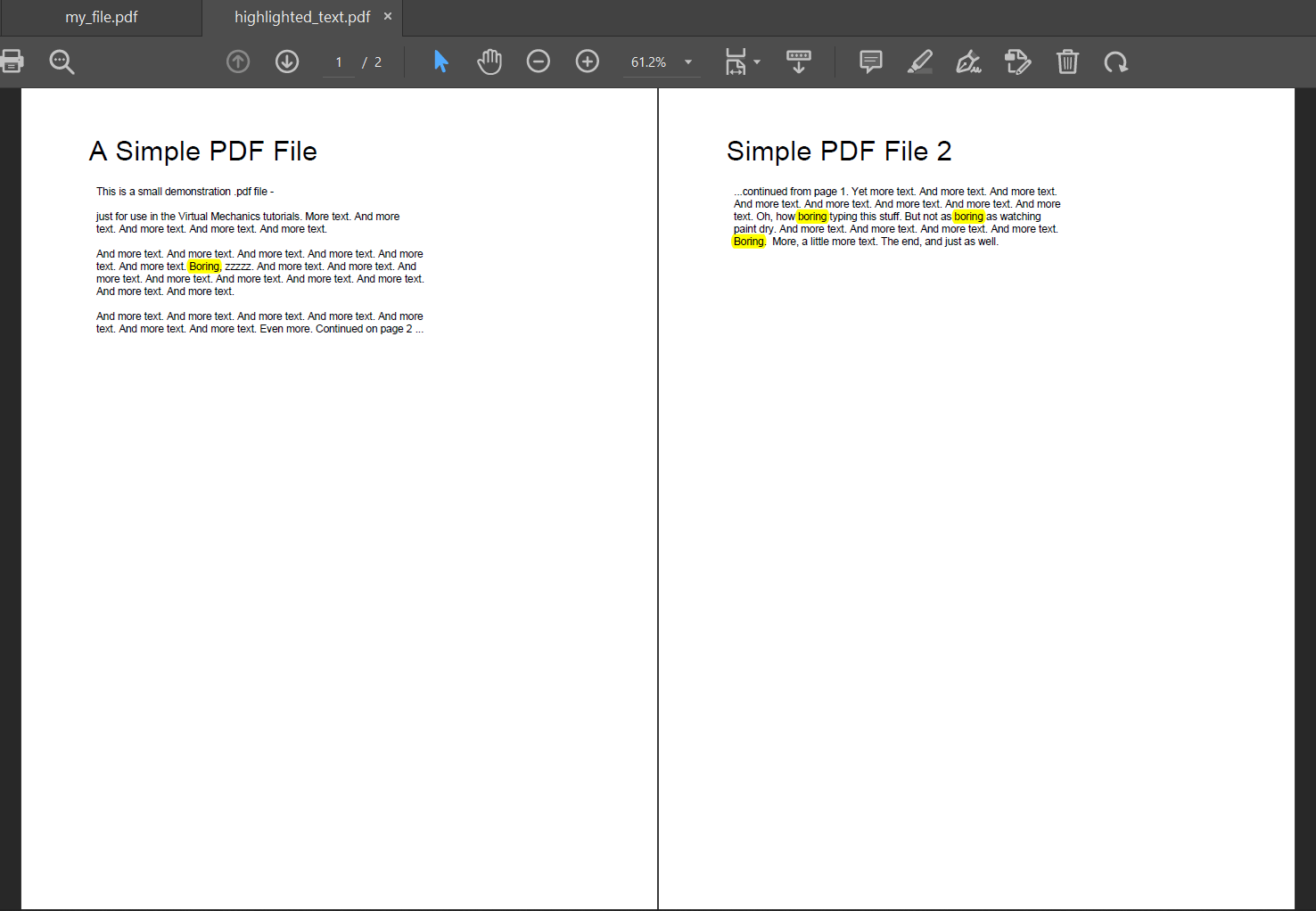
Explanation: In the above snippet of code, we have imported the fitz library. We have then used the open() function in order to load the PDF file my_file.pdf, which is to be highlighted. The phrase that is to be highlighted is given on the text variable. We are highlighting the word "Boring". We have then iterated through each of the pages to find if there are any potential matches to the word. If we find a match to the word, we have used the add_highlight_annot function from fitz in order to highlight them. Thus, in this manner, we have obtained highlighted text on a PDF file. Resizing pages of a PDF using PythonResizing a Page is another example of manipulating a PDF file using Python. Sometimes, resizing might be necessary on PDF pages, and Python offers a library known as PyPDF2, using which programmers can perform the function of page resizing. Let us consider the following example to understand the same: Example: Output: 
Explanation: In the above snippet of code, we have imported the required library. We have then begun by reading the input PDF file that has to be resized. Then, we have read its pages. Here, we have resized the first page only, so the getPage function is provided the value 0, which stands for the initial page. Now, in order to resize the page, we have used the scaleBy function and scaled the 0th page by 0.5. Thus, the first page is reduced by half the actual dimension of the page. We have then saved the page onto a new PDF file resizedFile.pdf. In this manner, we have successfully performed the page resizing using Python. Converting a PDF file into CSV using PythonSometimes, tabular data is also present in a PDF format. However, these types of information cannot be parsed directly. For instance, we cannot process a PDF file with a data frame directly using the pandas library, and they have to be converted into a CSV or Excel format before processing. Since this is quite a significant process, we will understand how we can convert a PDF file into a CSV format. Let us begin by installing the Python library called tabula Installing the tabula libraryWe can install the tabula library using the following command with the pip installer: Syntax: Now, let us understand the implementation of the tabula library in the conversion of a PDF file into CSV format with the help of the following example: Example: Explanation: In the following snippet of code, we have imported the tabula library. We have then used a one-line function called "convert_into", specifying the parameters as the path to the input PDF file, the path to which the file has to be converted, the format of the Output file, and the number of pages we wanted to convert. In this manner, we can convert a PDF file into a CSV format easily and effectively. There are many other functions that we can perform with a PDF file using a programming language like Python. One can also refer to the official documentation for reference.
Next TopicList All Functions from a Python Module3
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








