| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

YOLO : You Only Look Once - Real Time Object DetectionObject DetectionIt is a computer vision task of classifying and identifying objects in videos or images. This object detection algorithm can be divided into two types mainly. They are:
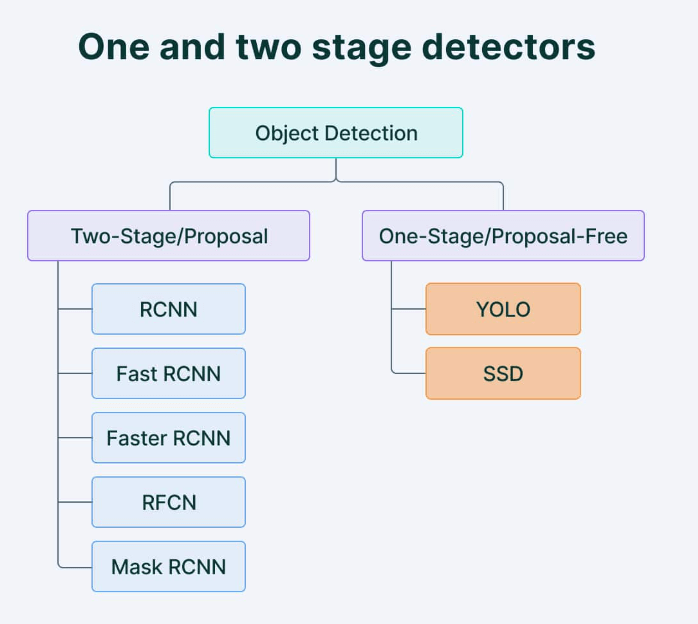
Single-shot detectorsYou Look only once in a single shot detector which uses full CNN to process an image. In this, it uses a single pass for making predictions and identifying the location of an object, and it is less accurate when compared to other methods. Two-shot detectorTwo-shot detector uses two passes of an input image, and predictions are made about the presence and location of objects. This has more accuracy. Mostly single shot detectors are used for real-time applications when accuracy is considered; two shot is used. What is YOLO?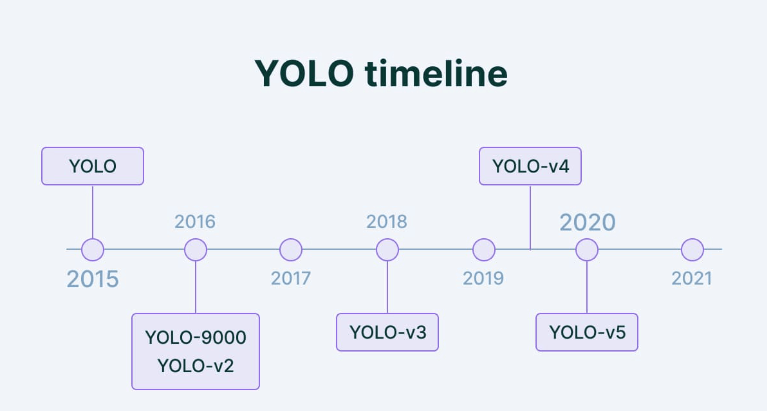
YOLO is a convolutional neural network (CNN) algorithm for object detection. Unlike other object detection algorithms, YOLO does not require region proposals or multiple stages. Instead, it divides the input image into a grid and predicts bounding boxes and class probabilities for each grid cell. This makes it faster and more efficient than other object detection algorithms. It uses a single-stage approach to predict bounding boxes and class probabilities for objects in an input image. YOLO V2:It was introduced in the year 2016, and it is an update of the YOLO algorithm. It is also known as YOLO9000 and is designed to work faster and be more accurate. Using anchor boxes is one of the primary upgrades in YOLO v2. An assortment of bounding boxes with varying aspect ratios and scales are called "anchor boxes." YOLO v2 predicts bounding boxes by combining the anchor boxes and anticipated offsets to create the final bounding box. As a result, the algorithm can handle a larger range of item sizes and aspect ratios. The introduction of batch normalization, which helps to increase the model's accuracy and stability, is another development in YOLO v2. Another technique, YOLO v2, is multi-scale training, which entails training the model on photos at various scales and averaging the predictions. This enhances the effectiveness of small object detection. Below are the findings that YOLO v2 produced when compared to the original model and other modern models. 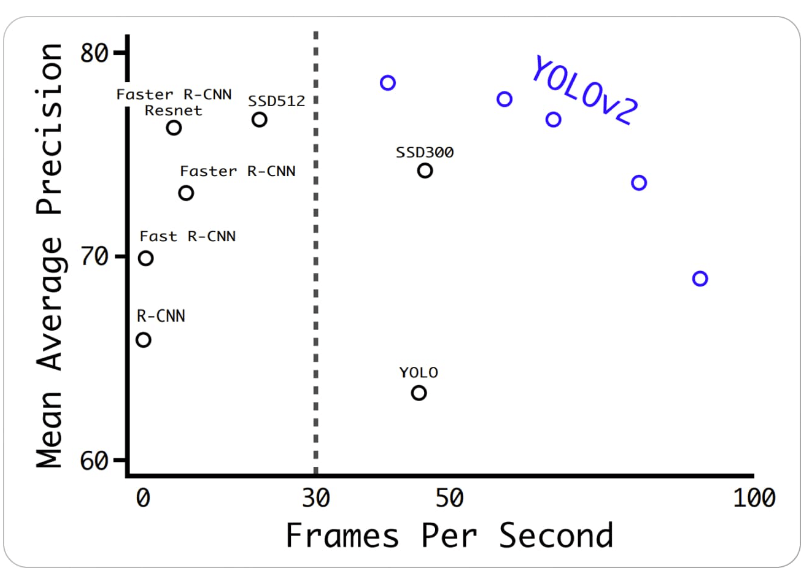
YOLO V3:It is an upgrade of YOLO V2 introduced in 2018 aims to increase the speed and accuracy of the algorithm. It uses new Convolutional Neural Network architecture known as Darknet - 53. Anchor boxes with various scales and aspect ratios add to YOLO v3. Because the anchor boxes in YOLO v2 were all the same size, the algorithm had trouble detecting objects of various sizes and forms. To better match the size and shape of the detected objects, YOLO v3 changes the aspect ratios and scales the anchor boxes. 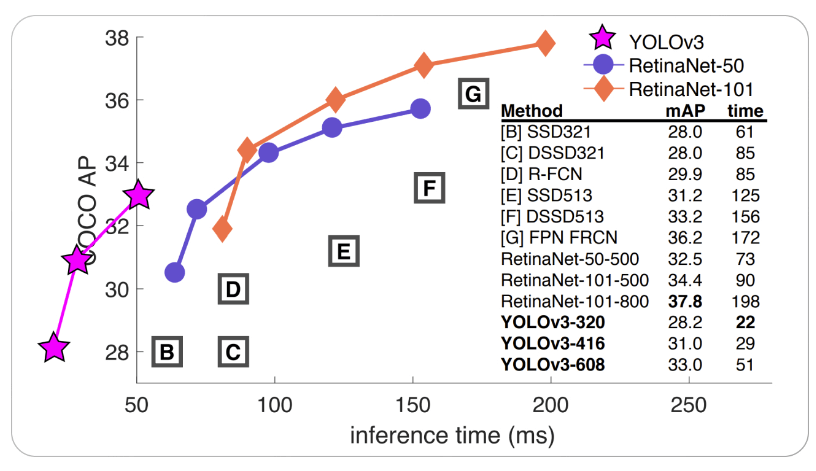
YOLO V4:It is the fourth version of YOLO and was proposed by Bochkovskiy et al. in 2020. Using a new CNN architecture called CSPNet (shown below) is the major advancement in YOLO v4 over YOLO v3. The acronym "Cross Stage Partial Network" refers to a ResNet variation created especially for object detection tasks. With only 54 convolutional layers, it has a fairly shallow structure. On several object detection benchmarks, though, it can produce state-of-the-art results. 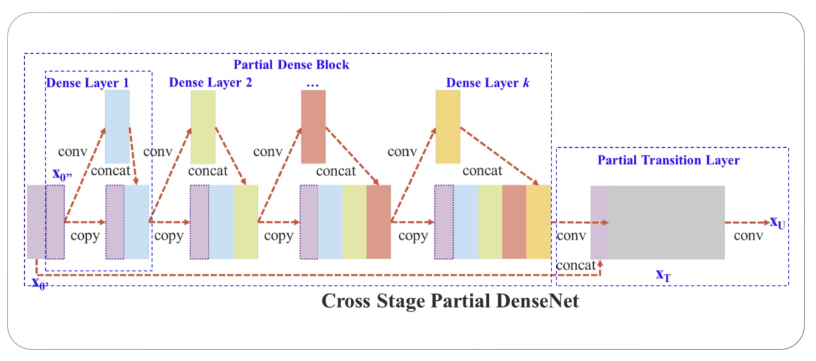
Both use anchor boxes but with different scales to better match the size and shape of an object detected, and "k means clustering" is introduced by YOLO V4, and both uses similar loss function, and YOLO V4 proposed a new loss function called "GHM loss." YOLO V5:It was built by the same team which developed the YOLO algorithm. This is built upon the success of previous versions with extra updated features. Like YOLO, YOLOV5 uses EfficientDet architecture which is more complex based on EfficientNet because it obtains more accuracy. YOLO V4 and YOLO V5 use similar loss functions; however, YOLO V5 introduced "CIoU loss," to improve model performance. 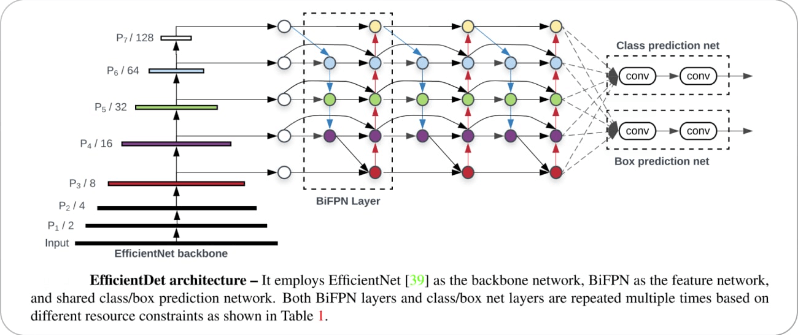
YOLO V6:YOLO V6 is introduced in the year 2022 by Li et al.as YOLO VS uses EfficientDet architecture. YOLO V6 uses EfficientNet-L2. This is the only difference between YOLO V5 and YOLO V6. 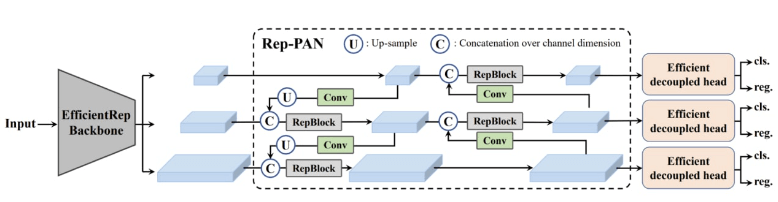
YOLO V7:The most recent version of YOLO, version 7, has several enhancements over earlier iterations. The usage of anchor boxes is one of the key advancements. To identify objects of various shapes, anchor boxes are a collection of preconfigured boxes with various aspect ratios. With nine anchor boxes, YOLO v7 can detect a larger variety of item forms and sizes than earlier iterations, which helps to lessen the number of false positives. Implementing a new loss function termed "focal loss" in YOLO v7 is a significant improvement. The standard cross-entropy loss function, known to be less successful at identifying small objects, was utilized in earlier iterations of YOLO. Focal loss addresses this problem by down-weighting the loss for well-classified cases and emphasizing the difficult-to-detect examples. Additionally, YOLO v7 has a greater resolution than earlier iterations. Compared to YOLO v3, which processed photographs at a resolution of 416 by 416 pixels, it processes images at a level of 608 by 608 pixels. YOLO v7 can detect tiny objects with greater precision thanks to its better resolution. Advantages of YOLOV7:
YOLO V8:Ultralytics has confirmed the launch of YOLO v8, which promises additional features and enhanced performance over its predecessors. The new API in YOLO v8 simplifies training and inference on CPU and GPU devices while the framework still supports earlier YOLO iterations. The developers are still working on a scientific publication that will provide a thorough explanation of the model design and performance.
Next TopicRetail Cost Optimization using Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








