| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

How to Create an Animation of the Embeddings During Fine-Tuning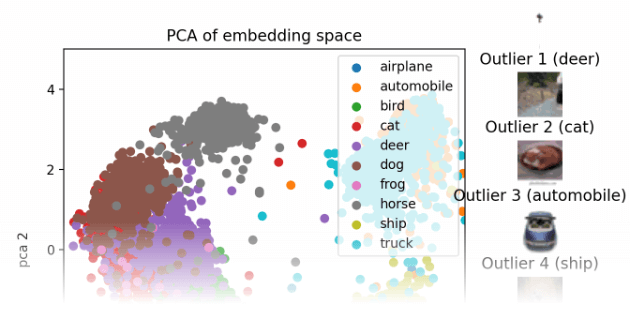

There were more than 200,000 impressions of the activity. Numerous perusers communicated interest in how it was made and energetically gotten. This exposition is intended to help those perusers and anyone keen on making representations equivalent to them. The objective of this post is to offer a careful instructional exercise on the best way to make such a liveliness, including every one of the important cycles, including calibrating, installing age, exception recognizable proof, PCA, Procrustes, survey, and movement creation. Preparation: Fine-tuningPre-prepared Vision Transformer (ViT) model. For this, we use the CIFAR-10 dataset, which comprises 60,000 photographs partitioned into ten classifications: trucks, frogs, ponies, deer, felines, birds, and vehicles. To complete the calibrating methodology for CIFAR-10, adhere to the directions given in the Embracing Face illustration for picture grouping with transformers. We likewise utilize a TrainerCallback to record the misfortune values during preparation into a CSV document for use in liveliness. To ensure an adequate number of designated spots for liveliness, it's basic to build the save stretch for designated spots by setting save_strategy="step" and a low number for save_step in TrainingArguments. The movement's approaches each address an alternate designated spot. An organizer is laid out for every designated spot during preparation, and the CSV record is likewise ready and prepared for utilization. Embeddings CreationTo create embeddings from the test split of the CIFAR-10 dataset using various model checkpoints, we utilize the Transformers library's AutoFeatureExtractor and AutoModel functions. Each embedding represents one of the 10,000 test pictures for a single model checkpoint as a 768-dimensional vector. These embeddings can be kept in the same folder as the checkpoints to keep track of everything. Extracting OutliersThe Cleanlab library's OutOfDistribution class may be used to find outliers based on the embeddings for each checkpoint. The top 10 outliers for the animation may then be determined using the resultant scores. Using Procrustes Analysis and PCAWe visualize the embeddings in a 2D space using a Principal Component Analysis (PCA) using the scikit-learn package, which reduces the 768-dimensional vectors to 2 dimensions. Large leaps in the animation might happen when PCA is recalculated for each timestep due to axis flips or rotations. We use an extra Procrustes Analysis [3] from the SciPy package to geometrically shift every frame onto the previous frame to solve this problem. This analysis just requires translation, rotation, and uniform scaling. This makes the animation's transitions more fluid. Review in SpotlightBefore applying the finishing touches, we assess the entire animation in Spotlight. This process's first and last checkpoints are used to create embeddings, perform PCA, and identify outliers. Spotlight is launched, and the produced DataFrame is loaded. Spotlight provides a comprehensive table with a list of all the fields in the dataset in the top left corner of the screen. In the top right corner are two PCA representations, one for the embeddings made using the first checkpoint and the other for the last checkpoint. The bottom section is a showcase of chosen photographs. 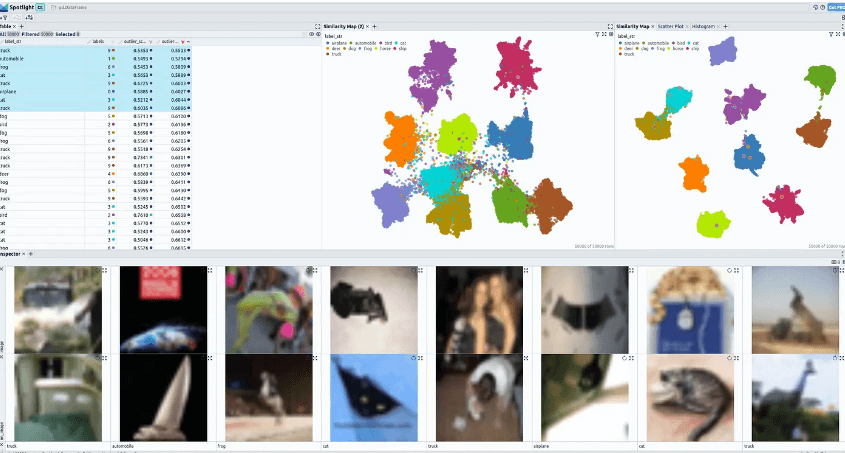
Create the animationEach checkpoint receives its image, which is then saved with the appropriate checkpoint. This is accomplished using the make_pca(...) and get_ood(...) functions, which generate the 2D points that constitute the embedding and extract the top 8 outliers, respectively. The various classes are represented by the colours used to lay out the 2D points. According to their score, the outliers are organized, and the high score scoreboard shows images of the pertinent outliers. The training loss is imported from a CSV file and shown as a line graph. After that, all the images might be combined into a GIF using libraries like Imageio or others. 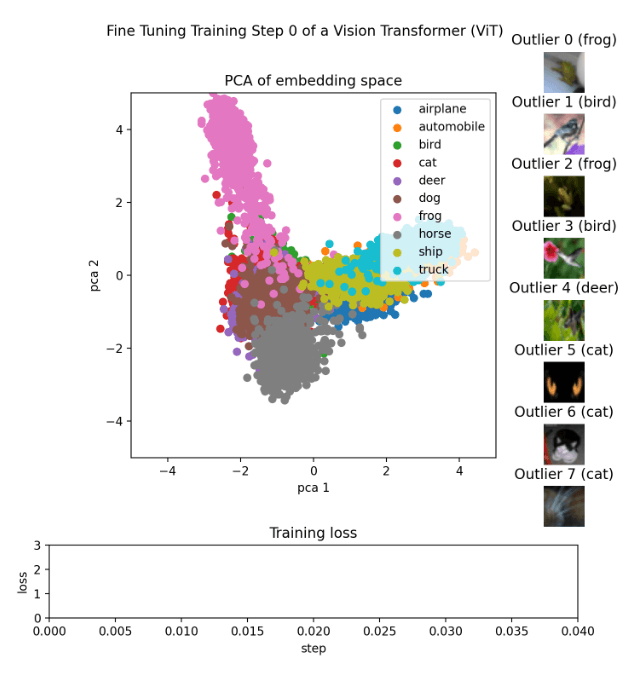
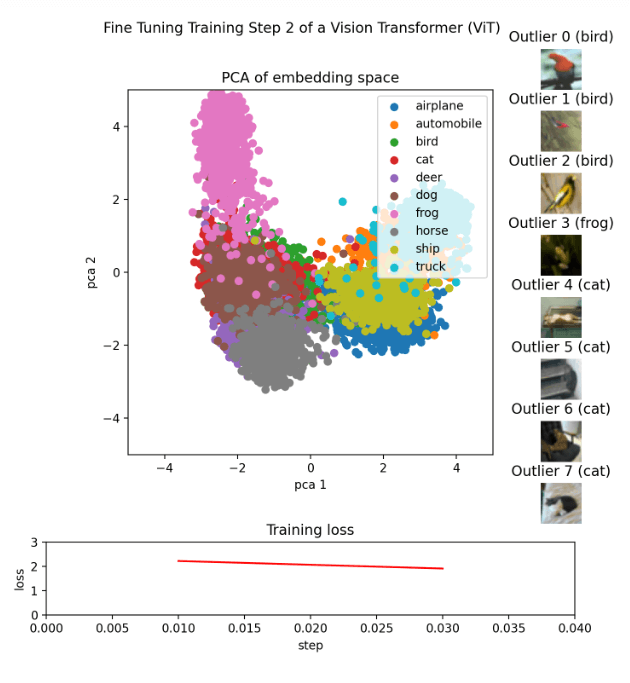
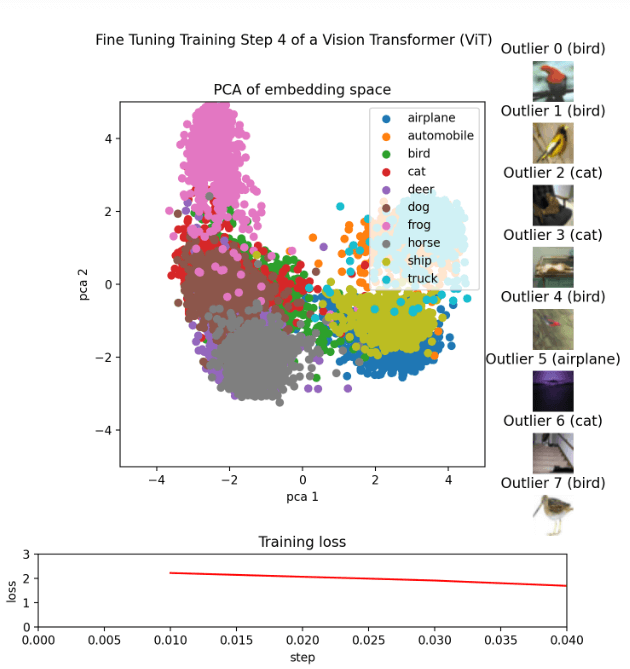
Conclusion:An extensive lesson on how to create an animation that demonstrates the process of fine-tuning a Vision Transformer (ViT) model is provided in this article. The steps for creating and analyzing embeddings, visualizing the results, and creating an animation that integrates these components have all been covered. Making such an animation is a powerful approach to teach these concepts to others and to help others understand the complex procedure of modifying a ViT model. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








