| |

Python lxml ModuleWe all must have heard of web scrapping and how information is scrapped from websites using web scrapping. Web scrapping is very important because it helps us to get all the useful information from a webpage or website, and we can get whatever information we want from that webpage. Now, many of us would think about why it is important that we first fetch information from the webpage and why don't we directly visit the webpage to look at the information? There are two main purposes behind using the web scrapping process, which is following:
These are two important reasons why web scraping is important and why we have to use web scraping. Now, when we understand how much web scrapping is important in saving time and fetching all the useful information, we all want to learn how to use web scraping. There are multiple methods through which we can implement and use the web scrapping process, and multiple methods to implement the web scraping process is also available in Python. Python provides us with multiple modules, and using these modules; we can implement web scrapping using a Python program. One of such Python modules is the lxml module, and it provides multiple functions' library through which web scrapping can be implemented. We are going to learn Python lxml module in this tutorial and learn how we can implement web scrapping with this module. Note: We should note that while performing web scrapping on any webpage or web link, we have to take prior permission from some websites to do so; otherwise, it would be considered illegal. One more thing we should keep in mind while implementing web scrapping is that sending multiple web scrapping requests to a single website may result in blocking from that site.lxml Module in Pythonlxml module of Python is an XML toolkit that is basically a Pythonic binding of the following two C libraries: libxlst and libxml2. lxml module is a very unique and special module of Python as it offers a combination of XML features and speed. In the lxml module, we are provided with multiple functions and using these functions in a Python program; we can easily perform the web scrapping and curate all the useful information from any web page. lxml module of Python also allows us to easily handle all the HTML and XML files along with its application in the web scraping process. Following are the functions that can be performed by using the lxml module in a Python program:
In this tutorial, we are only going to learn about the lxml module's implementation in web scrapping and how we can use the functions of this module to perform web scraping. lxml Module in Python: Installationlxml module of Python is not an in-built Python library, and that's why if we have to use this module to implement web scraping using a Python program, then first we should make sure that the lxml module is installed in our system or not. And, if the lxml module is not installed in our system, then first we have to install this module and only after that we can proceed with the web scrapping implementation of this module. We have multiple installation methods available for installing the lxml module, and we can use any of these methods according to our choice, but in this section, we will only use the pip installer method for the installation of the lxml module. In the pip installation method, first, we have to open the cmd prompt terminal of our device, and then we have to write the following pip command in the terminal: After writing the command given above in the terminal, we have to press the enter key to initiate the installation process. Once we press the enter key, the installation process for the lxml module will start, and it will take a while to install this module successfully. 
As we can see, the lxml module is successfully installed in the system, and now we can import this module into our Python program to implement the web scraping process with the help of its functions. Note: Before we proceed with the implementation part of web scrapping with the lxml module, we should note that we need one more Python module while performing web scrapping with the lxml module. We need to have the Python requests module installed in our system along with the lxml module if we want to perform web scraping using the lxml module. This is because the request module of Python will make requests with the websites or web pages on which we want to perform the web scraping. The requests module of Python is also not an in-built module, and therefore, we should make sure that this module is also present in our system. If the request module is not installed in our system, then again, we can use the pip installer to install this module. We have to use the following command in the cmd terminal:And, after writing the command, we have to follow the process and wait for a while until the installation process of the request module is completed. 
We can see that Python Requests Module is successfully installed in our system, and now we can move ahead with the implementation part of web scrapping using the lxml module. lxml Module in Python: Implementation of Web ScrappingBefore we move further with the implementation part in this section, we should have to learn some things and only after that we can go ahead with the implementation of web scrapping. Steps for Implementing Web Scrapping through the lxml Module: We have to follow a stepwise procedure to implement and use the web scrapping and retrieve information from a webpage using this process. Following are the steps we have to follow while using the lxml module for implementing web scrapping:
These are the steps that we have to follow sequentially to retrieve the particular content from the webpage. We can implement web scrapping and retrieve content from any web link by following the steps given above. xpath for a Web Link:In steps 4 & 5 of implementing web scrapping, we can find the word 'xpath', which is very important for successfully implementing web scrapping. Now, many of us would ask what 'xpath' is and how we can get the xpath of a web link. We are going to answer both of these questions here in this section. xpath: xpath, which uses a non-XML syntax to provide a flexible way of addressing, stands for XML path language, and through xpath, we can point to different parts of the given xml document (or web page). xpath is used in web scrapping so that the program can address or uniquely identify parts of the web page which has to be retrieved. xpath is an important element in web scrapping because xpath is the only element in the program that specifies the content from the web link that has to be retrieved. Now, the second question, which is how we can get xpath for a given link and answer to this question is, we have to follow the steps given below to get xpath of a web link: Step 1: First, we have to visit the URL on which we want to perform web scraping, and then we have to right-click there, and a pop-up window with a list of options will open. The window that will open after right-clicking on the URL page will be something like the following: 
Step 2: We have to select the 'inspect' option from the list of options, and it will open a second on the same URL page where we can find the coding of the URL page with all its elements. Step 3: Now, we have to right-click again in this step, but now we have to right-click on the element window that opened after choosing the inspect option. When we right-click on the div elements, another pop-up window having list of options will open. The window that will open after right-clicking on the inspect page window elements will be something like the following: 
Step 4: In this step, we have to go to the copy option and there, we will see a lot of copy options there. The following list of options will appear when we go to the copy option from the list of options: 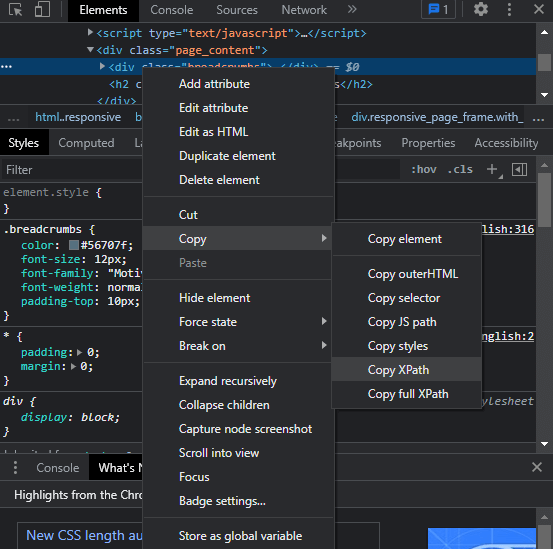
We have to select the 'complete xpath' option, and thus complete xpath of the URL will be copied, and we have to use this xpath in our program during the web scrapping. We should follow these steps while getting the xpath of the URL that we are using in the web scrapping, and we should note that xpath is an important element of the web scraping process. Implementation of Web Scrapping:When we are using the lxml module in a Python program to implement web scraping, we have to fix many things before executing the program, which is the following:
After deciding and fixing these things in the program, we can execute the program and implement web scrapping through the lxml module. In this section, we will use a custom URL and then perform the web scrapping on that custom URL, i.e., new releases, by getting its xpath first. We will get the following two important elements from the custom URL we are using in this tutorial:
We will use a Python program in each case, and through these programs, we will understand the implementation of the web scrapping process through the lxml module. Implementation 1: Getting Price List using the Web Scrapping with lxml Module: This implementation method will get the price list from the custom URL in the output using the lxml & requests module's functions. We will use the following example program to get a price list from new releases in this implementation. Example 1: Output: The price list from the URL of new releases: 
As we can see, the price list from the 'new releases' URL is successfully Printed in the output, and we can even save this list for further use. Explanation: We have imported the html library from the lxml module and requests module in the program to use their functions to implement web scrapping. After that, we have initialized a URL variable and provided the new releases URL (on which we will be performing web scrapping) in this variable. Then, we used the get() function of the requests module with the URL variable to get data from the URL by sending requests. We have used the get() method inside the getHtml variable, and then we used the fromstring() method on this variable to get the URL's content in the program. We have used the fromstring() in the initialized variable, i.e., docContent(), and used this variable further with the xpath variables. We defined the complete xpath of the URL in the initialized 'xpathComplete' variable using the xpath() function of the lxml module. After that, we defined the xpath for the prices again with the help of the xpath() function in the 'xpathPrices' variable. Lastly, we printed the list of prices in the output using the 'xpathPrices' variable in the print statement, and the program will retrieve the prices list from the web page through web scrapping. Implementation 2: Getting Title List from the URL using lxml Module: We will get the price list from the custom URL in the output in this implementation method with the help of web scrapping implemented through lxml and requests module. We will use the following example program in this implementation part for getting the title list from new releases. Example 2: Output: The title list from the URL of new releases: 
As we can see, the title list from the 'new releases' URL is successfully Printed in the output, and we can even save this list for further use.
Next TopicPython MayaVi Module
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








